
PostgreSQL自真空导致性能显著下降
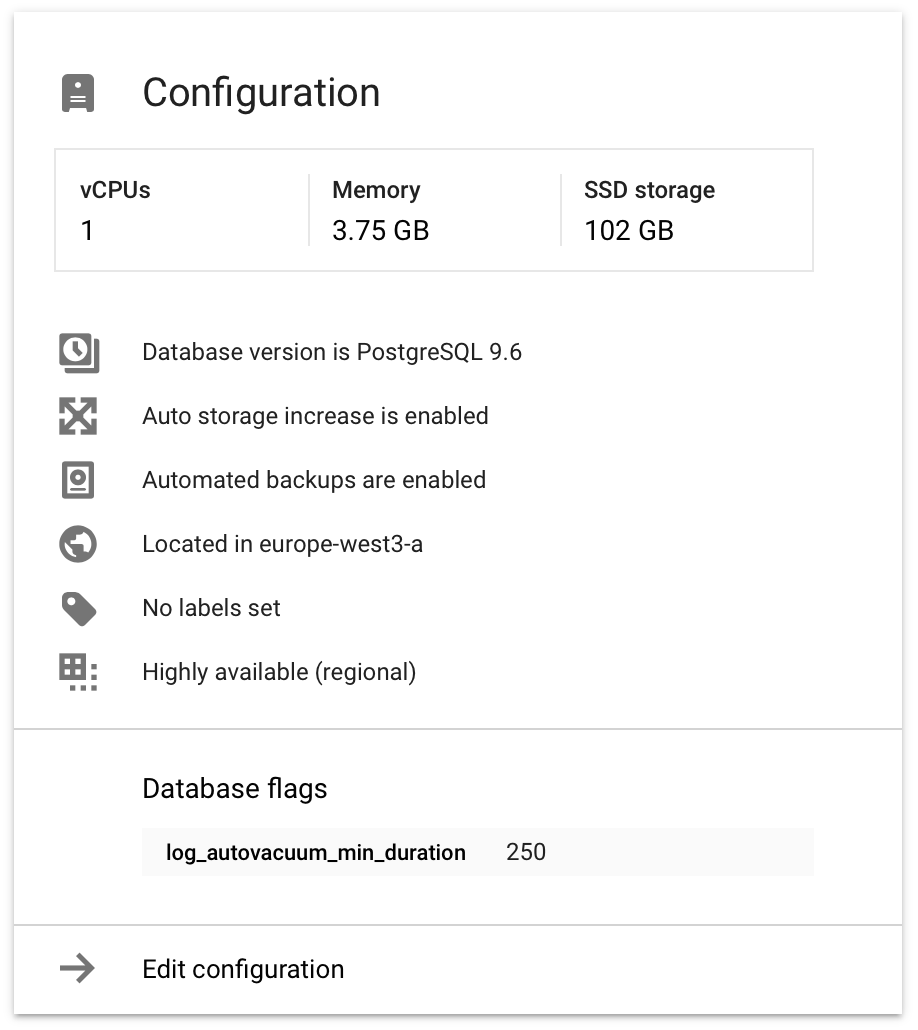
我们的Postgres (托管在上,有1CPU,3.7GB RAM,见下文),主要由一个大~90 GB的表组成,大约有6,000万行。使用模式几乎完全由附加和几个索引读取表的末尾。偶尔会有几个用户被删除,删除分散在表中的一小部分行。
这一切都很好,但每隔几个月就会在该表上触发一次自动真空,这对我们服务的性能影响很大,持续了大约8个小时:
- 在自动真空期间(几个小时),存储使用量增加了~1GB,然后慢慢返回到以前的值(由于自动真空释放页面,可能最终会降到低于此值)。
- 数据库CPU利用率从<10%跃升到~20%
- 磁盘读/写操作从接近零增加到~50/秒
- 数据库内存略有增加,但保持在2GB以下。
- 事务/秒和入口/出口字节也不受预期的影响。
这会使我们的服务的第95个延迟百分位数在自动真空期间从~100‘s增加到~0.5~1s,从而触发我们的监视。该服务每秒提供大约10个请求,每个请求由几个简单的DB读/写组成,每个请求的延迟通常为2-3 3ms。
下面是一些监控屏幕截图,说明了这个问题:
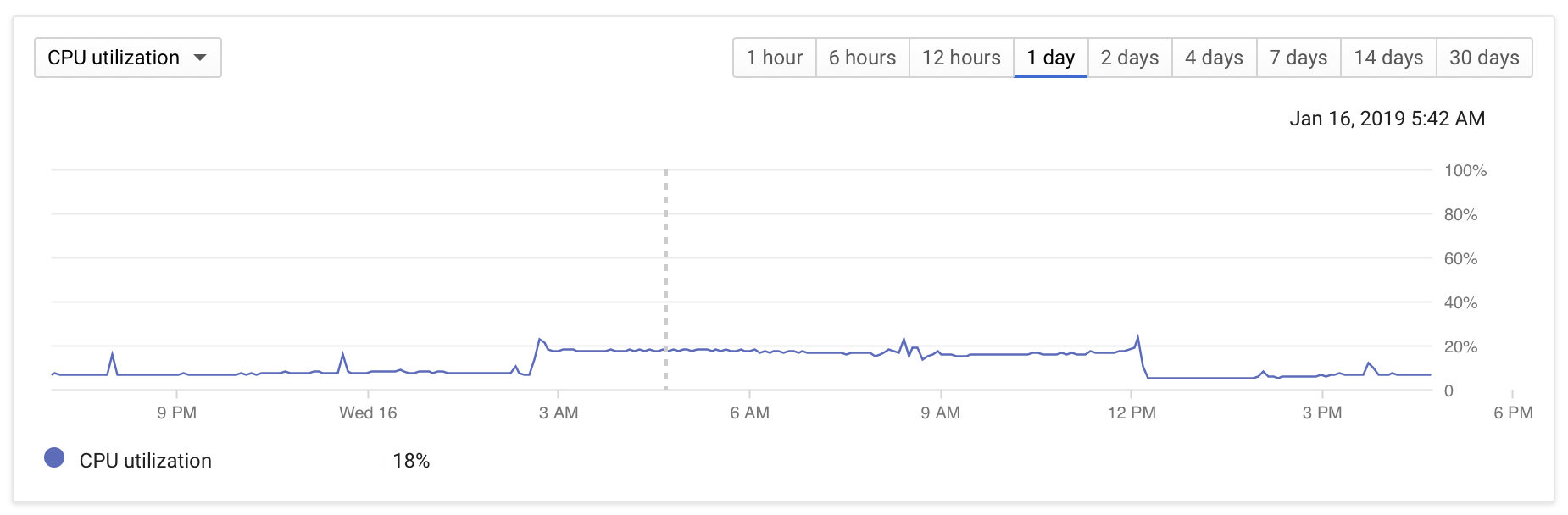
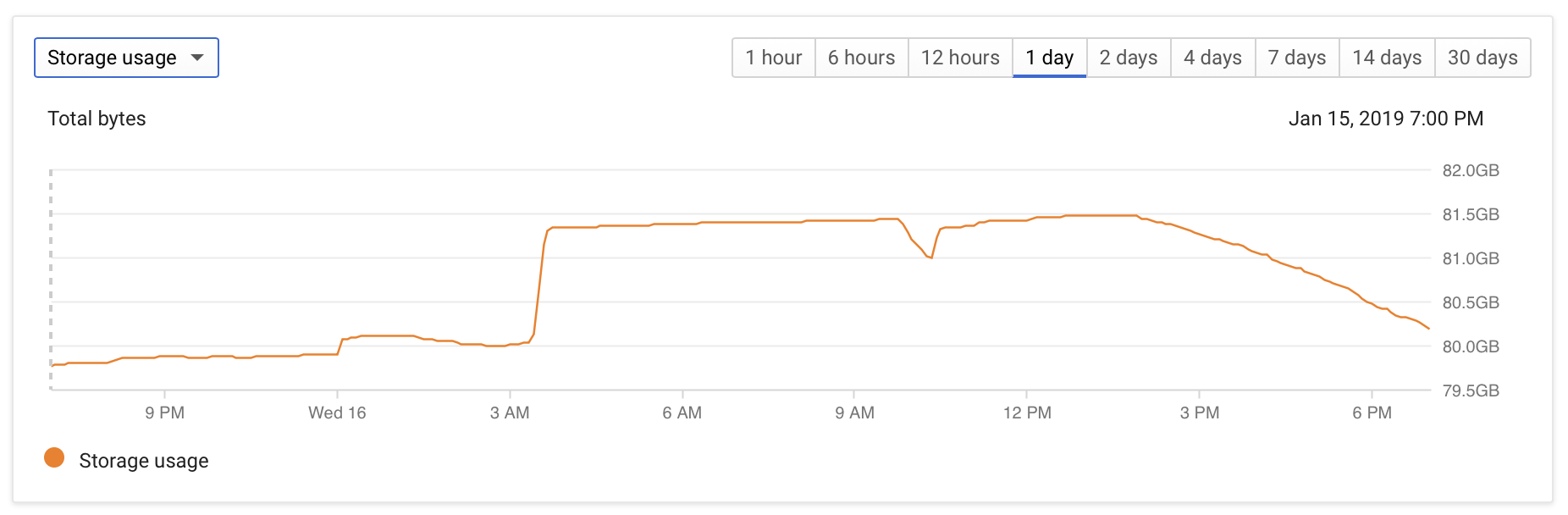
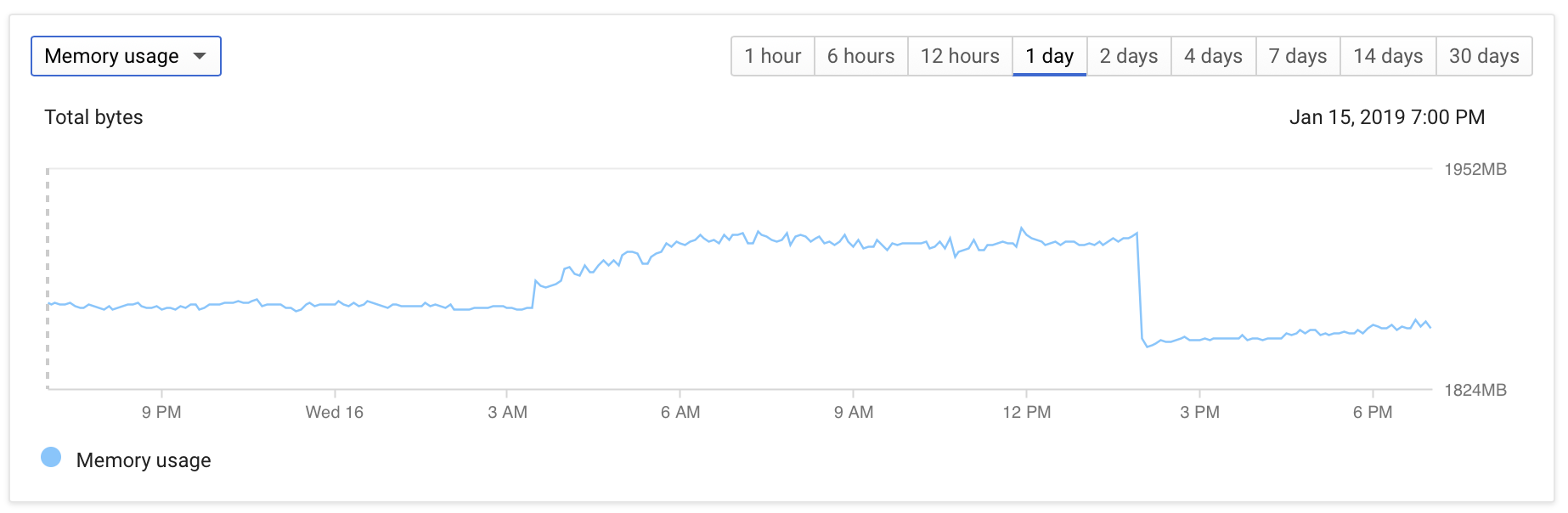
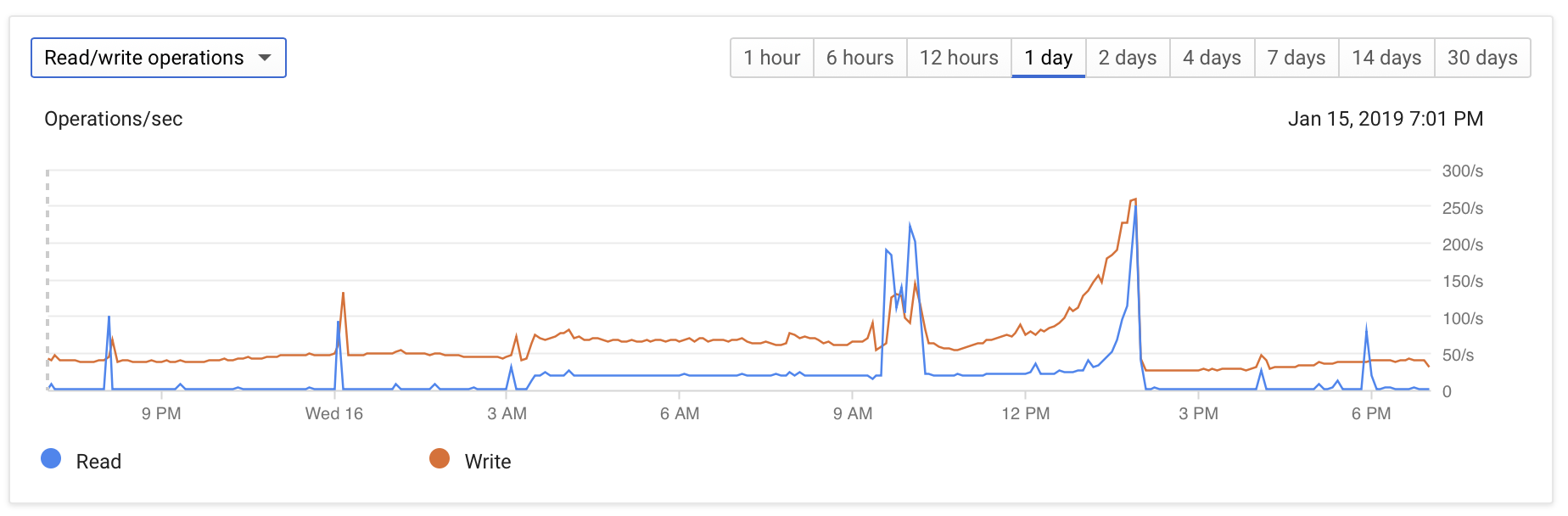
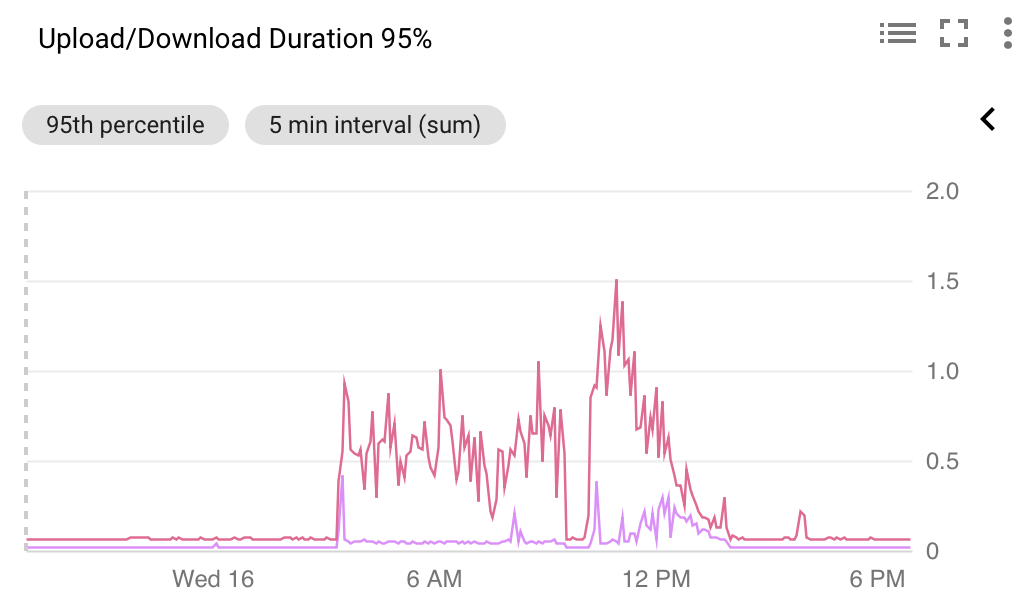
DB配置相当普通:
记录此自动真空过程的日志条目如下:
system usage: CPU 470.10s/358.74u sec elapsed 38004.58 sec
avg read rate: 2.491 MB/s, avg write rate: 2.247 MB/s
buffer usage: 8480213 hits, 12117505 misses, 10930449 dirtied
tuples: 5959839 removed, 57732135 remain, 4574 are dead but not yet removable
pages: 0 removed, 6482261 remain, 0 skipped due to pins, 0 skipped frozen
automatic vacuum of table "XXX": index scans: 1有什么建议,我们可以调整,以减少未来的自动真空对我们的服务的影响?还是我们做错了什么?
回答 1
Stack Overflow用户
发布于 2019-02-22 16:34:15
如果你能增加autovacuum_vacuum_cost_delay,你的自动真空会运行得更慢,侵入性更小。
但是,通过将autovacuum_vacuum_cost_limit设置为2000左右,使其更快通常是最好的解决方案。那它就完成得更快。
您也可以尝试自己安排表的VACUUM,当它伤害最少的时候。
但坦率地说,如果一个无害的自动真空足以干扰您的操作,您需要更多的I/O带宽。
https://stackoverflow.com/questions/54831212
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号