
合并不存在的节点并返回Neo4j中的源节点
我在我的小应用程序中使用neo4j作为我的数据库。我的申请是关于管理候选人的简历(简历)。
这是我的图表:
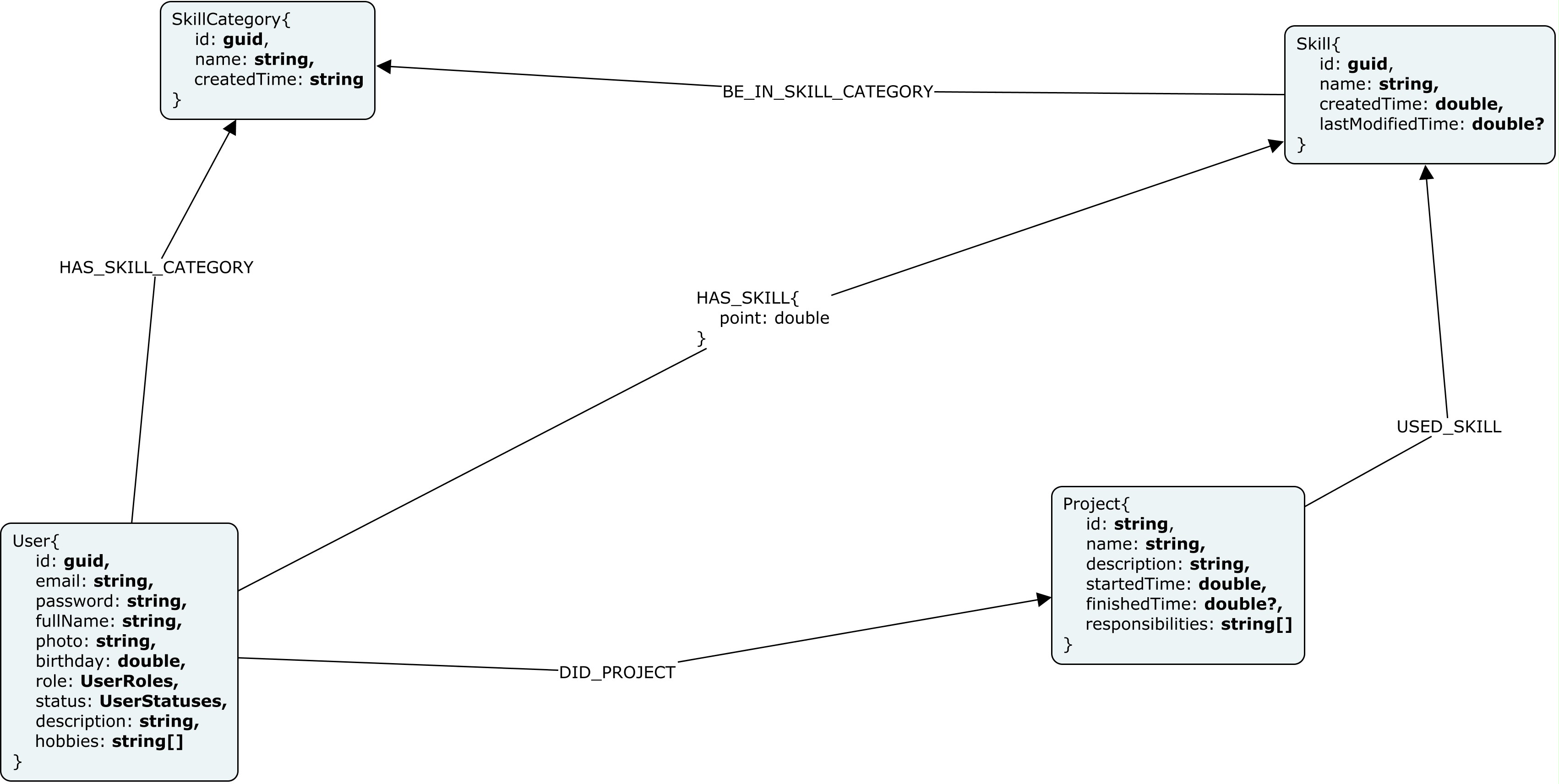
现在,我要做的是添加一个项目,并列出项目使用的技能。
这是我的neo4j查询:
MATCH (user: User)
WHERE (user.Id = "74994fd8-40bb-48e8-adf1-bc11eeb6c035")
WITH user
MERGE (project: Project {Id: '02d5ad72-036c-47e9-a366-d5ca4a3e66e2'})
ON CREATE
SET project = {
Id: "02d5ad72-036c-47e9-a366-d5ca4a3e66e2",
Name: "VINCI GTR",
Description: "Description of VINCI GTR",
StartedTime: 0.0
}
MERGE (user)-[:DID_PROJECT]->(project)
WITH project, user
MATCH (user)-[:HAS_SKILL]->(skill: Skill)
WHERE skill.Id IN []
MERGE (project)-[:USED_SKILL]->(skill)
RETURN project在我的查询中,我使用:WHERE skill.Id IN []来确保我的技能列表是空的,因为我想模拟一个没有技能可用的情况。
运行该命令时,即使是在数据库中创建的项目,也无法接收新创建的项目。相反,我有这样的结果:
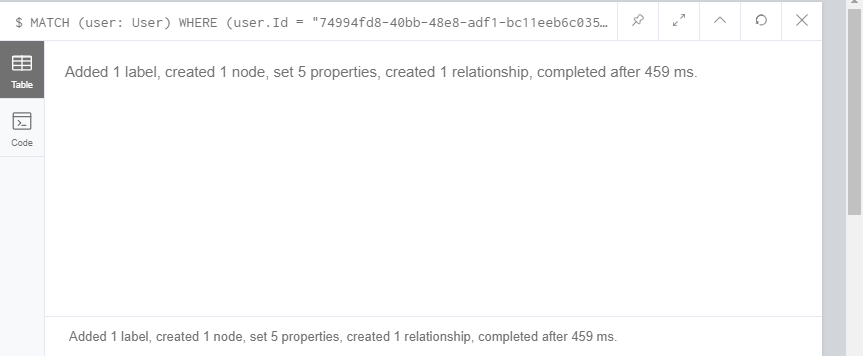
我如何才能:
- 当技能可用时,创建用户和技能之间的关系,并且-
- 如果没有技能可用,请跳过此操作。
- 返回新创建的
Project实例?
谢谢
回答 1
Stack Overflow用户
发布于 2019-02-23 02:19:12
无法匹配的MATCH子句将中止查询的其余部分(查询将不返回任何内容)。
以下代码段将永远不会匹配任何内容,因为它试图匹配具有相关user节点的skill节点,该节点的Id值与不存在的值匹配(这没有任何意义):
MATCH (user)-[:HAS_SKILL]->(skill: Skill)
WHERE skill.Id IN []要仅在USED_SKILL没有技能的情况下创建user关系,请执行以下操作:
MATCH (user: User)
WHERE user.Id = "74994fd8-40bb-48e8-adf1-bc11eeb6c035"
MERGE (project: Project {Id: '02d5ad72-036c-47e9-a366-d5ca4a3e66e2'})
ON CREATE
SET project += {
Name: "VINCI GTR",
Description: "Description of VINCI GTR",
StartedTime: 0.0
}
MERGE (user)-[:DID_PROJECT]->(project)
WITH project, user
WHERE SIZE((user)-[:HAS_SKILL]->()) = 0
MERGE (project)-[:USED_SKILL]->(skill)
RETURN project该查询对每个user节点进行度检查,以查找那些没有HAS_SKILL关系的节点(我们故意从模式中的相反节点中省略:Skill标签,这是一种黑客攻击,目的是使Cypher计划器生成更有效的操作)。另外,我们使用SET +=而不是SET =,这样我们就不会替换所有的节点属性,从而避免了用相同的值覆盖Id值。
顺便问一下:
HAS_SKILL_CATEGORY关系似乎是多余的。如果用户的技能都可以通过HAS_SKILL关系获得,那么您就可以通过如下方式获得该用户的类别:
MATCH (user: User)-[:HAS_SKILL]->()-[:BE_IN_SKILL_CATEGORY]->(c)
WHERE user.Id = "74994fd8-40bb-48e8-adf1-bc11eeb6c035"
RETURN c;https://stackoverflow.com/questions/54819887
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号