
如何将多个csv文件(不同模式)加载到bigquery中
如何将多个csv文件(不同模式)加载到bigquery中
提问于 2019-02-12 14:44:58
我有6500个csv文件,有250个不同的模式,即这些文件来自F.D.I.C (美国银行监管机构)数据集。它们已经上传到谷歌的云存储桶中:
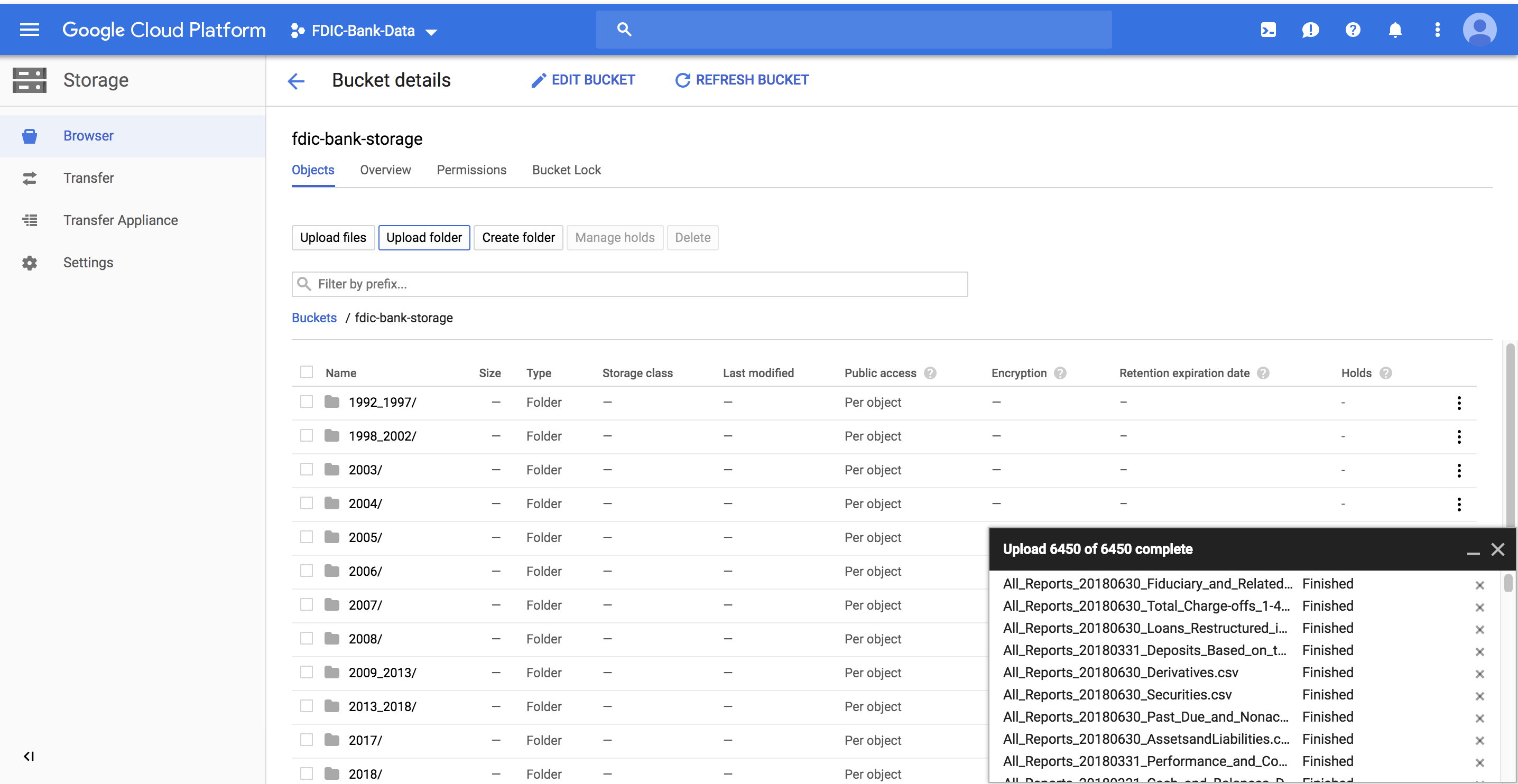
每个财政季度有250个不同的csv。每个csv在一个金融季度内有一个不同的模式:
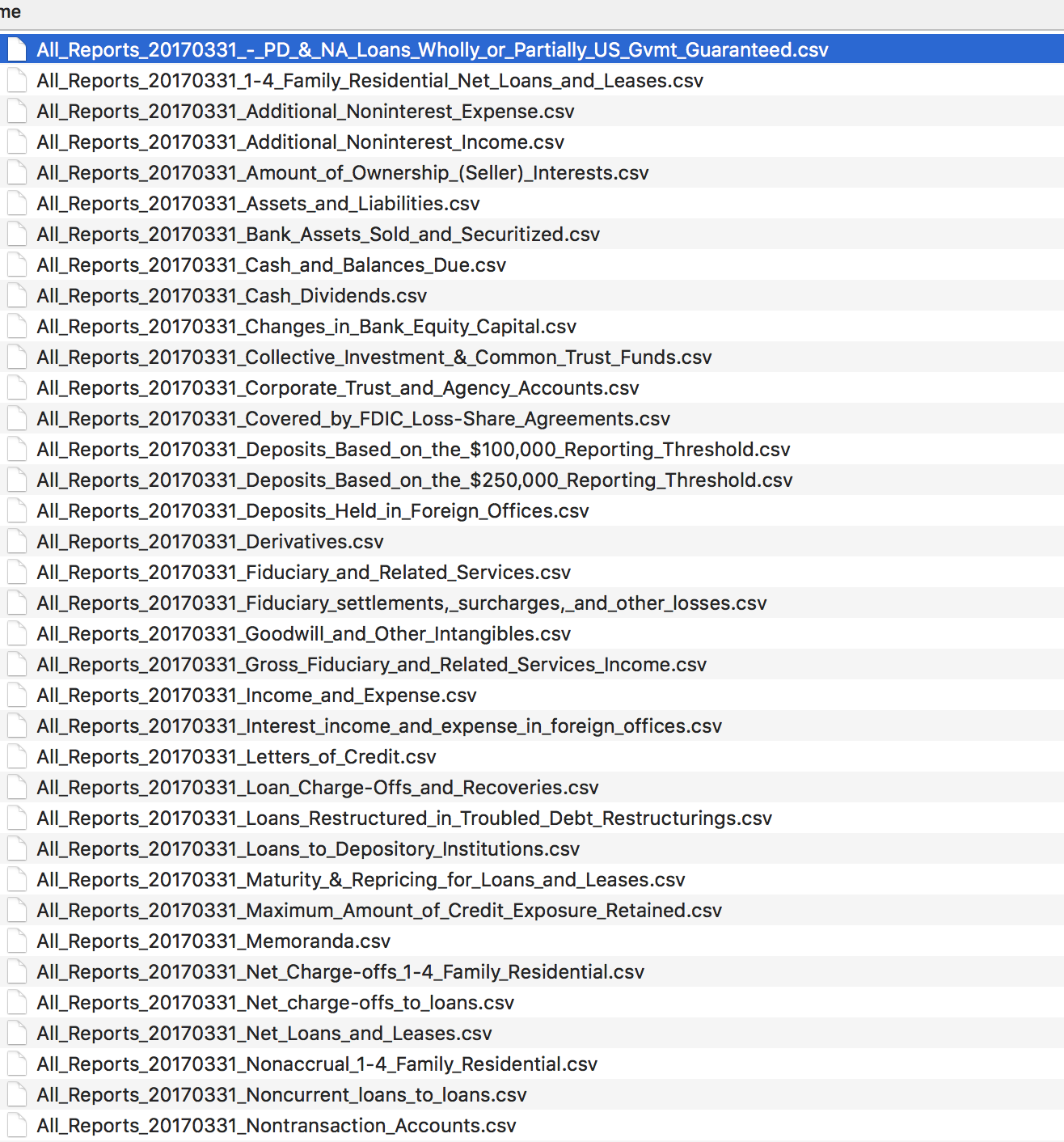
有250个独特的模式。模式在每个金融季度重复自己。csv的档案可以追溯到1992年的100个财政季度:
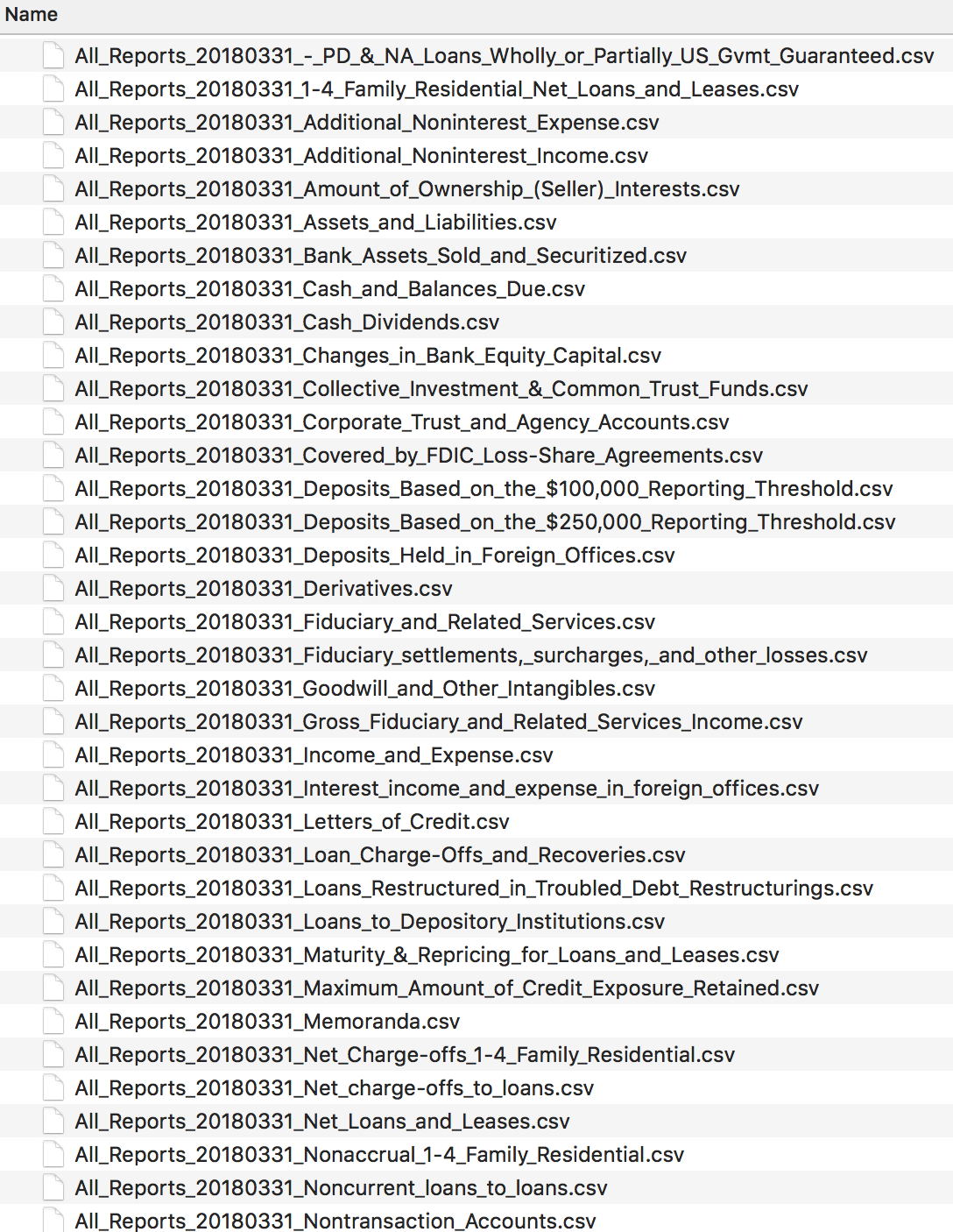
具有相同模式的多个CSV可以使用外卡上传。例如gs/path/*.csv。但是,每个表名都不是从文件名自动生成的。UI需要一个表名作为输入:
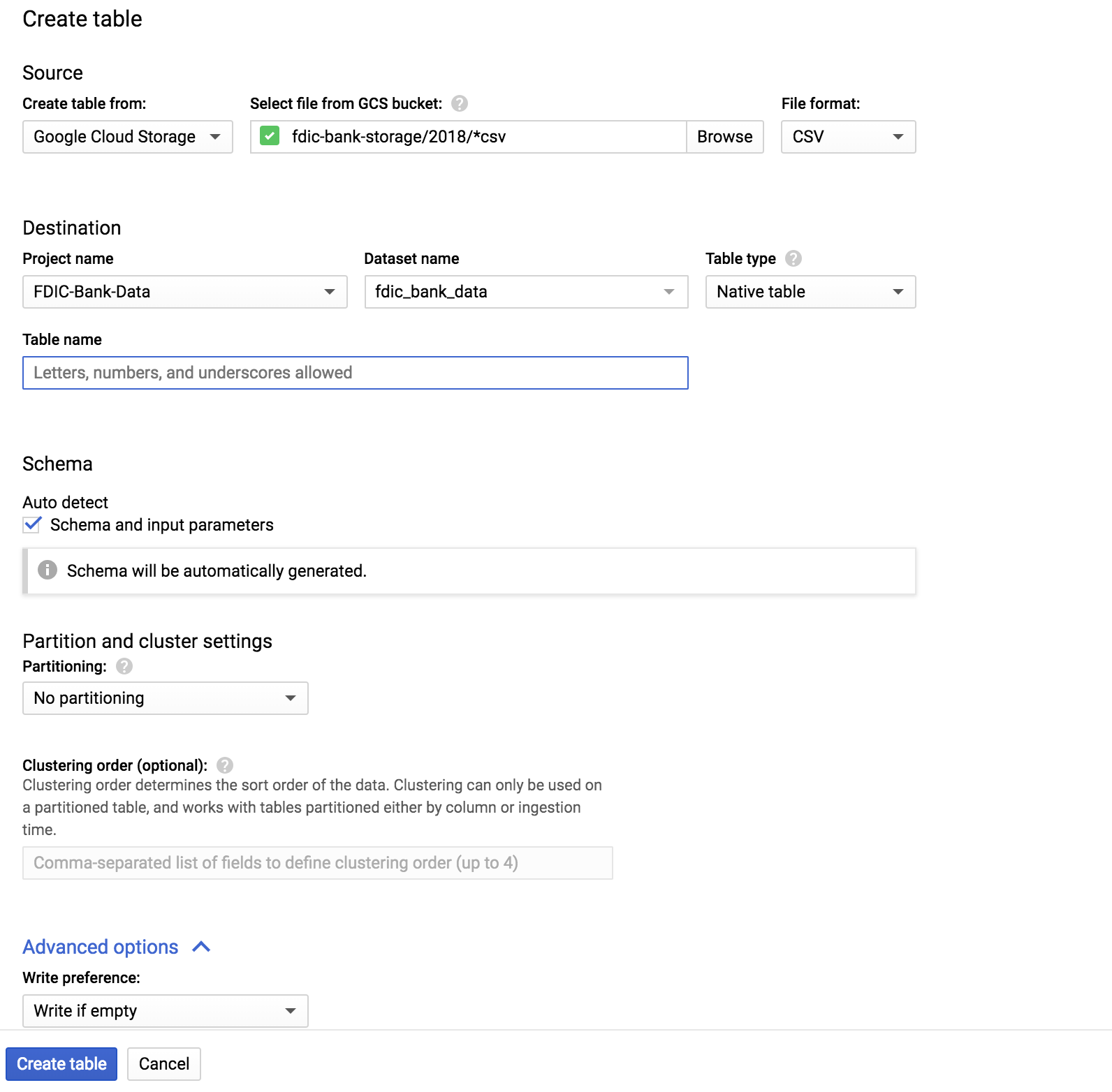
如何将具有不同模式的多个csv文件加载到bigquery中?
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-02-12 17:50:27
我实现自动化的方法基本上是从给定的桶(或其子文件夹)读取所有文件,并(假设)使用它们的“文件名”作为目标表名。以下是如何:
gsutil ls gs://mybucket/subfolder/*.csv | xargs -I{} echo {} | awk '{n=split($1,A,"/"); q=split(A[n],B,"."); print "mydataset."B[1]" "$0}' | xargs -I{} sh -c 'bq --location=US load --replace=false --autodetect --source_format=CSV {}'确保用所需的值替换location、mydataset。此外,请注意以下假设:
- 假定每个CSV的第一行为头,因此被视为列名。
- 我们使用
--replace=false标志编写,这意味着每次运行该命令时都会追加数据。如果您想要重写,只需将其转换为true,所有表的数据都将在每次运行时被重写。 - CSV文件名(
.csv之前的部分用作表名。您可以修改awk脚本以将其更改为任何其他选项。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54652651
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号