
如何修正“文件只能复制到0节点而不是minReplication (=1)”?
不久前我也问了一个类似的问题,并认为我解决了这个问题,但事实证明它消失了,仅仅是因为我在处理一个更小的数据集。
很多人问过这个问题,我浏览了每一个我能找到的网上帖子,但仍然没有取得任何进展。
我想做的是:我有一个外部表browserdata,它指的是大约1G的数据。我尝试将这些数据放入分区表partbrowserdata中,其定义如下:
CREATE EXTERNAL TABLE IF NOT EXISTS partbrowserdata (
BidID string,
Timestamp_ string,
iPinYouID string,
UserAgent string,
IP string,
RegionID int,
AdExchange int,
Domain string,
URL string,
AnonymousURL string,
AdSlotID string,
AdSlotWidth int,
AdSlotHeight int,
AdSlotVisibility string,
AdSlotFormat string,
AdSlotFloorPrice decimal,
CreativeID string,
BiddingPrice decimal,
AdvertiserID string,
UserProfileIDs array<string>
)
PARTITIONED BY (CityID int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION '/user/maria_dev/data2';使用此查询:
insert into table partbrowserdata partition(cityid)
select BidID,Timestamp_ ,iPinYouID ,UserAgent ,IP ,RegionID ,AdExchange ,Domain ,URL ,AnonymousURL ,AdSlotID ,AdSlotWidth ,AdSlotHeight ,AdSlotVisibility ,AdSlotFormat ,AdSlotFloorPrice ,CreativeID ,BiddingPrice ,AdvertiserID ,UserProfileIDs ,CityID
from browserdata;每次在每个平台上,无论是hortonworks还是cloudera,我都会收到这样的信息:
Caused by:
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/maria_dev/data2/.hive-staging_hive_2019-02-06_18-58-39_333_7627883726303986643-1/_task_tmp.-ext-10000/cityid=219/_tmp.000000_3 could only be replicated to 0 nodes instead of minReplication (=1). There are 4 datanode(s) running and no node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1720)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3389)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:683)
at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.addBlock(AuthorizationProviderProxyClientProtocol.java:214)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:495)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2217)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2213)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1917)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2211)
at org.apache.hadoop.ipc.Client.call(Client.java:1504)
at org.apache.hadoop.ipc.Client.call(Client.java:1441)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:230)
at com.sun.proxy.$Proxy14.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:413)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:258)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:104)
at com.sun.proxy.$Proxy15.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1814)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1610)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:773)我做什么好?我不明白为什么会这样。这看起来确实是一个内存问题,因为我可以插入几行,但并不是所有的行都是出于某种原因。请注意,我在HDFS上有足够的内存,所以1G的额外数据是1美元上的一分钱,所以这可能是RAM问题吗?
下面是我的dfs报告输出:
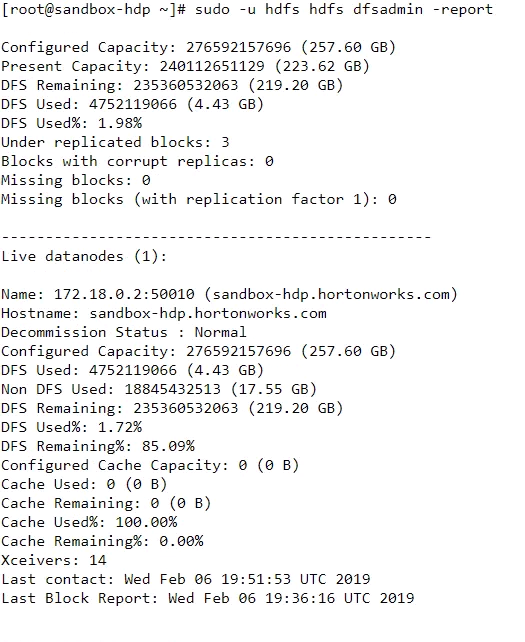
我已经在所有的执行引擎上尝试过这一点:spark、tez、mr。
请不要建议解决方案,说我需要格式化的namenode,因为他们不工作,他们不是任何方式的解决方案。
最新情况:
在查看namenode的日志之后,我注意到了这一点,如果它有帮助的话:
Failed to place enough replicas, still in need of 1 to reach 1 (unavailableStorages=[DISK ], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=true) All required storage types are unavailable: unavailableStorages=[DISK], stor agePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}这些日志表明:
有关更多信息,请在org.apache.hadoop.hdfs.ser ver.blockmanagement.BlockPlacementPolicy和org.apache.hadoop.net.NetworkTopology上启用调试日志级别。
我该怎么做?
我还注意到这里有一个类似的未解决的帖子:
HDP 2.2@Linux/CentOS@OracleVM (Hortonworks)在Eclipse@Windows远程提交时失败
更新2:
我只是试着用火花来划分这个部分,它是有效的!所以,这一定是蜂巢虫..。
更新3:
刚刚在MapR上测试了这一点,并且它成功了,但是MapR不使用HDFS。这绝对是某种HDFS + Hive组合错误。
证明:
回答 1
Stack Overflow用户
发布于 2019-02-16 04:04:45
最后,我接触了cloudera论坛,他们几分钟内就回答了我的问题:http://community.cloudera.com/t5/Storage-Random-Access-HDFS/Why-can-t-I-partition-a-1-gigabyte-dataset-into-300/m-p/86554#M3981,我尝试了刺耳的J的建议,而且效果很好!
他是这么说的:
如果您正在处理数据源中的无序分区,则在尝试分区时,您可能会并行创建许多文件。 在HDFS中,当一个文件(或更具体地说,它的块)打开时,DataNode执行其目标块大小的逻辑保留。因此,如果您配置的块大小为128个MiB,那么每个并发打开的块都将从DataNode发布到NameNode的可用剩余空间中(逻辑上)减去该值。 这样做是为了帮助管理空间,并保证向客户端写入完整的块,这样开始编写其文件的客户端就不会在中途遇到空间外的异常。 注意:当文件关闭时,只保留实际长度,并调整预订计算以反映已使用和可用空间的实际情况。但是,虽然文件块仍然处于打开状态,但它始终被认为持有完整的块大小。 如果NameNode还能保证完整的目标块大小,那么它只会为写选择一个DataNode。它将忽略它认为(基于其报告的值和指标)不适合被请求的写入参数的任何DataNodes。您的错误显示,当尝试分配新的块请求时,NameNode已经停止考虑您唯一的活动DataNode。 例如,如果有超过560个并发的、打开的文件(70 GiB划分为128个MiB块大小),那么可用空间的70 GiB将被证明是不够的。因此,DataNode将在大约560个打开的文件点“显示满”,并且不再是进一步文件请求的有效目标。 根据您对插入的描述,这可能是很可能的,因为数据集的每一个块可能仍然带有不同的in,因此在每个并行任务中请求了大量打开的文件,以便插入到几个不同的分区中。 您可以通过减少查询中的请求块大小(将dfs.blocksize设置为8 MiB for ex.)来“黑”您的方法,从而影响预订计算。但是,这对于更大的数据集来说可能不是一个好主意,因为它会增加文件:块计数和增加NameNode的内存成本。 更好的方法是执行分区前的插入(先按分区排序,然后以分区的方式插入)。例如,Hive提供了一个选项:hive.optimize.sort.dynamic.partition,如果您使用普通的Spark或MapReduce,那么它们的默认分区策略就是这样做的。
所以,到了最后,我做了set hive.optimize.sort.dynamic.partition=true;,一切都开始工作了。但我也做了另一件事。
下面是我早些时候在调查这个问题时发布的一篇文章:为什么我在写入分区表时得到“文件只能复制到0节点”?我遇到了一个问题,hive.exec.max.dynamic.partitions无法分割我的数据集,因为hive.exec.max.dynamic.partitions被设置为100,所以我搜索了这个问题,在hortonworks论坛上看到了一个答案,说我应该这么做:
SET hive.exec.max.dynamic.partitions=100000;
SET hive.exec.max.dynamic.partitions.pernode=100000;这是另一个问题,也许hive试图像设置hive.exec.max.dynamic.partitions一样打开这些并发连接,所以我的insert查询直到我将这些值降为500之后才开始工作。
https://stackoverflow.com/questions/54561086
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号