
如何使用Python有效地搜索另一个字符串列表中的字符串列表?
我有两个名称(字符串)列表,如下所示:
executives = ['Brian Olsavsky', 'Some Guy', 'Some Lady']
analysts = ['Justin Post', 'Some Dude', 'Some Chick']我需要在如下字符串列表中找到这些名称的位置:
str = ['Justin Post - Bank of America',
"Great. Thank you for taking my question. I guess the big one is the deceleration in unit growth or online stores.",
"I know it's a tough 3Q comp, but could you comment a little bit about that?",
'Brian Olsavsky - Amazon.com',
"Thank you, Justin. Yeah, let me just remind you a couple of things from last year.",
"We had two reactions on our Super Saver Shipping threshold in the first half." ,
"I'll just remind you that the units those do not count",
"In-stock is very strong, especially as we head into the holiday period.",
'Dave Fildes - Amazon.com',
"And, Justin, this is Dave. Just to add on to that. You mentioned the online stores.我需要这样做的原因是为了能够将会话字符串连接在一起(这些字符串由名称分隔)。我该如何有效地做这件事呢?
我研究了一些类似的问题,并试图解决这些问题,但没有结果,例如:
if any(x in str for x in executives):
print('yes')而这个..。
match = next((x for x in executives if x in str), False)
match回答 3
Stack Overflow用户
发布于 2019-02-02 10:56:08
我不确定这是不是你想要的:
executives = ['Brian Olsavsky', 'Some Guy', 'Some Lady']
text = ['Justin Post - Bank of America',
"Great. Thank you for taking my question. I guess the big one is the deceleration in unit growth or online stores.",
"I know it's a tough 3Q comp, but could you comment a little bit about that?",
'Brian Olsavsky - Amazon.com',
"Thank you, Justin. Yeah, let me just remind you a couple of things from last year.",
"We had two reactions on our Super Saver Shipping threshold in the first half." ,
"I'll just remind you that the units those do not count",
"In-stock is very strong, especially as we head into the holiday period.",
'Dave Fildes - Amazon.com',
"And, Justin, this is Dave. Just to add on to that. You mentioned the online stores."]
result = [s for s in text if any(ex in s for ex in executives)]
print(result)输出:“Brian Amazon.com”
Stack Overflow用户
发布于 2019-02-02 11:11:21
str = ['Justin Post - Bank of America',
"Great. Thank you for taking my question. I guess the big one is the deceleration in unit growth or online stores.",
"I know it's a tough 3Q comp, but could you comment a little bit about that?",
'Brian Olsavsky - Amazon.com',
"Thank you, Justin. Yeah, let me just remind you a couple of things from last year.",
"We had two reactions on our Super Saver Shipping threshold in the first half." ,
"I'll just remind you that the units those do not count",
"In-stock is very strong, especially as we head into the holiday period.",
'Dave Fildes - Amazon.com',
"And, Justin, this is Dave. Just to add on to that. You mentioned the online stores"]
executives = ['Brian Olsavsky', 'Justin', 'Some Guy', 'Some Lady']另外,如果您需要确切的位置,可以使用以下内容:
print([[i, str.index(q), q.index(i)] for i in executives for q in str if i in q ])这输出
[['Brian Olsavsky', 3, 0], ['Justin', 0, 0], ['Justin', 4, 11], ['Justin', 9, 5]]Stack Overflow用户
发布于 2020-07-24 10:14:39
TLDR
这个问题的答案是注重效率。如果不是关键问题,就使用其他答案。如果是的话,从您正在搜索的语料库中生成一个dict,然后使用这个数据集来查找您要查找的内容。
#import stuff we need later
import string
import random
import numpy as np
import time
import matplotlib.pyplot as plt创建示例语料库
首先,我们创建一个字符串列表,我们将在其中搜索。
使用以下函数创建随机单词,我指的是字符的随机序列,其长度从泊松分布中提取:
def poissonlength_words(lam_word): #generating words, length chosen from a Poisson distrib
return ''.join([random.choice(string.ascii_lowercase) for _ in range(np.random.poisson(lam_word))])(lam_word是泊松分布的参数。)
让我们从这些单词中创建number_of_sentences可变长度的句子(我指的是由空格分隔的随机生成的单词列表)。
句子的长度也可以从泊松分布中提取。
lam_word=5
lam_sentence=1000
number_of_sentences = 10000
sentences = [' '.join([poissonlength_words(lam_word) for _ in range(np.random.poisson(lam_sentence))])
for x in range(number_of_sentences)]sentences[0]现在将像这样开始:
公司名称:上海市发布日期:北京市发布时间:2009-4-15
我们还可以创建名称,我们将搜索这些名称。让这些名字是大图。名字(即bigram的第一个元素)将是n字符,姓氏(第二个bigram元素)将是m字符长,它将由随机字符组成:
def bigramgen(n,m):
return ''.join([random.choice(string.ascii_lowercase) for _ in range(n)])+' '+\
''.join([random.choice(string.ascii_lowercase) for _ in range(m)])任务
比方说,我们想要找到像ab c这样的大字出现的句子。我们不想找到dab c或ab cd,只有ab c站在一个单独的地方。
为了测试一个方法有多快,让我们找到一个不断增加的比格数,并测量经过的时间。例如,我们搜索的比格数可以是:
number_of_bigrams_we_search_for = [10,30,50,100,300,500,1000,3000,5000,10000]- 刚体力法
只需循环遍历每个双字符,循环遍历每个句子,使用in查找匹配项。同时,度量值耗用时间和time.time()。
bruteforcetime=[]
for number_of_bigrams in number_of_bigrams_we_search_for:
bigrams = [bigramgen(2,1) for _ in range(number_of_bigrams)]
start = time.time()
for bigram in bigrams:
#the core of the brute force method starts here
reslist=[]
for sentencei, sentence in enumerate(sentences):
if ' '+bigram+' ' in sentence:
reslist.append([bigram,sentencei])
#and ends here
end = time.time()
bruteforcetime.append(end-start)bruteforcetime将保持所需的秒数来找到10,30,50 .比格图。
警告:这可能需要很长一段时间才能达到很高的数量。
- 对您的东西进行排序,以使方法更快
让我们为出现在任何句子中的每个单词创建一个空集(使用dict理解):
worddict={word:set() for sentence in sentences for word in sentence.split(' ')}在这些集合中的每一个集合中,添加其出现的每个单词的index:
for sentencei, sentence in enumerate(sentences):
for wordi, word in enumerate(sentence.split(' ')):
worddict[word].add(sentencei)请注意,我们只做过一次,不管我们以后搜索了多少个大写。
使用本词典,我们可以搜索到每个部分出现的双字形的句子。这非常快,因为调用了一个dict值非常快。然后是取这些集合的交集。当我们搜索ab c时,我们将有一组语句索引,其中ab和c都会出现。
for bigram in bigrams:
reslist=[]
setlist = [worddict[gram] for gram in target.split(' ')]
intersection = set.intersection(*setlist)
for candidate in intersection:
if bigram in sentences[candidate]:
reslist.append([bigram, candidate])让我们把整件事放在一起,测量一下过去的时间:
logtime=[]
for number_of_bigrams in number_of_bigrams_we_search_for:
bigrams = [bigramgen(2,1) for _ in range(number_of_bigrams)]
start_time=time.time()
worddict={word:set() for sentence in sentences for word in sentence.split(' ')}
for sentencei, sentence in enumerate(sentences):
for wordi, word in enumerate(sentence.split(' ')):
worddict[word].add(sentencei)
for bigram in bigrams:
reslist=[]
setlist = [worddict[gram] for gram in bigram.split(' ')]
intersection = set.intersection(*setlist)
for candidate in intersection:
if bigram in sentences[candidate]:
reslist.append([bigram, candidate])
end_time=time.time()
logtime.append(end_time-start_time)警告:这可能需要很长的时间来高数量的比格,但比蛮力法要少。
结果
我们可以画出每一种方法花了多少时间。
plt.plot(number_of_bigrams_we_search_for, bruteforcetime,label='linear')
plt.plot(number_of_bigrams_we_search_for, logtime,label='log')
plt.legend()
plt.xlabel('Number of bigrams searched')
plt.ylabel('Time elapsed (sec)')或者,在y axis上绘制测井标尺
plt.plot(number_of_bigrams_we_search_for, bruteforcetime,label='linear')
plt.plot(number_of_bigrams_we_search_for, logtime,label='log')
plt.yscale('log')
plt.legend()
plt.xlabel('Number of bigrams searched')
plt.ylabel('Time elapsed (sec)')给我们情节:
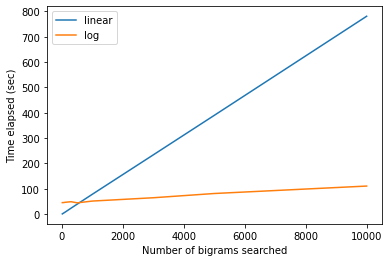
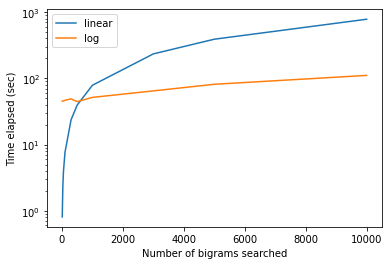
制作worddict字典需要花费大量的时间,而且在搜索少量的名称时也是一个缺点。然而,有一点是,与蛮力法相比,语料库足够大,我们正在搜索的名字数量也足够多,这一次得到了搜索速度的补偿。因此,如果满足这些条件,我建议使用此方法。
(笔记本可用https://colab.research.google.com/drive/1c7P2KEnl3G9BIsSTSRVA3AMKHlB8sYrU?usp=sharing。)
https://stackoverflow.com/questions/54492158
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号