
性能问题:拒绝执行org.elasticsearch.ingest.PipelineExecutionSService
我一直在努力传输5亿个文档,这些文档是从Windows IIS日志、从kafka到elasticsearch提供的。在运输过程开始的时候,一切都很好。
从Kafka-manager仪表板上,我可以看到文档输出/字节的速度大约是每分钟100万。
一周后,输出/字节的速度降低到每分钟200 K。我以为它有问题。当我打开elasticsearch日志文件时,我可以看到许多错误。
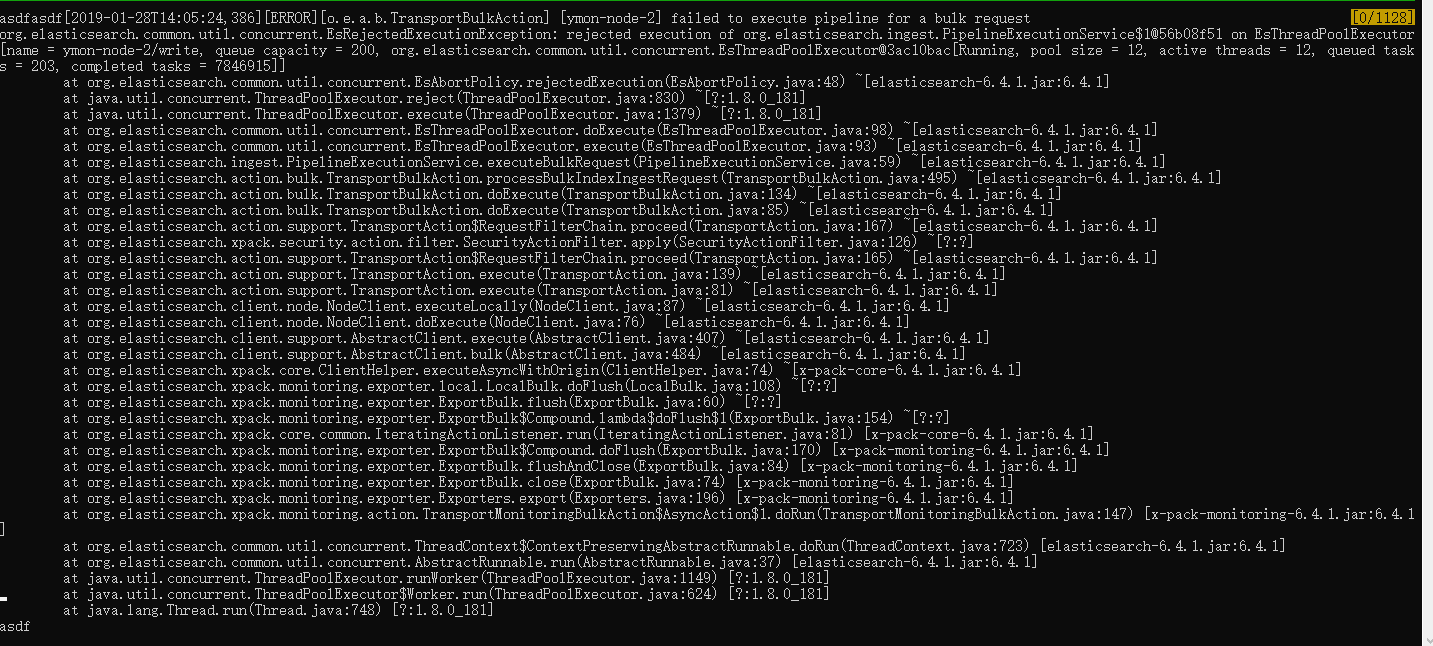
错误是下面的语句。
错误*-节点-2未能为大容量请求执行管道,org.elasticsearch.common.util.concurrent.EsRejectedExecutionException:拒绝执行org.elasticsearch.ingest.PipelineExecutionSService$.....论EsThreadPoolExecutor
第一次,我认为这是线程池不足的问题。但是elasticsearch论坛并不强烈推荐调优写线程池。
第二次,它来自于ingest geoip,因为错误声明中写着“ingest.PipelineExecution.”,所以我在logstash配置中简化了geoip过滤器。也就是说,关闭geoip。
此外,还试图在logstash配置中减少管道工作人员的数量和批处理大小。
一切都失败了..。克服这个错误是没有希望的。
帮帮天才!
回答 1
Stack Overflow用户
发布于 2019-01-28 07:00:17
从您粘贴的日志来看,队列容量似乎是200,但是有203个排队的任务。我想,要么是由于吞食的管道太长,要么是索引速度慢,或者是有大量的索引数据给队列带来压力。另一种选择是,不要滚动索引,当索引变得太大时,合并越大,索引的性能就越低。
首先,我将队列容量提高到2000,监视队列大小,并检查传入数据是否有短暂/长时间的突发。另一件要做的事情是监视索引延迟,并通过检查管道的时间来检查吞并管道是否是瓶颈。您可以尝试在短时间内禁用它们(如果可以的话),并查看这是否会放松队列和日志中的错误。
https://stackoverflow.com/questions/54395952
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号