
利用海运可视化丢失数据的发生频率
我想要创建一个24x20矩阵(每个部分有60个单元格或6x10),通过熊猫数据格式在dataset中通过循环(=每个480-值)可视化丢失数据的频率,并为每个列( 'A'、'B'、'C' )绘制它。
到目前为止,我可以映射创建csv文件,并以正确的方式以矩阵的方式映射值,并在将丢失的数据(nan & inf)更改为0或对数据影响最小的0.01234之类的东西之后,通过0绘制它。下面是到目前为止我的脚本:
import numpy as np
import pandas as pd
import os
import seaborn as sns
import matplotlib.pyplot as plt
def mkdf(ListOf480Numbers):
normalMatrix = np.array_split(ListOf480Numbers,8)
fixMatrix = []
for i in range(8):
lines = np.array_split(normalMatrix[i],6)
newMatrix = [0,0,0,0,0,0]
for j in (1,3,5):
newMatrix[j] = lines[j]
for j in (0,2,4):
newMatrix[j] = lines[j][::-1]
fixMatrix.append(newMatrix)
return fixMatrix
def print_df(fixMatrix):
values = []
for i in range(6):
values.append([*fixMatrix[6][i], *fixMatrix[7][i]])
for i in range(6):
values.append([*fixMatrix[4][i], *fixMatrix[5][i]])
for i in range(6):
values.append([*fixMatrix[2][i], *fixMatrix[3][i]])
for i in range(6):
values.append([*fixMatrix[0][i], *fixMatrix[1][i]])
df = pd.DataFrame(values)
return (df)
dft = pd.read_csv('D:\Feryan.TXT', header=None)
id_set = dft[dft.index % 4 == 0].astype('int').values
A = dft[dft.index % 4 == 1].values
B = dft[dft.index % 4 == 2].values
C = dft[dft.index % 4 == 3].values
data = {'A': A[:,0], 'B': B[:,0], 'C': C[:,0]}
df = pd.DataFrame(data, columns=['A','B','C'], index = id_set[:,0])
nan = np.array(df.isnull())
inf = np.array(df.isnull())
df = df.replace([np.inf, -np.inf], np.nan)
df[np.isinf(df)] = np.nan # convert inf to nan
#dff = df[df.isnull().any(axis=1)] # extract sub data frame
#df = df.fillna(0)
#df = df.replace(0,np.nan)
#next iteration create all plots, change the number of cycles
cycles = int(len(df)/480)
print(cycles)
for cycle in range(3):
count = '{:04}'.format(cycle)
j = cycle * 480
new_value1 = df['A'].iloc[j:j+480]
new_value2 = df['B'].iloc[j:j+480]
new_value3 = df['C'].iloc[j:j+480]
df1 = print_df(mkdf(new_value1))
df2 = print_df(mkdf(new_value2))
df3 = print_df(mkdf(new_value3))
for i in df:
try:
os.mkdir(i)
except:
pass
df1.to_csv(f'{i}/norm{i}{count}.csv', header=None, index=None)
df2.to_csv(f'{i}/norm{i}{count}.csv', header=None, index=None)
df3.to_csv(f'{i}/norm{i}{count}.csv', header=None, index=None)
#plotting all columns ['A','B','C'] in-one-window side by side
fig, ax = plt.subplots(nrows=1, ncols=3 , figsize=(20,10))
plt.subplot(131)
ax = sns.heatmap(df1.isnull(), cbar=False)
ax.axhline(y=6, color='w',linewidth=1.5)
ax.axhline(y=12, color='w',linewidth=1.5)
ax.axhline(y=18, color='w',linewidth=1.5)
ax.axvline(x=10, color='w',linewidth=1.5)
plt.title('Missing-data frequency in A', fontsize=20 , fontweight='bold', color='black', loc='center', style='italic')
plt.axis('off')
plt.subplot(132)
ax = sns.heatmap(df2.isnull(), cbar=False)
ax.axhline(y=6, color='w',linewidth=1.5)
ax.axhline(y=12, color='w',linewidth=1.5)
ax.axhline(y=18, color='w',linewidth=1.5)
ax.axvline(x=10, color='w',linewidth=1.5)
plt.title('Missing-data frequency in B', fontsize=20 , fontweight='bold', color='black', loc='center', style='italic')
plt.axis('off')
plt.subplot(133)
ax = sns.heatmap(df3.isnull(), cbar=False)
ax.axhline(y=6, color='w',linewidth=1.5)
ax.axhline(y=12, color='w',linewidth=1.5)
ax.axhline(y=18, color='w',linewidth=1.5)
ax.axvline(x=10, color='w',linewidth=1.5)
plt.title('Missing-data frequency in C', fontsize=20 , fontweight='bold', color='black', loc='center', style='italic')
plt.axis('off')
plt.suptitle(f'Missing-data visualization', color='yellow', backgroundcolor='black', fontsize=15, fontweight='bold')
plt.subplots_adjust(top=0.92, bottom=0.02, left=0.05, right=0.96, hspace=0.2, wspace=0.2)
fig.text(0.035, 0.93, 'dataset1' , fontsize=19, fontweight='bold', rotation=42., ha='center', va='center',bbox=dict(boxstyle="round",ec=(1., 0.5, 0.5),fc=(1., 0.8, 0.8)))
#fig.tight_layout()
plt.savefig(f'{i}/result{count}.png')
#plt.show() 问题是,我不知道如何绘制丢失数据的频率,以正确地理解在哪些区段和单元格中频繁发生。
Note1更少的值,颜色应该更亮,并且100%丢失的数据通过循环应该由白色颜色和实心黑色颜色表示无缺失值。可能有一个从黑色开始的条形图0%到100%的白色。
Note2 i还提供了dataset的三个周期的示例文本文件,其中包含少量丢失的数据,但可以手动修改和增加:数据集
预期结果应该如下所示:
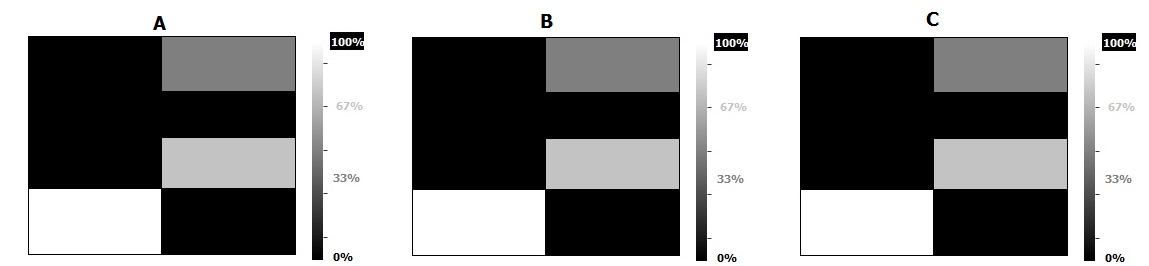
回答 1
Stack Overflow用户
发布于 2019-02-04 12:57:48
您可以将nan/inf数据存储在一个独立的数组中,您可以在每个nan/inf的循环中将该数组相加。
您的数组似乎总是具有相同的大小,所以我用固定的大小来定义它们。您可以更改它以匹配您的数据:
df1MissingDataFrequency = np.zeros((24,20))然后,可以将它们添加到获得nan值的位置(代码中已经用nan替换了inf ):
df1MissingDataFrequency = df1MissingDataFrequency + np.isnan(df1).astype(int)在你所有的循环中。
你的压痕好像有些问题。我不知道您在这里发布的代码是否是这样的,或者在您的实际代码中是否是相同的,但是现在您为每个和创建了一个新的情节,您为每个i重新定义了df1, df2, df3。
对于丢失的频率数据,代码应该如下所示:
import numpy as np
import pandas as pd
import os
import seaborn as sns
import matplotlib.pyplot as plt
def mkdf(ListOf480Numbers):
normalMatrix = np.array_split(ListOf480Numbers,8)
fixMatrix = []
for i in range(8):
lines = np.array_split(normalMatrix[i],6)
newMatrix = [0,0,0,0,0,0]
for j in (1,3,5):
newMatrix[j] = lines[j]
for j in (0,2,4):
newMatrix[j] = lines[j][::-1]
fixMatrix.append(newMatrix)
return fixMatrix
def print_df(fixMatrix):
values = []
for i in range(6):
values.append([*fixMatrix[6][i], *fixMatrix[7][i]])
for i in range(6):
values.append([*fixMatrix[4][i], *fixMatrix[5][i]])
for i in range(6):
values.append([*fixMatrix[2][i], *fixMatrix[3][i]])
for i in range(6):
values.append([*fixMatrix[0][i], *fixMatrix[1][i]])
df = pd.DataFrame(values)
return (df)
dft = pd.read_csv('D:/Feryan2.txt', header=None)
id_set = dft[dft.index % 4 == 0].astype('int').values
A = dft[dft.index % 4 == 1].values
B = dft[dft.index % 4 == 2].values
C = dft[dft.index % 4 == 3].values
data = {'A': A[:,0], 'B': B[:,0], 'C': C[:,0]}
df = pd.DataFrame(data, columns=['A','B','C'], index = id_set[:,0])
nan = np.array(df.isnull())
inf = np.array(df.isnull())
df = df.replace([np.inf, -np.inf], np.nan)
df[np.isinf(df)] = np.nan # convert inf to nan
df1MissingDataFrequency = np.zeros((24,20))
df2MissingDataFrequency = np.zeros((24,20))
df3MissingDataFrequency = np.zeros((24,20))
#next iteration create all plots, change the number of cycles
cycles = int(len(df)/480)
print(cycles)
for cycle in range(3):
count = '{:04}'.format(cycle)
j = cycle * 480
new_value1 = df['A'].iloc[j:j+480]
new_value2 = df['B'].iloc[j:j+480]
new_value3 = df['C'].iloc[j:j+480]
df1 = print_df(mkdf(new_value1))
df2 = print_df(mkdf(new_value2))
df3 = print_df(mkdf(new_value3))
for i in df:
try:
os.mkdir(i)
except:
pass
df1.to_csv(f'{i}/norm{i}{count}.csv', header=None, index=None)
df2.to_csv(f'{i}/norm{i}{count}.csv', header=None, index=None)
df3.to_csv(f'{i}/norm{i}{count}.csv', header=None, index=None)
df1MissingDataFrequency = df1MissingDataFrequency + np.isnan(df1).astype(int)
df2MissingDataFrequency = df2MissingDataFrequency + np.isnan(df2).astype(int)
df3MissingDataFrequency = df3MissingDataFrequency + np.isnan(df3).astype(int)
#plotting all columns ['A','B','C'] in-one-window side by side
fig, ax = plt.subplots(nrows=1, ncols=3 , figsize=(10,7))
plt.subplot(131)
ax = sns.heatmap(df1MissingDataFrequency, cbar=False, cmap="gray")
ax.axhline(y=6, color='w',linewidth=1.5)
ax.axhline(y=12, color='w',linewidth=1.5)
ax.axhline(y=18, color='w',linewidth=1.5)
ax.axvline(x=10, color='w',linewidth=1.5)
plt.title('Missing-data frequency in A', fontsize=20 , fontweight='bold', color='black', loc='center', style='italic')
plt.axis('off')
plt.subplot(132)
ax = sns.heatmap(df2MissingDataFrequency, cbar=False, cmap="gray")
ax.axhline(y=6, color='w',linewidth=1.5)
ax.axhline(y=12, color='w',linewidth=1.5)
ax.axhline(y=18, color='w',linewidth=1.5)
ax.axvline(x=10, color='w',linewidth=1.5)
plt.title('Missing-data frequency in B', fontsize=20 , fontweight='bold', color='black', loc='center', style='italic')
plt.axis('off')
plt.subplot(133)
ax = sns.heatmap(df3MissingDataFrequency, cbar=False, cmap="gray")
ax.axhline(y=6, color='w',linewidth=1.5)
ax.axhline(y=12, color='w',linewidth=1.5)
ax.axhline(y=18, color='w',linewidth=1.5)
ax.axvline(x=10, color='w',linewidth=1.5)
plt.title('Missing-data frequency in C', fontsize=20 , fontweight='bold', color='black', loc='center', style='italic')
plt.axis('off')
plt.suptitle(f'Missing-data visualization', color='yellow', backgroundcolor='black', fontsize=15, fontweight='bold')
plt.subplots_adjust(top=0.92, bottom=0.02, left=0.05, right=0.96, hspace=0.2, wspace=0.2)
fig.text(0.035, 0.93, 'dataset1' , fontsize=19, fontweight='bold', rotation=42., ha='center', va='center',bbox=dict(boxstyle="round",ec=(1., 0.5, 0.5),fc=(1., 0.8, 0.8)))
#fig.tight_layout()
plt.savefig(f'{i}/result{count}.png')
#plt.show() 这给出了您想要的输出:

编辑
本着干的的精神,我编辑了您的代码,这样您就没有df1,df2,df3,new_values1,.你到处复制和粘贴同样的东西。您已经遍历了i,因此您应该使用它来实际处理数据文件中的三个不同的列:
dft = pd.read_csv('C:/Users/frefra/Downloads/Feryan2.txt', header=None).replace([np.inf, -np.inf], np.nan)
id_set = dft[dft.index % 4 == 0].astype('int').values
A = dft[dft.index % 4 == 1].values
B = dft[dft.index % 4 == 2].values
C = dft[dft.index % 4 == 3].values
data = {'A': A[:,0], 'B': B[:,0], 'C': C[:,0]}
df = pd.DataFrame(data, columns=['A','B','C'], index = id_set[:,0])
new_values = []
dfs = []
nan_frequencies = np.zeros((3,24,20))
#next iteration create all plots, change the number of cycles
cycles = int(len(df)/480)
print(cycles)
for cycle in range(cycles):
count = '{:04}'.format(cycle)
j = cycle * 480
for idx,i in enumerate(df):
try:
os.mkdir(i)
except:
pass
new_value = df[i].iloc[j:j+480]
new_values.append(new_value)
dfi = print_df(mkdf(new_value))
dfs.append(dfi)
dfi.to_csv(f'{i}/norm{i}{count}.csv', header=None, index=None)
nan_frequencies[idx] = nan_frequencies[idx] + np.isnan(dfi).astype(int)
#plotting all columns ['A','B','C'] in-one-window side by side
fig, ax = plt.subplots(nrows=1, ncols=3 , figsize=(10,7))
for idx,i in enumerate(df):
plt.subplot(1,3,idx+1)
ax = sns.heatmap(nan_frequencies[idx], cbar=False, cmap="gray")
ax.axhline(y=6, color='w',linewidth=1.5)
ax.axhline(y=12, color='w',linewidth=1.5)
ax.axhline(y=18, color='w',linewidth=1.5)
ax.axvline(x=10, color='w',linewidth=1.5)
plt.title('Missing-data frequency in ' + i, fontsize=20 , fontweight='bold', color='black', loc='center', style='italic')
plt.axis('off')https://stackoverflow.com/questions/54394457
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号