
内核svm的图片格式
要将一系列图像转换成正确的格式以输入sklearn.svm.SVC,我有一些困难。
这是我的第一个图像识别项目,所以我有点痛苦。
我有一个循环,它将一堆(大小不同的) base64 RGB图像导入到一个dataframe
imageData = mpimg.imread(io.BytesIO(base64.b64decode(value)),format='JPG')然后,我将RGB图像转换为灰度,并使其变平。
data_images = rgb2gray(imageData).ravel()其中rgb2gray:
def rgb2gray(rgb):
r, g, b = rgb[:,:,0], rgb[:,:,1], rgb[:,:,2]
gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
return gray如果我看看大小的差异
df_raw.sample(10)
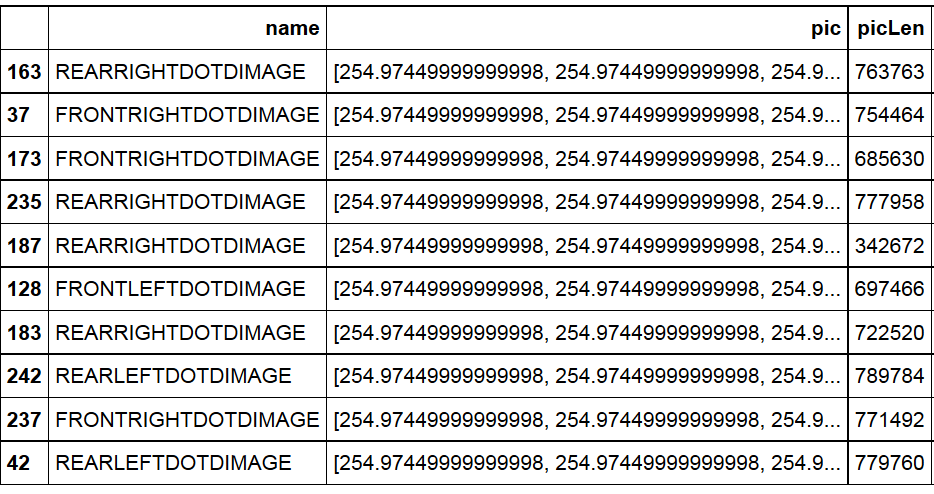
我们可以看到图像像素长度在我的样本之间是不同的。我在这里有点搞不懂该怎么做。由于没有更好的主意,我决定根据最大尺寸的图片添加一个垫子,
df_raw.picLen.max()然后在每个一维图像数组的末尾附加一些零。
def padPic(x,numb,maxN):
N = maxN-len(x)
out = np.pad(x,(numb,N),'constant')
return out呼叫
df_raw['picNew'] = df_raw.apply(lambda row: padPic(row['pic'],0,df_raw.picLen.max()), axis=1)
df_raw['picNewLen'] = df_raw.apply(lambda row: len(row['picNew']), axis=1)我现在有一个大小相同的数组
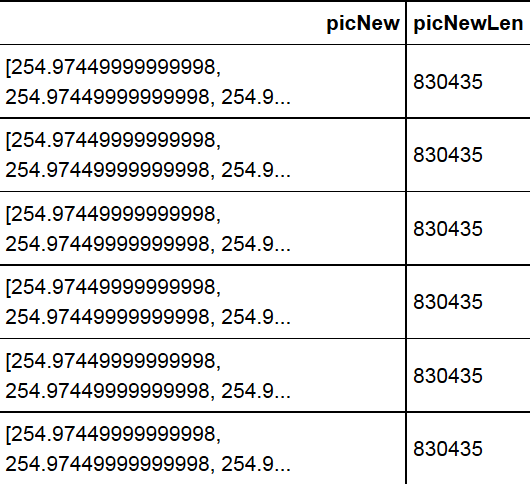
在这里,我试图拟合一个模型,以支持向量算法,使用图片数据作为X和一组标签作为y。
from sklearn.svm import SVC
X_train, X_test, y_train, y_test = train_test_split(df_raw.picNew, df_raw.name, test_size = 0.2, random_state=42)检查大小:
print('Training data and target sizes: \n{}, {}'.format(X_train.shape,y_train.shape))
print('Test data and target sizes: \n{}, {}'.format(X_test.shape,y_test.shape))训练数据和目标尺寸:(198,),(198,)测试数据和目标大小:(50,),(50,)
当我说服自己一切都准备好之后,我就试着去适应这个模型。
svm = SVC()
svm.fit(X_train, y_train)这会引发一个错误,我不知道为什么:
/opt/wakari/anaconda/envs/ulabenv_2018-11-13_10.15.00/lib/python3.5/site-packages/numpy/core/numeric.py (a,dtype,order) 499500“”-> 501返回数组(a,dtype,copy=False,order=order) 502 503 ValueError:用序列设置数组元素。
我认为这肯定与数组大小有关,但我无法弄清楚。*-/
除了错误,更一般的说,我对我的方法有一个问题。特别是,我认为我的“填充”可能是不正确的,也许调整一些大小会更好。我很感谢对我的方法的任何反馈。谢谢
回答 2
Stack Overflow用户
发布于 2019-01-27 17:13:06
我已经解决了这个问题。
感谢Artem抓住了我明显的不编码类的问题,但这最终不是我的问题。
原来我的图片数组被表示的方式是不正确的。最初的数组是df_raw['picNew'].shape,它的计算值为
(248,)
我需要的是二维表示法
np.stack(df_raw['picNew'] , axis=1).shape(830435,248个)
现在一切都好了。
我仍然不确定是否有最“正确”的方法来调整图像的大小以保持相同的长度。将0附加到数组长度似乎有点简单.因此,如果有人有一个想法:)
Stack Overflow用户
发布于 2019-01-25 20:45:20
我非常肯定,这是由于在特性列和字符串中使用list作为目标值。对于后者,您需要按照fit()的要求,使用LabelEncoder类将它们转换为规范化的类标签。
参见此处描述:https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html
这需要在火车/测试拆分之前完成,以确保所有的名字都被LabelEncoder“看到”了。
对于前者,您可能需要搜索MNIST教程,这将提供大量应用于图像分类问题的算法。
另外,在压平前调整尺寸应该比填充更好。
https://stackoverflow.com/questions/54372231
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号