
DQN在Atari Pong任务中坚持次优策略
DQN在Atari Pong任务中坚持次优策略
提问于 2019-01-25 19:41:50
我正在用Atari的目标环境从零开始在PyTorch中实现DQN模型。经过一段时间的超参数调整后,我似乎无法获得模型来实现大多数出版物中所报告的性能(~ +21奖励;这意味着代理几乎赢得了每一次截击)。
我最近的结果如下图所示。请注意,x轴是集(完整的游戏到21),但总训练迭代是670万。
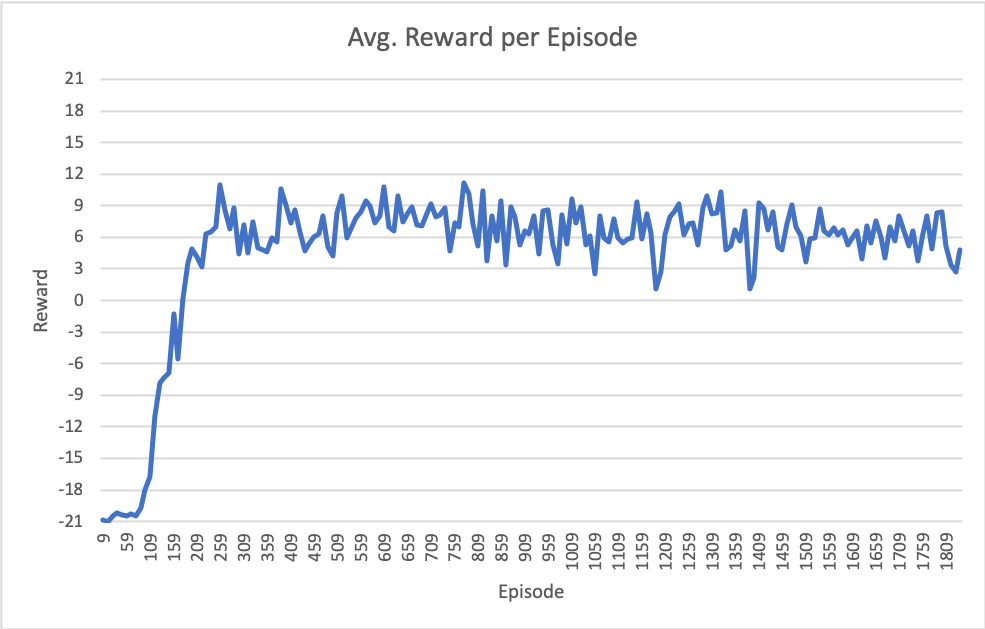
我的设置的具体内容如下:
模型
class DQN(nn.Module):
def __init__(self, in_channels, outputs):
super(DQN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=32, kernel_size=8, stride=4)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=4, stride=2)
self.conv3 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1)
self.fc1 = nn.Linear(in_features=64*7*7 , out_features=512)
self.fc2 = nn.Linear(in_features=512, out_features=outputs)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = x.view(-1, 64 * 7 * 7)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x # return Q values of each action超参数
- 批次大小: 32
- 重放内存大小: 100000
- 初始epsilon: 1.0
- 在100000步以上,epsilon退火线性到0.02
- 随机热开始集:~50000
- 每1000步更新一次目标模型
- 优化器= optim.RMSprop(policy_net.parameters(),lr=0.0025,alpha=0.9,eps=1e-02,momentum=0.0)
更多信息
- OpenAI健身房Pong-v0环境
- 最后观察到的4个帧的喂食模型堆栈,缩放和裁剪到84x84,这样只有“游戏区域”是可见的。
- 将失去一次截击(结束生命)视为回放缓冲区中的终端状态。
- 使用损失,它充当Huber损失
- 在优化之前,在-1和1之间裁剪梯度
- 我按照报纸的建议,用4-30的非操作步骤来抵消每集的开头。
有没有人有过类似的经历,被困在6-9平均奖励每集这样?
任何修改超参数或算法细节的建议都将不胜感激!
回答 1
Stack Overflow用户
发布于 2020-01-04 22:34:07
试着使用按优先顺序的体验回放。
这肯定能帮你得到更好的分数。
也可以试试batch_size更大的f. 64。(它可以改善坡度)
尝试学习速度下降(随着训练时间的推移)。(这可能有效)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54371840
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号