
如何解释(意外) sklearn.tree.tree_tree.value属性值?
与AdaBoostClassifier一起使用的决策树分类器存根对应的值属性的值不符合预期,因此我无法确定这些值所指示的是什么。我想了解帮助分析存根估计器的行为以及存根对AdaBoostClassifier的贡献的值。类似的堆栈溢出问题与我的数据无关。
版本信息
- python: 3.6.5
- 滑雪版: 0.20.2
DecisionTreeClassifier存根配置为:
number_estimators = 301
bdt= AdaBoostClassifier(DecisionTreeClassifier(max_depth=1),
algorithm="SAMME.R", n_estimators=number_estimators)AdaBoostClassifier是一个二进制分类器,其输出状态为A类和B类(编码为+1和-1)。训练集由23个特征组成,分类器执行ok (预测精度、准确率、召回率均约为79%)。我正在分析漏报预测,以获得一些关于分类错误的见解。
共有782个训练样本。301个存根估计器是通过以下途径从AdaBoostClassifier获得的:
tree_stubs = bdt.estimators_对应于第6种估计量的示例存根(基于0的列表):
bdt.estimators_[5]
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=1,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=421257592, splitter='best')此存根的值:
stub_5.tree_.value
array([[[0.5 , 0.5 ]],
[[0.29308331, 0.1861591 ]],
[[0.20691669, 0.3138409 ]]]) 对于熟悉graphviz的人来说,树存根看起来像:
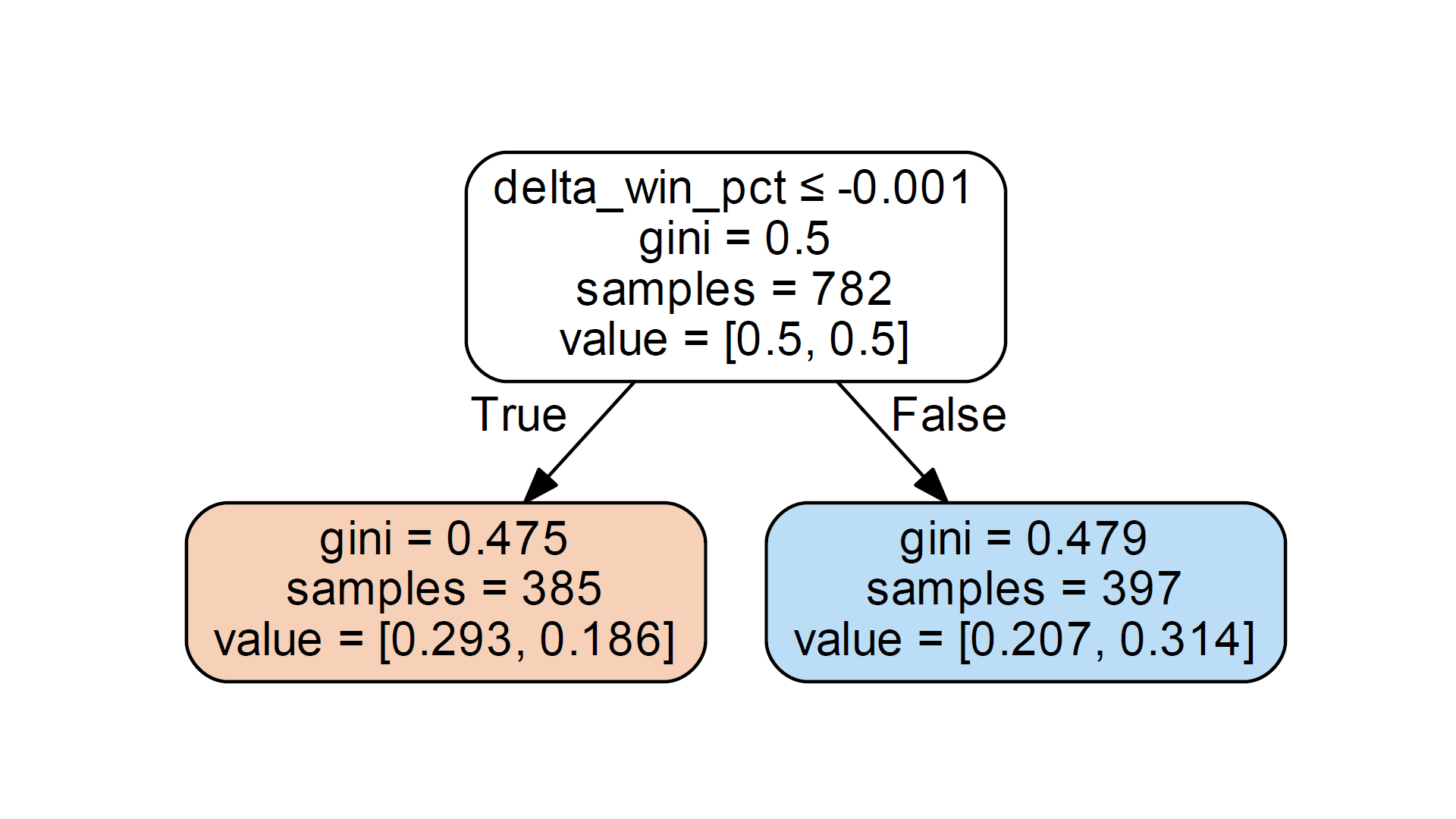
根节点正确地显示样本数(782)。value属性指示0.5,0.5。我希望value属性是每个类中的样本数,而不是百分比。但在根节点中,0.5值确实反映了我所拥有的平衡训练集,它们对两个类具有相同的表示形式。
现在是问题所在。该存根中的分裂特性根据delta_win_pct值小于或等于-.001的阈值来划分样本。我的数据集确实有385个样本记录,其中delta_win_pct小于此阈值,397个样本delta_win_pct大于阈值。因此,样本数据在树存根的左右叶节点是正确的。
但价值数据似乎是不正确的。在左子节点中,值报告为value=0.293,0.186,在右侧子节点,value=0.207,0.314。注意,这是sklearn.tree._tee.Tree类报告的数据,并不表示图形存在任何问题。
这些值的数量代表什么?
考虑到左叶节点,我的数据集实际上有264个A类样本,其delta_win_pct <= -0.001和121个B类样本与这个分裂阈值相匹配。这些数字对应于.6857,.3143而不是0.293,0.186的百分比。不正确的值与预期值不成线性比例。
类似地,对于右子节点,值数据提供为0.207,0.314,但对于其.330超过阈值的397个样本,期望值应为delta_win_pct、.670。
我注意到所提供的值数据(0.293、0.186、0.207、0.314)中的数字加起来等于1.0。但每个节点的值加起来并不等于1.0。我尝试使用提供的值作为所有样本的百分比,例如0.293 * 782 = 229,这与任何东西都没有关联。
有没有人对提供的价值数据有任何洞察力?我对这些价值观的理解和期望是否不正确?
最后,我注意到数据中值的相对大小与每个节点中的大多数样本正确相关。在左子节点0.293大于0.186,指示左节点具有大多数A类样本。而在右叶节点0.207 < 0.314,表示当delta_win_pct >阈值时大多数B类样本。我怀疑这就是为什么AdaBoostClassifier看起来起作用了。
总之,我想了解这些价值值。
回答 3
Stack Overflow用户
发布于 2019-01-11 00:03:20
我尝试在生成的数据集上复制它:
import pydot
import numpy as np
from IPython.display import Image, display
from sklearn.externals.six import StringIO
from sklearn.tree import DecisionTreeClassifier, _tree
from sklearn.datasets import make_classification
from sklearn.ensemble import AdaBoostClassifier
X, y = make_classification(n_informative=2, n_features=3, n_samples=200, n_redundant=1, random_state=42, n_classes=2)
feature_names = ['X0','X1','X2','X3']
clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1),
algorithm="SAMME.R", n_estimators=301)
clf.fit(X, y)
estimator = clf.estimators_[0]
dot_data = StringIO()
tree.export_graphviz(estimator, out_file=dot_data, proportion=False, filled=True,node_ids=True,rounded=True,class_names=['0','1'])
graph = pydot.graph_from_dot_data(dot_data.getvalue()) [0]
def viewPydot(pdot):
plt = Image(pdot.create_png())
display(plt)
viewPydot(graph)我发现有两种情况,一种是“适当的”(clf.estimators_[0]),一种是这样的
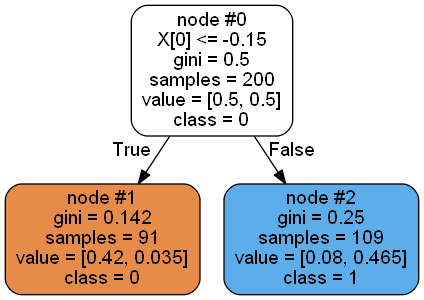
这里,value表示节点中特定类相对于样本总数的比例,因此node#1:[84/200=0.42,7/200=0.035],node#2:[16/200=0.08,93/200=0.465]
如果将proportion参数设置为True,则将得到每个节点的类分布百分比,例如node#2:[16/109, 93/109]=[0.147, 0.853]。它是计算使用 weighted_n_node_samples属性,在适当情况下等于节点的样本数除以样本总数,例如109/200=0.545,[0.08, 0.465]/0.545=[0.147, 0.853]
另一个案例(clf.estimators_[4])是您遇到的情况:
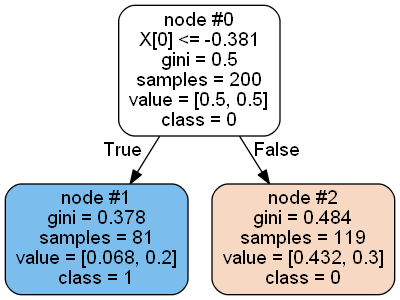
左节点类:[74, 7]
Rignt节点类:[93, 26]
这里的类分布与value无关,左节点甚至可以预测少数类。唯一合适的情况似乎是第一次估计,其他人也有这个问题,也许这是提升过程的一部分?另外,如果你取任何一棵估计树并手动拟合它,你将得到与第一棵树相同的数字。
>>> DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=1,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=441365315, splitter='best').fit(X,y).tree_.value
array([[[100., 100.]],
[[ 84., 7.]],
[[ 16., 93.]]])Stack Overflow用户
发布于 2021-10-23 16:51:31
在AdaBoost中,每个数据点都分配一个权重。最初,所有的权重都是相等的(1/样本总数)。在AdaBoost中,树是按顺序训练的。在对第一棵树进行训练之后,根据第一棵树产生的误差来调整每个数据点的权重。所以,当我们开始训练第二棵树时,数据点的权重是不同的。因此,在这种情况下,值表示每个类的数据点的权重之和。
Stack Overflow用户
发布于 2020-04-23 13:58:33
不知何故,当值数组不是一个平衡的问题时,它表示预期的结果。当模型参数未设置为class_weight = 'Balanced‘时,则该值将给出A类和B类在该节点中的比例;但当模型参数设置为class_weight = 'Balanced’时,则该值将提供意外的输出。
https://stackoverflow.com/questions/54134359
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号