
精度、召回和F1可以是相同的值吗?
精度、召回和F1可以是相同的值吗?
提问于 2019-01-07 03:58:04
我目前正在处理一个ML分类问题,我正在使用sklearn库的以下导入和相应的代码计算精度、召回和sklearn。
from sklearn.metrics import precision_recall_fscore_support
print(precision_recall_fscore_support(y_test, prob_pos, average='weighted'))结果
0.8806451612903226, 0.8806451612903226, 0.8806451612903226对于ML分类问题,是否有可能获得所有3种类型的精度、召回和F1值?
对这方面的任何澄清将不胜感激。
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-01-07 08:05:45
是的,这是可能的。让我们假设二进制分类
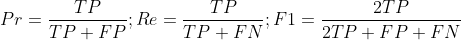
Pr = Re = F1的简单解决方案是TP = 0。因此,我们知道精度,召回和F1可以有相同的值在一般情况下。现在,这不适用于您的特定结果。如果我们求解方程组,我们会找到另一个解:FP = FN。因此,如果假阳性的数量与假阴性的数目相同,那么这三个指标都有相同的值。
对于多类分类问题,我们有
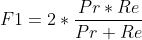
如果是Pr = Re,同样,这三个指标都是相同的。
Stack Overflow用户
发布于 2019-01-07 08:09:00
这似乎是因为期权-平均=‘加权’。
参考:support.html
“加权”:计算每个标签的度量标准,并根据支持(每个标签的真实实例数)找到它们的平均权重。这改变了“宏”来解释标签的不平衡;它可能导致一个不精确和回忆之间的F分数。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54068401
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号