
从DAG提取树木
我有一个DAG表示为节点和它们的后继边。通过一个简单的递归函数,可以将其归为嵌套的数据结构。
#tree1.pl
#!/usr/bin/env perl
use 5.028; use strictures; use Moops; use Kavorka qw(fun); use List::AllUtils qw(first);
class Node :ro {
has label => isa => Str;
has children => isa => ArrayRef[Str];
}
fun N($label, $children) {
return Node->new(label => $label, children => $children);
}
# list is really flat, but
# indentation outlines desired tree structure
our @dag = (
N(N0 => ['N1']),
N(N1 => ['N2']),
N(N2 => ['N3']),
N(N3 => ['N4', 'N5']),
N(N4 => []),
N(N5 => []),
);
fun tree(Node $n) {
return bless [
map {
my $c = $_;
tree(first {
$_->label eq $c
} @dag)
} $n->children->@*
] => $n->label;
}
tree($dag[0]);
# bless([ #N0
# bless([ #N1
# bless([ #N2
# bless([ #N3
# bless([] => 'N4'),
# bless([] => 'N5'),
# ] => 'N3')
# ] => 'N2')
# ] => 'N1')
# ] => 'N0')这是小事一桩。
在我的应用程序中,我遇到了DAG包含具有相同标签的多个节点的复杂性。
our @dag = (
N(N0 => ['N1']),
N(N1 => ['N2']),
︙
N(N1 => ['N6', 'N5']),
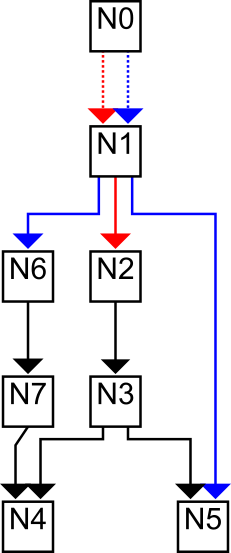
︙请注意,这并不意味着在适当的意义上存在多个边。

这是错误的,因为现在N1似乎有三个平等的孩子。
不能将N1节点折叠到一个节点中进行图遍历,只用于标记输出树;换句话说,这些节点必须具有不同的标识。让我们用颜色来想象这一切。
our @dag = (
N(N0 => ['N1']),
N([N1 => 'red'] => ['N2']),
︙
N([N1 => 'blue'] => ['N6', 'N5']),
︙
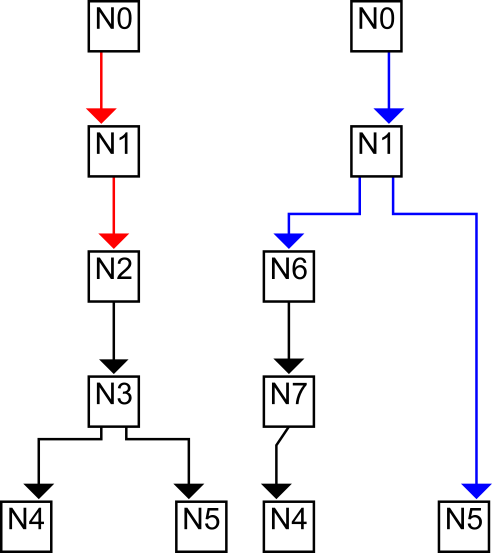
目标是将这个DAG具体化为两棵树。在单独的通道中,遵循每条虚线后继边。实现这一目标的方法是,在传递节点时记住节点上一种颜色的索引数,在下一次树构造期间,我按顺序选择下一种颜色。
#tree2.pl
#!/usr/bin/env perl
use 5.028; use strictures; use Moops; use Kavorka qw(fun); use List::AllUtils qw(first);
class Node :ro {
has label => isa => Str;
has col => isa => Maybe[Str];
has children => isa => ArrayRef[Str];
has col_seen => is => 'rw', isa => Int;
}
fun N($c_l, $children) {
return ref $c_l
? Node->new(label => $c_l->[0], col => $c_l->[1], children => $children)
: Node->new(label => $c_l, children => $children);
}
# indentation outlines desired tree structure
our @dag = (
### start 1st tree
N(N0 => ['N1']),
N([N1 => 'red'] => ['N2']),
N(N2 => ['N3']),
N(N3 => ['N4', 'N5']),
N(N4 => []),
N(N5 => []),
### end 1st tree
### start 2nd tree
# N0
N([N1 => 'blue'] => ['N6', 'N5']),
N(N6 => ['N7']),
N(N7 => ['N4']),
# N4
# N5
### end 2nd tree
);
fun tree(Node $n) {
return bless [
map {
my $c = $_;
my @col = map { $_->col } grep { $_->label eq $c } @dag;
if (@col > 1) {
$n->col_seen($n->col_seen + 1);
die 'exhausted' if $n->col_seen > @col;
tree(first {
$_->label eq $c && $_->col eq $col[$n->col_seen - 1]
} @dag);
} else {
tree(first { $_->label eq $c } @dag);
}
} $n->children->@*
] => $n->label;
}
tree($dag[0]);
# bless([ #N0
# bless([ #N1
# bless([ #N2
# bless([ #N3
# bless([] => 'N4'),
# bless([] => 'N5')
# ] => 'N3')
# ] => 'N2')
# ] => 'N1')
# ] => 'N0')
tree($dag[0]);
# bless([ #N0
# bless([ #N1
# bless([ #N6
# bless([ #N7
# bless([] => 'N4')
# ] => 'N7')
# ] => 'N6'),
# bless([] => 'N5')
# ] => 'N1')
# ] => 'N0')
tree($dag[0]);
# exhausted密码有效,我有两棵树。
但是,当我有几个具有有色后继的节点时,我的代码出现了问题。与上面相同的代码,只是输入不同:
#tree3.pl
︙
our @dag = (
N(N0 => ['N1']),
N([N1 => 'red'] => ['N2']),
N(N2 => ['N3']),
N(N3 => ['N4', 'N5']),
N(N4 => []),
N(N5 => []),
# N0
N([N1 => 'blue'] => ['N6', 'N5']),
N(N6 => ['N7']),
N(N7 => ['N8', 'N4']),
N([N8 => 'purple'] => ['N5']),
# N5
N([N8 => 'orange'] => []),
N([N8 => 'cyan'] => ['N5', 'N5']),
# N5
# N5
# N4
# N5
);
︙
tree($dag[0]);
# bless([ #N0
# bless([ #N1
# bless([ #N2
# bless([ #N3
# bless([] => 'N4'),
# bless([] => 'N5')
# ] => 'N3')
# ] => 'N2')
# ] => 'N1')
# ] => 'N0')
tree($dag[0]);
# bless([ #N0
# bless([ #N1
# bless([ #N6
# bless([ #N7
# bless([ #N8
# bless([] => 'N5')
# ] => 'N8'),
# bless([] => 'N4')
# ] => 'N7')
# ] => 'N6'),
# bless([] => 'N5')
# ] => 'N1')
# ] => 'N0')
tree($dag[0]);
# exhausted问题是搜索只需要两棵树,虽然我应该得到四棵树:
- 红路
- 穿过蓝色,然后是紫色
- 穿过蓝色,然后是橙色
- 穿过蓝色的小路,然后是青色
您可以使用任何编程语言进行回答。
回答 1
Stack Overflow用户
发布于 2019-01-05 04:36:57
以下是你的目标吗?(python 3)
from collections import defaultdict
from itertools import product
class bless:
def __init__(self, label, children):
self.label = label
self.children = children
def __repr__(self):
return self.__str__()
# Just pretty-print stuff
def __str__(self):
formatter = "\n{}\n" if self.children else "{}"
formatted_children = formatter.format(",\n".join(map(str, self.children)))
return "bless([{}] => '{}')".format(formatted_children, self.label)
class Node:
def __init__(self, label, children):
self.label = label
self.children = children
class DAG:
def __init__(self, nodes):
self.nodes = nodes
# Add the root nodes to a singular, generated root node (for simplicity)
# This is not necessary to implement the color-separation logic,
# it simply lessens the number of edge cases I must handle to demonstate
# the logic. Your existing code will work fine without this "hack"
non_root = {child for node in self.nodes for child in node.children}
root_nodes = [node.label for node in self.nodes if node.label not in non_root]
self.root = Node("", root_nodes)
# Make a list of all the trees
self.tree_list = self.make_trees(self.root)
def tree(self):
if self.tree_list:
return self.tree_list.pop(0)
return list()
# This is the meat of the program, and is really the logic you are after
# Its a recursive function that parses the tree top-down from our "made-up"
# root, and makes <bless>s from the nodes. It returns a list of all separately
# colored trees, and if prior (recusive) calls already made multiple trees, it
# will take the cartesian product of each tree per label
def make_trees(self, parent):
# A defaultdict is just a hashtable that's empty values
# default to some data type (list here)
trees = defaultdict(list)
# This is some nasty, inefficient means of fetching the children
# your code already does this more efficiently in perl, and since it
# contributes nothing to the answer, I'm not wasting time refactoring it
for node in (node for node in self.nodes if node.label in parent.children):
# I append the tree(s) found in the child to the list of <label>s trees
trees[node.label] += self.make_trees(node)
# This line serves to re-order the trees since the dictionary doesn't preserve
# ordering, and also restores any duplicated that would be lost
values = [trees[label] for label in parent.children]
# I take the cartesian product of all the lists of trees each label
# is associated with in the dictionary. So if I have
# [N1-subtree] [red-N2-subtree, blue-N2-subtree] [N3-subtree]
# as children of N0, then I'll return:
# [bless(N0, [N1-st, red-N2-st, N3-st]), bless(N0, [N1-st, blue-N2-st, N3-st])]
return [bless(parent.label, prod) for prod in product(*values)]
if __name__ == "__main__":
N0 = Node('N0', ['N1'])
N1a = Node('N1', ['N2'])
N2 = Node('N2', ['N3'])
N3 = Node('N3', ['N4', 'N5'])
N4 = Node('N4', [])
N5 = Node('N5', [])
N1b = Node('N1', ['N6', 'N5'])
N6 = Node('N6', ['N7'])
N7 = Node('N7', ['N8', 'N4'])
N8a = Node('N8', ['N5'])
N8b = Node('N8', [])
N8c = Node('N8', ['N5', 'N5'])
dag = DAG([N0, N1a, N2, N3, N4, N5, N1b, N6, N7, N8a, N8b, N8c])
print(dag.tree())
print(dag.tree())
print(dag.tree())
print(dag.tree())
print(dag.tree())
print(dag.tree())我通过注释相当彻底地解释了逻辑,但只是为了澄清--我一次使用根上的递归DFS生成所有可能的树。为了确保只有一个根,我创建了一个“虚构的”根,它包含没有父节点的所有其他节点,然后在该节点上开始搜索。这不是算法工作所必需的,我只是想简化与你的问题没有直接关系的逻辑。
在这个DFS中,我创建了每个标签列表的哈希表/字典,并存储从这些列表中的每个子列表中可以生成的所有不同的子树。对于大多数节点,此列表的长度为1,因为大多数节点将生成一棵树,除非它们的标签或(子)子节点有重复的标签。无论如何,我采用所有这些列表的笛卡儿积,并形成新的bless对象(从每个产品)。我返回这个列表,这个过程会重复调用堆栈,直到我们最终得到完整的树列表。
所有的打印逻辑都是不必要的(显然),但我想让您更容易地验证这是否确实是您想要的行为。我不能(很容易)将它缩进嵌套的bless,但是手动调整应该很简单。唯一真正感兴趣的部分是make_trees()函数,其余的只是设置用于验证的东西,或者使代码尽可能容易地与我所能管理的perl代码进行比较。
格式化输出:
bless([
bless([
bless([
bless([
bless([
bless([] => 'N4'),
bless([] => 'N5')
] => 'N3')
] => 'N2')
] => 'N1')
] => 'N0')
] => '')
bless([
bless([
bless([
bless([
bless([
bless([
bless([] => 'N5')
] => 'N8'),
bless([] => 'N4')
] => 'N7')
] => 'N6'),
bless([] => 'N5')
] => 'N1')
] => 'N0')
] => '')
bless([
bless([
bless([
bless([
bless([
bless([] => 'N8'),
bless([] => 'N4')
] => 'N7')
] => 'N6'),
bless([] => 'N5')
] => 'N1')
] => 'N0')
] => '')
bless([
bless([
bless([
bless([
bless([
bless([
bless([] => 'N5'),
bless([] => 'N5')
] => 'N8'),
bless([] => 'N4')
] => 'N7')
] => 'N6'),
bless([] => 'N5')
] => 'N1')
] => 'N0')
] => '')
[]
[]https://stackoverflow.com/questions/54010961
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号