
把句子分成新的行
我有一个这种格式的数据集:
The Da Vinci Code book is just awesome.1 this was the first clive cussler i've ever read, but even books like Relic, and Da Vinci code were more plausible than this.1 i liked the Da Vinci Code a lot.1 da vinci code was an awesome movie...1 the last stand and Mission Impossible 3 both were awesome movies.1 mission impossible 2 rocks!!....1 I love Harry Potter, but right now I hate it ( me younger sis's watching it ).1它们是由制表符分隔的,它们之间并不是相互独立的,这意味着在每一行中,都有许多句子,每个句子都有一个电影评论。
我的目标是将每个句子分成一个带有标签的新行(1或0,显示负面/肯定的评论)。我使用了这样的正则表达式:
text_file = open('training.txt', 'r')
file = text_file.readlines()
s = []
for line in file:
s.append(re.findall(r'\!*\.*\d+', line))
print(s)然而,结果是它只显示每句话的标签,而不是我要找的东西。我要找的是:
The Da Vinci Code book is just awesome 1
this was the first clive cussler i've ever read, but even books like Relic, and Da Vinci code were more plausible than this 1
i liked the Da Vinci Code a lot 1
da vinci code was an awesome movie 1
mission impossible 2 rocks 1或者,是否有适合分类的方法,并与熊猫合作?
我怎样才能达到我的目标?
回答 3
Stack Overflow用户
发布于 2019-01-02 02:31:27
UPDATE (Code )删除了我创建的额外列表;这只是一个解决方案。
text_file = open('training.txt', 'r')
file = text_file.readlines()
s = []
a = []
b = []
import re
for line in file:
a = re.match(".*?[^\s][?=(1|0)]",line)
if a == None:
pass
else:
b = a.group()
s.append(b)
print (s) 我使用的数据在文件中如下所示。它只会获得以1或0结尾的评论,并将这些句子添加到列表中。
虚拟数据
试验数据
测试错误数据
将添加一些正确的数据进行测试。
“达芬奇密码书”简直令人敬畏。
这是我读过的第一本克莱夫·库斯勒,但即使是像遗物和达芬奇密码这样的书也比这更可信。
我喜欢达芬奇密码。达芬奇密码是一部很棒的电影.
最后一个看台和“不可能的任务3”都是很棒的电影。
任务不可能2块石头!!....1
我爱哈利波特,但现在我讨厌它(我妹妹在看).1
结果
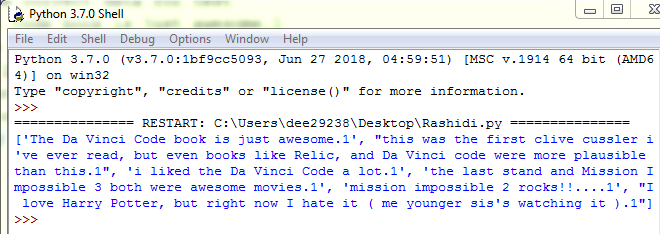
Stack Overflow用户
发布于 2019-01-01 09:37:41
Stack Overflow用户
发布于 2019-01-01 09:59:12
你可以这样做:
import re
text_file = open('training.txt', 'r')
str_file = text_file.readlines()
p = re.compile("[ \t]{2,}") # regex for 2 or more spaces
s = p.split(str_file[0])
print(s) 更新代码(使用readlines(),因为不知道training.txt的实际内容/格式):
import re
text_file = open('training.txt', 'r')
str_file = text_file.readlines()
p = re.compile("[ \t]{2,}") # regex for 2 or more spaces
s = p.split(str_file[0])
print(s) 它产生了这样一个list of strings:
['The Da Vinci Code book is just awesome.1', "this was the first clive cussler i've ever read, but even books like Relic, and Da Vinci code were more plausible than this.1", 'i liked the Da Vinci Code a lot.1', 'da vinci code was an awesome movie...1', 'the last stand and Mission Impossible 3 both were awesome movies.1', 'mission impossible 2 rocks!!....1', "I love Harry Potter, but right now I hate it ( me younger sis's watching it ).1"]https://stackoverflow.com/questions/53994357
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号