
元素词位置.概念问题
我试图理解element word positions索引设置的影响。请参见以下xquery,它返回简单element-word-query搜索的计划:
xdmp:plan(cts:search(doc(),
cts:and-query(
cts:element-word-query(xs:QName("name"), "element word position")
),
("unfiltered")
))如果索引未被激活,则为final-plan (节省空间的简化形式):
<qry:and-query>
<qry:term-query>element(name),pair(word("element"),word("word"))</qry:term-query>
<qry:term-query>element(name),pair(word("word"),word("position"))</qry:term-query>
<qry:term-query>word("element")</qry:term-query>
<qry:term-query>word("word")</qry:term-query>
<qry:term-query>word("position")</qry:term-query>
</qry:and-query>索引激活后的查询计划(word-positions和element word positions):
<qry:and-query>
<qry:term-query>element(name),pair(word("element"),word("word"))</qry:term-query>
<qry:term-query>element(name),pair(word("word"),word("position"))</qry:term-query>
<qry:element-query>
element(name)
<qry:word-query>
<qry:KP pos="0">word("element")</qry:KP>
<qry:KP pos="1">word("word")</qry:KP>
<qry:KP pos="2">word("position")</qry:KP>
</qry:word-query>
</qry:element-query>
</qry:and-query>因此,我假设,由于生成的term-query要少得多,因此产生的候选片段id计数会更小,因此索引分辨率的交集会更快。除此之外,我真的很想了解element-query是如何在引擎盖下工作的。所以我有几个问题:
- 如果
element word positions被激活,索引中保存了什么样的附加信息? - 索引和张贴列表会是什么样的呢?键是元素还是element+word组合?是否有任何图形资源来可视化它?(不希望你画东西)
- 另外,
element-query是如何执行的?我看到一个简单的term-query是如何返回键这个词的投递列表的,但我不知道如何计算一个以word-query作为“子查询”的element-query。
编辑:添加了一张图片,以使我对启用元素字位置时索引的理解可视化。(详情见mholstege的答覆)
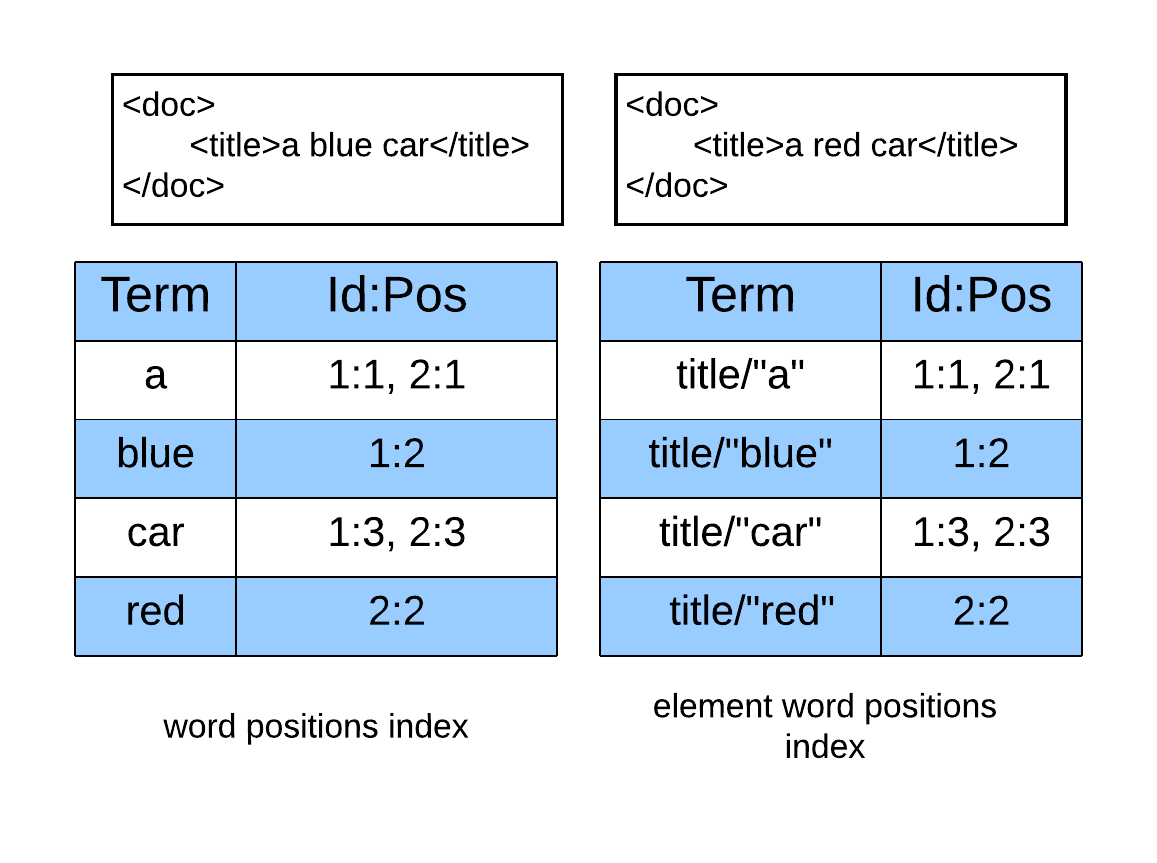
回答 1
Stack Overflow用户
发布于 2018-12-28 15:31:12
当您打开位置时,我们会在索引中存储每个文档的位置向量,而不仅仅是文档id。
考虑这一点的方法是考虑叶查询的特殊性,以及计算它们和交叉中间结果所涉及的工作。
当您在查询计划中看到一个术语--查询时,这意味着它只是在查找文档in,因此没有相对位置的知识--这样的长短语的结果不太准确,因为“元素word”和"word位置“可能发生在文档中的两个单独的父元素中。如果您的数据在每个文档中只有一个具有此名称的元素,则不可能发生这种情况,尽管您仍然可能有错误的匹配,其中两个单词的子短语以相反的顺序出现,或者由其他词分隔。
当您在查询计划中看到单词查询时,这意味着我们将查看位置,这里您将看到短语中每个单词的相对位置。当这个问题被解决后,我们将检查位置向量,并抛出那些并不意味着位置约束的位置向量。所以所有的匹配都会按照这个顺序排列:一个更精确的匹配。
计划中的元素查询也在应用相对于元素内部匹配的元素实例的位置约束。有一些优化,其中元素位置约束实际上被推倒到查询树的叶子上,以避免过多的中间计算。
您还会看到一些技术上多余的术语查询:这些查询的目的是进行简单的术语查找,这些查找可能比叶词查询更受限制。由于来自和查询的术语列表的交集总是来自最短匹配的公告列表,这可以提供一种防止失败的机制,以避免更昂贵的位置计算。在这方面有一定的启发式判断,并且给定一组复杂的索引选项和查询变化,有时这些附加的术语实际上是没有帮助的。
https://stackoverflow.com/questions/53948303
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号