
YOLO和滑动窗算法的输出向量
正如我在YOLO算法中所理解的,我们将inuput图像划分为一个网格,例如19x19,我们必须对每个单元有输出矢量(pc,bx,by,bw,c)。然后我们就可以训练我们的网络了。我的问题是:为什么我们给网络XML文件只有一个边框、标签等(如果只有一个对象在图像上),而不是给19*19=361文件?网络的实现是否自动分割图像并为每个单元创建向量?(它是如何做到的?)
同样的问题也适用于滑动窗口算法。为什么我们只给网络一个带标签和包围框的向量,而不是给出每个滑动窗口的向量。
回答 1
Stack Overflow用户
发布于 2018-12-28 14:01:10
假设YOLO的输出由19×19个网格单元组成,每个网格单元都有一定的深度。每个网格单元可以检测到一些边界框,其最大数目取决于模型的配置。例如,如果一个网格单元可以检测最多5个边界框,则模型总共可以检测到19x19x5 = 1805个边界框。
由于这个数目太大,我们对模型进行了训练,使得只包含包围盒中心的网格单元,预测的边界盒具有很高的可信度。当我们训练模型时,我们首先找出真正的包围盒的中心落在哪里,然后训练模型,使包含中心的网格单元预测一个与高概率的真实包围盒类似的包围盒,这样其他网格单元将尽可能低概率地预测包围盒(当概率低于阈值时,这一预测就被丢弃)。
下面的图像显示了当输出有13×13个网格单元时,包含盒中心的网格单元。
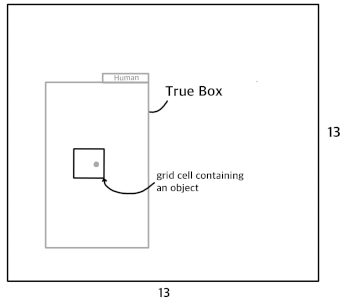
当训练图像中有多个对象时,情况也是一样的。如果训练图像中有两个对象,则更新包含真实两个框中心的两个网格单元,从而生成高概率的包围盒。
https://stackoverflow.com/questions/53937814
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号