
小批RL
我刚刚读了Mnih (2013)的报纸,我真的很想知道他所说的使用RMSprop和32大小的小型机的方面(第6页)。
我对这类强化学习算法的理解是,每一次训练只有一个或至少很少的训练样本,在每一次训练中我都更新网络。而在监督学习中,我有多达数百万个样本,并将它们分成小批,例如32,然后在每一小批之后更新网络,这是有意义的。
所以我的问题是:如果我一次只把一个样本放入神经网络,那么小型批次又有什么意义呢?我明白这个概念有什么不对吗?
提前感谢!
回答 2
Stack Overflow用户
发布于 2018-12-20 15:34:11
本文介绍了用深度神经网络函数逼近器来稳定Q学习方法的两种机制。其中一种机制叫做经验回放,它基本上是观察到的经验的记忆缓冲器。你可以在第四页的末尾找到论文中的描述。与其从您刚才看到的单一体验中学习,不如将其保存到缓冲区中。学习是每N次迭代完成的,您可以从回放缓冲区中随机抽取一小批体验。
Stack Overflow用户
发布于 2018-12-20 16:47:28
菲利普的回答是正确的。只是为了增加他的答案的直觉,一个经验重播被使用的原因是去整理RL所经历的经验。当使用非线性函数逼近(如神经网络)时,这是必不可少的.
试想一下,如果你有10天的时间来参加化学和数学考试,而这两次考试都在同一天进行。如果你把头5天花在化学上,花5天在数学上,你就会忘记大部分你学过的化学。神经网络的行为类似。
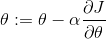
通过整理经验,可以通过培训数据确定更一般的策略。
在训练神经网络的过程中,我们有一批记忆(即数据),我们从它们中随机抽取32个小批的样本进行监督学习,就像其他神经网络被训练一样。
https://stackoverflow.com/questions/53864434
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号