
关于RetinaNet的困惑
我最近一直在学习RetinaNet。我读了原始的报纸和一些相关的文章,并写了一篇文章分享我所学到的:http://blog.zenggyu.com/en/post/2018-12-05/retinanet-explained-and-demystified/。然而,我仍然有一些困惑,我在文章中也指出了这一点。有人能指点我吗?
混淆#1
正如论文所指出的,如果锚盒的IoU值低于0.4,它就会被分配到背景中。在这种情况下,对应的分类目标标签应该是什么(假设有K类)?
我知道SSD有一个背景类(这使K+1类总数),而YOLO则预测除了K类概率之外,方框中是否有对象(不是背景)的置信度分数。虽然我在论文中没有发现任何说明RetinaNet包含背景类的语句,但我确实看到了这样的说法:“.我们只在阈值检测器置信度为0.05之后,从.解码盒预测”,这似乎表明有信心评分的预测。然而,这个分数从何而来(因为分类子网只输出表示K类概率的K个数字)?
如果RetinaNet定义的目标标签与SSD或YOLO不同,我假设目标是一个长度-K向量,包含所有的0项,没有1s。然而,在这种情况下,焦点损失(见下面的定义)将如何惩罚锚,如果它是一个假阴性?
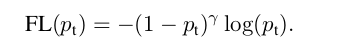
哪里
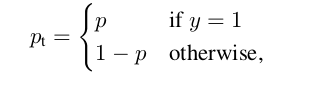
混淆#2
与许多其他检测器不同,RetinaNet使用一个与类无关的边界盒回归器,分类子网最后一层的激活是sigmoid激活。这是否意味着一个锚盒可以同时预测不同类的多个对象?
混淆#3
让我们将这些匹配的锚盒和地面真相盒表示为${(A^i,G^i)}_{i=1,...N}$,其中$A$代表锚,$G$代表地面真理,$N$代表匹配数。
对于每个匹配的锚点,回归子网预测四个数字,我们表示为$P^i = (P^i_x,P^i_y,P^i_w,P^i_h)$。前两个数字指定锚点$A^i$中心与地面真相$G^i$之间的偏移量,而后两个数字指定锚的宽度/高度与地面真相之间的偏移量。相应地,对于每一种预测,都有一个回归目标$T^i$,作为锚点和地面真相之间的偏移:
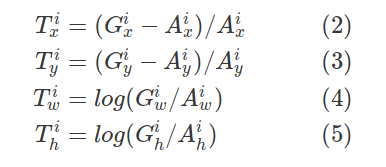
上述方程式正确吗?
请提前表示感谢,并随时指出帖子中的任何其他误解!
更新:
作为将来的参考,我在学习RetinaNet时遇到的另一个困惑(我发现这个对话是松弛的):

回答 1
Stack Overflow用户
发布于 2018-12-17 11:26:11
我是开源维甲酸项目( fizyr/keras-视黄醇 )的作者之一。我会尽我所能回答你的问题。
混淆#1
在对象检测器中,通常有两种常用的分类方法,一种是使用softmax,另一种是使用sigmoid。
如果您使用softmax,目标值应该始终是一个热门向量,这意味着如果没有对象,您应该将它“分类”为背景(意味着您需要一个背景类)。好处是,你的班级成绩总是总和为一。
如果使用sigmoid,则约束较少。在我看来,这有两个好处,您不需要背景类(这使实现更加简洁),并且它允许网络进行多类分类(虽然我们的实现不支持它,但理论上是可能的)。一个小的额外好处是,您的网络稍微小一些,因为它需要分类比softmax少一个类,虽然这可能是否定的。
在实现支持集的早期,由于py-更快-rcnn的遗留代码,我们使用了softmax。我联系了焦点丢失文件的作者,并询问他关于softmax/sigmoid的情况。他的回答是,这是个人偏好的问题,如果你使用其中一种或另一种并不重要。因为上面提到的乙状体的好处,现在它也是我个人的喜好。
然而,这个分数从何而来(因为分类子网只输出表示K类概率的K个数字)?
每个类的分数都被视为自己的对象,但是对于一个锚,它们都共享相同的回归值。如果类分数超过了这个阈值(我敢肯定是任意选择的),那么它就被认为是一个候选对象。
如果RetinaNet定义的目标标签与SSD或YOLO不同,我假设目标是一个长度-K向量,包含所有的0项,没有1s。然而,在这种情况下,焦点损失(见下面的定义)将如何惩罚锚,如果它是一个假阴性?
底片被归类为只包含零的向量。阳性按一个热向量分类。假设预测是所有零的向量,但目标是一个热向量(换句话说,是假负值),那么p_t是公式中的零列表。焦距损失将评估到该锚的一个很大的价值。
混淆#2
简短回答:是的。
混淆#3
关于最初的实现,它几乎是正确的。所有值都被width或height除以。用A_x、A_y除以T_x和T_y的值是不正确的。
尽管如此,不久以前,我们转向了一个稍微简单一些的实现,即将回归计算为左上角和右下角点之间的差值(作为w.r.t的分数)。锚的宽度和高度)。这就简化了实现,因为我们在整个代码中使用了左上角/右下角。此外,我注意到我们的结果稍微增加了可可。
https://stackoverflow.com/questions/53809995
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号