
循环生成R中日期之间的月份
循环生成R中日期之间的月份
提问于 2018-12-07 16:34:27
我有一个数据框架,它有三列雇用,开始日期(Ydm)和结束日期(Ydm)。我的目标是创建另一个有两个列的数据框架,一个是员工ID,另一个是日期。第二个数据框架将围绕第一个数据框架构建,以便从第一个数据框架获取it,列日期将占用该员工的开始日期和结束日期之间的所有月份。简单地说,我会根据员工的开始日期和结束日期将第一个数据帧中的数据按月展开。
实际上,我成功地创建了代码,使用for循环。问题是,它非常慢,在我读到的一些地方,是为了避免r中的循环,有没有一种方法可以更快地做到这一点呢?
下面是我的数据框架和代码的示例:
# Creating Data frame
a<- data.frame(employeeid =c('a','b','c'), StartDate= c('2018-1-1','2018-1-5','2018-11-2'),
EndDate= c('2018-1-3','2018-1-9','2018-1-8'), stringsAsFactors = F)
a$StartDate <- ydm(a$StartDate)
a$EndDate <- ydm(a$EndDate)
#second empty data frame
a1 <-a
a1 <- a1[0,1:2]
#my code starts
r <- 1
r.1 <- 1
for (id in a$employeeid) {
#r.1 <- 1
for ( i in format(seq(a[r,2],a[r,3],by="month"), "%Y-%m-%d") ) {
a1[r.1,1] <- a[r,1]
a1[r.1,2] <- i
r.1 <- r.1 +1
}
r <- r+1
} 其结果是:
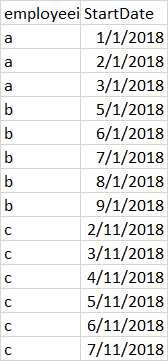
我想要同样的结果,但要快一点。
回答 4
Stack Overflow用户
回答已采纳
发布于 2018-12-07 19:47:44
几乎是tidyverse的一条线
> result
# A tibble: 12 x 2
employeeid date
<chr> <date>
1 a 2018-01-01
2 a 2018-02-01
3 a 2018-03-01
4 b 2018-05-01
5 b 2018-06-01
6 b 2018-07-01
7 b 2018-08-01
8 b 2018-09-01
9 c 2018-11-01
10 c 2018-12-01
11 c 2019-01-01
12 c 2019-02-01代码
result <- df %>%
group_by(employeeid) %>%
summarise(date = list(seq(StartDate,
EndDate,
by = "month"))) %>%
unnest()数据
library(tidyverse)
library(lubridate)
df <- data.frame(employeeid = c('a', 'b', 'c'),
StartDate = ymd(c('2018-1-1', '2018-5-1', '2018-11-1')),
EndDate = ymd(c('2018-3-1', '2018-9-1', '2019-02-1')),
stringsAsFactors = FALSE)Stack Overflow用户
发布于 2018-12-07 17:24:03
我试图通过使用apply和一个自定义函数来解决这个问题,该函数计算end和start的差异。
我不确定您想要的输出是什么样子,但是在下面的示例函数中,在开始和结束之间的整个月都被粘贴在一个字符串中。
library(lubridate)
# Creating Data frame
a<- data.frame(employeeid =c('a','b','c'), StartDate= c('2018-1-1','2018-1-5','2018-11-2'),
EndDate= c('2018-2-3','2019-1-9','2020-1-8'), stringsAsFactors = F)
a$StartDate <- ymd(a$StartDate)
a$EndDate <- ymd(a$EndDate)
# create month-name month nummeric value mapping
month_names = month.abb[1:12]
month_dif = function(dates) # function to calc the dif. it expects a 2 units vector to be passed over
{
start = dates[1] # first unit of the vector is expected to be the start date
end = dates[2] # second unit is expected to be the end date
start_month = month(start)
end_month = month(end)
start_year = year(start)
end_year = year(end)
year_dif = end_year - start_year
if(year_dif == 0){ #if start and end both are in the same year month is start till end
return(paste(month_names[start_month:end_month], collapse= ", " ))
} else { #if there is an overlap, mont is start till dezember and jan till end (with x full year in between)
paste(c(month_names[start_month:12],
rep(month_names, year_dif-1),
month_names[1:end_month]), collapse = ", ")
}
}
apply(a[2:3], 1, month_dif) 产出:
> apply(a[2:3], 1, month_dif)
[1] "Jan, Feb"
[2] "Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec, Jan"
[3] "Nov, Dec, Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec, Jan"Stack Overflow用户
发布于 2018-12-07 18:32:01
您可以使用apply和do.call的组合
out_apply_list <- apply(X=a, MARGIN=1,
FUN=function(x) {
data.frame(id= x[1],
date=seq(from = as.Date(x[2], "%Y-%d-%m"),
to = as.Date(x[3], "%Y-%d-%m"),
by = "month"),
row.names = NULL)
})
df <- do.call(what = rbind, args = out_apply_list)它提供了以下输出:
> df
id date
1 a 2018-01-01
2 a 2018-02-01
3 a 2018-03-01
4 b 2018-05-01
5 b 2018-06-01
6 b 2018-07-01
7 b 2018-08-01
8 b 2018-09-01
9 c 2018-02-11
10 c 2018-03-11
11 c 2018-04-11
12 c 2018-05-11
13 c 2018-06-11
14 c 2018-07-11页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53673520
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号