
Server:在UNION ALL查询中具有多个索引的优化器智能
我试图为一个相当大的表编写一个查询(10 million+将是一个典型的大小),其结果需要根据某些业务逻辑在各种谓词/条件上进行过滤。我的问题是:查询优化器(在Server 2008+中)是尝试对整个查询使用单个索引,还是尝试在按查询的基础上使用不同的索引?
请考虑以下几点:
--Use Index A
SELECT Set1
FROM ATable
WHERE AColumn = sarg-able value
UNION ALL
--Are we stuck with Index A?
SELECT Set2
FROM ATable
WHERE BColumn = sarg-able value如果我们为Set1选择索引A,那么我们是为整个查询选择索引A,还是优化器足够聪明地为Set2使用不同的索引(假设存在索引)?
回答 2
Stack Overflow用户
发布于 2018-12-03 21:45:28
“万事俱备”,安德里·尼可洛夫说的都是100%正确的。通过查看实际的执行计划(而不是估计的执行计划),您可以轻松地了解这类事情。请注意以下示例数据、表和索引结构:
USE tempdb -- safe place in Dev to test this kind of thing...
GO
-- sample data and indexes
IF OBJECT_ID('dbo.ATable','U') IS NOT NULL DROP TABLE dbo.ATable
CREATE TABLE dbo.ATable
(
Set1 INT NOT NULL,
Set2 INT NOT NULL,
AColumn INT NOT NULL,
BColumn INT NOT NULL
);
INSERT dbo.ATable (Set1, Set2, AColumn, BColumn)
VALUES (1,2,3,3),(1,2,4,4),(5,5,6,6),(11,22,40,40),(11,20,40,44),(11,22,14,4),(1,2,3,3);
CREATE NONCLUSTERED INDEX indexA ON dbo.ATable(AColumn) INCLUDE(Set1);
CREATE NONCLUSTERED INDEX indexB ON dbo.ATable(BColumn) INCLUDE(Set2);现在,在打开“包括实际执行计划”的情况下运行以下操作。
SELECT Set1 --Use Index A
FROM dbo.ATable
WHERE AColumn = 3
UNION ALL
SELECT Set2 --Use Index B
FROM dbo.ATable
WHERE BColumn = 4;..。以及执行计划:
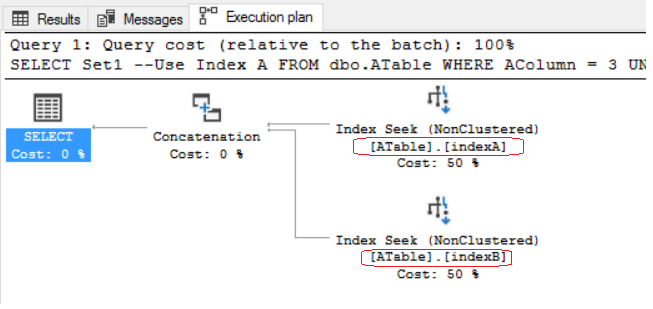
上面的查询都针对IndexA的键列()执行一个非集群的查找 (AColumn)。因为我将Set1作为IndexA上的一个包含列,所以IndexA可以满足查询,而无需对其进行Rid或键查找。这就是应该如何设计索引。除了使用IndexB之外,UNION下面的查询也是如此。
同样,一旦你对如何阅读执行计划有了充分的理解,就很容易自己弄明白这类事情。
Stack Overflow用户
发布于 2018-12-03 18:45:11
是的,优化器很聪明。这是两个独立的操作,可以作为表/索引扫描执行,也可以作为查找执行。执行每个索引的决策是独立的,对每个索引使用不同的索引是完全正常的。然后,这两个操作的结果将被合并。
https://stackoverflow.com/questions/53599788
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号