
循环通过数据集计算分叉
循环通过数据集计算分叉
提问于 2018-11-29 19:48:49
我有这样的数据集:
set.seed(1345)
df<-data.frame(month= c(rep(1,10), rep(2, 10), rep(3, 10)),
species=sample(LETTERS[1:10], 30, replace= TRUE))我想每个月循环一遍,计算物种多样性。我知道像diversity in library("vegan")这样的函数,并且知道使用这个路径(下面提供的代码)来解决我的问题,但是作为一个循环的练习,我试图创建一个for loop或函数来显示Shannons多样性和辛普森多样性的具体计算,这样每个索引的计算就不再神秘了。它们是使用下列公式计算的:
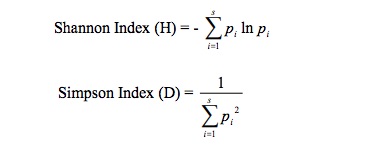
到目前为止,我已经为辛普森做了以下尝试:
df <-
df %>%
group_by(month, species) %>%
summarise(freq = n())
div<-NA
for (i in length(unique(df$month))) {
sum<- sum(df$freq)
for (i in unique (df$freq)){
p<- df$freq /sum
p.sqrd<-p*p
div[i]<-1/sum(p.sqrd)
}}以下是香农的故事:
df <-
df %>%
group_by(month, species) %>%
summarise(freq = n())
div<-NA
for (i in length(unique(df$month))) {
sum<- sum(df$freq)
for (i in unique (df$freq)){
p<- df$freq /sum
log.p<-ln(p)
div[i]<- sum(p[i]*ln(p[i]))
}}我不是在创建一个成功的循环,我希望帮助正确地索引这个循环,并创建一个效率最高的循环(即将df <- df %>% group_by(month, species) %>% summarise(freq = n())合并到循环中)和一个非常清楚地说明了循环中的方程的for循环。
使用diversity函数,以下是辛普森多样性的答案:
library("tidyverse")
df <-
df %>%
group_by(month, species) %>%
summarise(freq = n())
# Cast dataframe of interaction frequencies into a matrix
library("reshape2")
ph_mat<- dcast(df, month~ species)
ph_mat[is.na(ph_mat)] <- 0 #changes
library("vegan")
df<- data.frame(div=diversity(ph_mat, index="simpson"),
month=unique(ph_mat$month))对Shannons来说:
library("vegan")
df<- data.frame(div=diversity(ph_mat, index="shannon"),
month=unique(ph_mat$month))回答 1
Stack Overflow用户
回答已采纳
发布于 2018-11-29 20:09:05
这里我有一个不包含for循环的解决方案,但是我定义并解释了一个函数来计算每个索引(没有什么神秘的!)它计算每个月的每个多样性度量。它使用来自group_by()和summarize()的dplyr函数。
set.seed(1345)
df<-data.frame(month= c(rep(1,10), rep(2, 10), rep(3, 10)),
species=sample(LETTERS[1:10], 30, replace= TRUE))
calc_shannon <- function(community) {
p <- table(community)/length(community) # Find proportions
p <- p[p > 0] # Get rid of zero proportions (log zero is undefined)
-sum(p * log(p)) # Calculate index
}
calc_simpson <- function(community) {
p <- table(community)/length(community) # Find proportions
1 / sum(p^2) # Calculate index
}
diversity_metrics <-
df %>%
group_by(month) %>%
summarize(shannon = calc_shannon(species),
simpson = calc_simpson(species))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53546514
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号