
单词列表中最长的单词链
所以,这是我想做的一个功能的一部分。
我不想密码太复杂。
我有一个单词列表。
words = ['giraffe', 'elephant', 'ant', 'tiger', 'racoon', 'cat', 'hedgehog', 'mouse']单词链序列的概念是下一个单词以最后一个单词结尾的字母开始。
(编辑:每个单词不能多用一次。(除此之外,没有其他限制。)
我希望输出给出最长的单词链序列,在本例中是:
['hedgehog', 'giraffe', 'elephant', 'tiger', 'racoon']我真的不知道该怎么做,我试过不同的尝试。其中之一..。
如果我们从列表中的一个特定单词开始,例如单词长颈鹿,这段代码将正确地找到单词链
words = ['giraffe', 'elephant', 'ant', 'tiger', 'racoon', 'cat', 'hedgehog', 'mouse']
word_chain = []
word_chain.append(words[0])
for word in words:
for char in word[0]:
if char == word_chain[-1][-1]:
word_chain.append(word)
print(word_chain)输出:
['giraffe', 'elephant', 'tiger', 'racoon']但是,我想找到最长的可能的词链(上文解释)。
My method:所以,我尝试使用上面我编写的工作代码并循环通过,使用列表中的每个单词作为起点,并为每个单词找到单词链,word1、word2等。然后我尝试使用if语句来查找最长的单词链,并将其长度与前一个最长的链进行比较,但是我无法正确地完成它,我也不知道这是怎么回事。
words = ['giraffe', 'elephant', 'ant', 'tiger', 'racoon', 'cat', 'hedgehog', 'mouse']
word_chain = []
max_length = 0
for starting_word_index in range(len(words) - 1):
word_chain.append(words[starting_word_index])
for word in words:
for char in word[0]:
if char == word_chain[-1][-1]:
word_chain.append(word)
# Not sure
if len(word_chain) > max_length:
final_word_chain = word_chain
longest = len(word_chain)
word_chain.clear()
print(final_word_chain)这是我的第九次尝试,我认为这一次打印一个空列表,在此之前我做过不同的尝试,未能正确清除word_chain列表,最后又重复了一遍。
任何帮助都很感激。希望我没有把这件事弄得太含糊不清.谢谢!
回答 9
Stack Overflow用户
发布于 2018-11-26 16:23:01
当将包含适当初始字符的每个可能的字母添加到运行列表中时,您可以使用递归来探索出现的每个“分支”:
words = ['giraffe', 'elephant', 'ant', 'tiger', 'racoon', 'cat', 'hedgehog', 'mouse']
def get_results(_start, _current, _seen):
if all(c in _seen for c in words if c[0] == _start[-1]):
yield _current
else:
for i in words:
if i[0] == _start[-1]:
yield from get_results(i, _current+[i], _seen+[i])
new_d = [list(get_results(i, [i], []))[0] for i in words]
final_d = max([i for i in new_d if len(i) == len(set(i))], key=len)输出:
['hedgehog', 'giraffe', 'elephant', 'tiger', 'racoon']该解决方案的工作方式类似于广度优先搜索,因为只要以前没有调用当前值,get_resuls函数就会继续遍历整个列表。函数看到的值被添加到_seen列表中,最终停止递归调用流。
此解决方案还将忽略重复的结果:
words = ['giraffe', 'elephant', 'ant', 'ning', 'tiger', 'racoon', 'cat', 'hedgehog', 'mouse',]
new_d = [list(get_results(i, [i], []))[0] for i in words]
final_d = max([i for i in new_d if len(i) == len(set(i))], key=len)输出:
['ant', 'tiger', 'racoon', 'ning', 'giraffe', 'elephant']Stack Overflow用户
发布于 2018-11-27 03:26:03
我有一个新想法,如图所示:
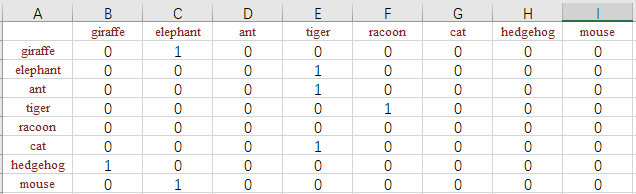
我们可以逐字构造有向图== word-1,然后将该问题转化为求最大长度路径。
Stack Overflow用户
发布于 2018-11-27 08:02:38
正如其他人所提到的,问题是如何找到有向无圈图的最长路径。
对于与Python相关的任何图形,网络都是您的朋友。
您只需初始化图形、添加节点、添加边缘并启动dag_longest_path
import networkx as nx
import matplotlib.pyplot as plt
words = ['giraffe', 'elephant', 'ant', 'tiger', 'racoon', 'cat',
'hedgehog', 'mouse']
G = nx.DiGraph()
G.add_nodes_from(words)
for word1 in words:
for word2 in words:
if word1 != word2 and word1[-1] == word2[0]:
G.add_edge(word1, word2)
nx.draw_networkx(G)
plt.show()
print(nx.algorithms.dag.dag_longest_path(G))

它的产出如下:
['hedgehog', 'giraffe', 'elephant', 'tiger', 'racoon']注意:只有在图中没有循环(循环)时,此算法才能工作。这意味着它将在['ab', 'ba']中失败,因为会有一条无限长的路径:['ab', 'ba', 'ab', 'ba', 'ab', 'ba', ...]
https://stackoverflow.com/questions/53485052
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号