
Web抓取python不返回任何内容
我正在尝试从"https://data.lacity.org/A-Safe-City/Crime-Data-from-2010-to-Present/y8tr-7khq“中搜索网页。具体来说,在div类=“s格拉ata表冻结-列”下,所有的数据列名称&数据列描述。但是,我编写的代码似乎不起作用(它没有返回任何内容?)
import requests
from bs4 import BeautifulSoup
url = "https://data.lacity.org/A-Safe-City/Crime-Data-from-2010-to-Present/y8tr-7khq"
page = requests.get(url)
print(page.status_code)
soup=BeautifulSoup(page.content,'html.parser')
for col in soup.find_all("div", attrs={"class":"socrata-visualization-container loaded"})[0:1]:
for tr in col.find_all("div",attrs={"class":"socrata-table frozen-columns"}):
for data in tr.find_all("div",attrs={"class":"column-header-content"}):
print(data.text)我的代码错了吗?
回答 3
Stack Overflow用户
发布于 2018-11-25 18:45:52
页面是动态加载的,数据集是分页的,这意味着使用浏览器自动检索,这是缓慢的。有一个API可以使用。它有参数,允许您以批形式返回结果。
阅读API文档这里。这将是一种更有效、更可靠的数据检索方法。
使用limit确定一次检索的#记录;使用offset参数开始新记录的下一批处理。打电话给这里。
由于这是一个查询,因此实际上可以调整其他参数,就像SQL查询一样,可以检索所需的结果集。这也意味着您可能会编写一个非常快速的初始查询来从数据库返回记录计数,您可以使用它来确定批处理请求的终结点。
您可以编写一个基于类的脚本,它使用多处理并更有效地抓取这些批。
import requests
import pandas as pd
from pandas.io.json import json_normalize
response = requests.get('https://data.lacity.org/api/id/y8tr-7khq.json?$select=`dr_no`,`date_rptd`,`date_occ`,`time_occ`,`area_id`,`area_name`,`rpt_dist_no`,`crm_cd`,`crm_cd_desc`,`mocodes`,`vict_age`,`vict_sex`,`vict_descent`,`premis_cd`,`premis_desc`,`weapon_used_cd`,`weapon_desc`,`status`,`status_desc`,`crm_cd_1`,`crm_cd_2`,`crm_cd_3`,`crm_cd_4`,`location`,`cross_street`,`location_1`&$order=`date_occ`+DESC&$limit=100&$offset=0')
data = response.json()
data = json_normalize(data)
df = pd.DataFrame(data)
print(df)JSON响应中的示例记录:
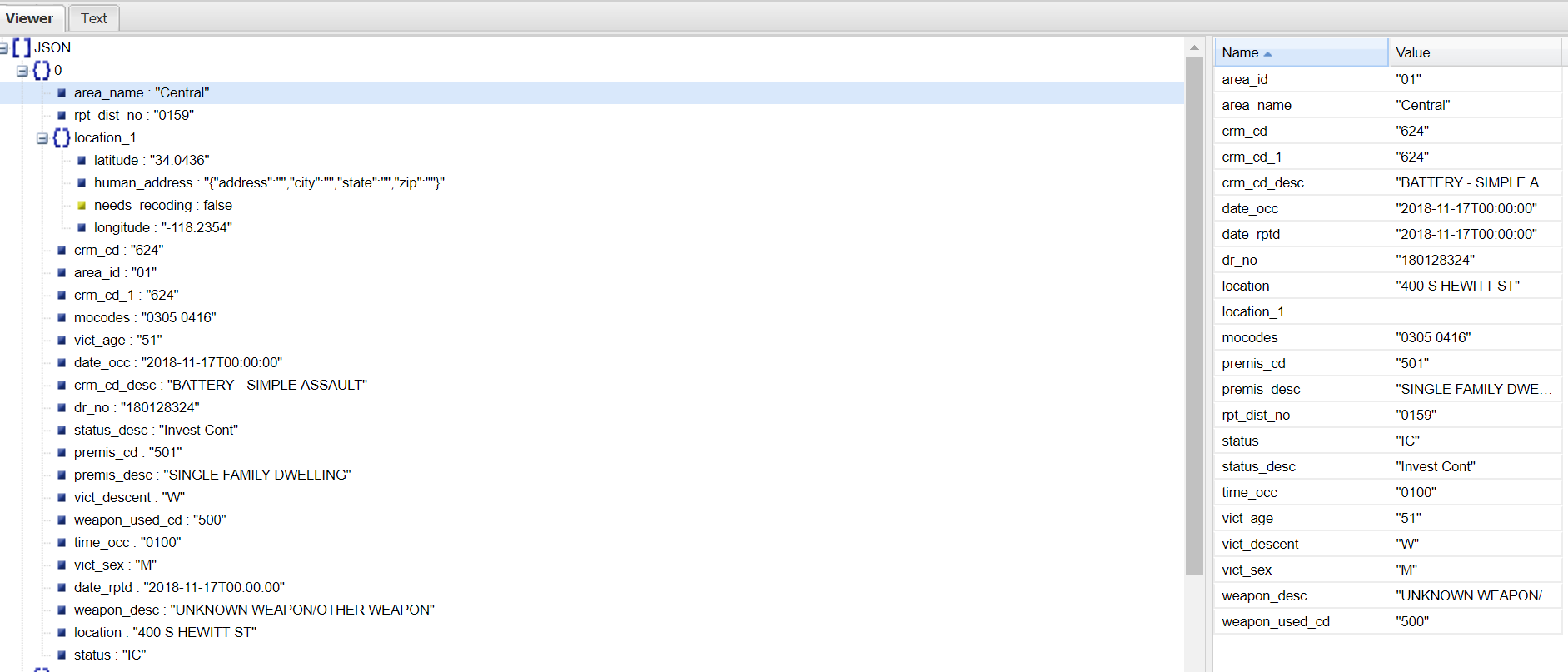
Stack Overflow用户
发布于 2018-11-25 18:17:24
如果您查看页面源(ctrl + U),您会注意到没有像<div class = "socrata-table frozen-columns">这样的元素。这是因为您想要删除的内容是动态添加到页面中的。查看以下问题:用python抓取动态内容或Web使用动态javascript内容抓取网站
Stack Overflow用户
发布于 2018-11-25 18:21:35
https://stackoverflow.com/questions/53470370
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号