
用Pandas计算NPS
用Pandas计算NPS
提问于 2018-11-22 07:43:17
我对Python非常非常陌生,我正在考虑如何计算NPS分数。
计算结果如下:
(记分9-10/总分0-10) -(记分0-6/总分0-10分)
我正在使用的数据框架:
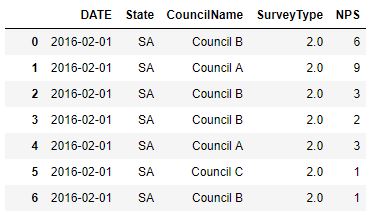
需要分别计算每个理事会的核动力源。这是我在这里的第一篇文章,希望这是有意义的。如果有人能为我指明正确的方向,我将不胜感激。
干杯,本。
回答 2
Stack Overflow用户
回答已采纳
发布于 2018-11-22 07:57:46
假设数据在data.csv中
import pandas as pd
from collections import defaultdict
df = pd.read_csv('data.csv')
high_nps = defaultdict(lambda: 0)
low_nps = defaultdict(lambda: 0)
high_nps.update(dict(df[df['NPS'] >= 9].groupby('CouncilName').count().reset_index()[['CouncilName', 'NPS']].values))
low_nps.update(dict(df[df['NPS'] <= 6].groupby('CouncilName').count().reset_index()[['CouncilName', 'NPS']].values))
total_nps = dict(df.groupby('CouncilName').count().reset_index()[['CouncilName', 'NPS']].values)
nps_score = {council: (high_nps[council] - low_nps[council]) / float(total_nps[council]) for council in total_nps}
print(nps_score)指纹:
{'Council A': 0.0, 'Council B': -1.0, 'Council C': -1.0}Stack Overflow用户
发布于 2020-05-27 00:29:54
def npsForField(df,column,fid):
nps={}
# first make sure our column has numeric values:
subject = pd.DataFrame(columns=[column],data=pd.to_numeric(df[df['field_id']==fid][column]))
# calculate all NPS components:
nps['total'] = subject[column].count()
nps['detractors'] = subject[subject[column]<7][column].count()
nps['passives'] = subject[(subject[column]>6) & (subject[column]<9)][column].count()
nps['promoters'] = subject[subject>8][column].count()
nps['nps'] = (nps['promoters'] - nps['detractors']) / nps['total']
return nps然后,假设您希望为df的一个名为answer的列计算NPS,但只在df[df['field_id']==fid]中计算。就这样说吧:
npsForField(df, column='answer', fid='abc123')抽样结果:
{'total': 979,
'detractors': 313,
'passives': 291,
'promoters': 375,
'nps': 0.06332992849846783}页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53426059
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号