
我如何求和,平均,计数组和标准偏离相同的数据?
我如何求和,平均,计数组和标准偏离相同的数据?
提问于 2018-11-09 23:02:55
我试图按“名称”和“站点”对此数据进行分组,我想创建4个新列,这些列查找“支出”列的和、计数组、平均值和标准差。
到目前为止,我的代码如下:
import pandas as pd
df=pd.DataFrame({'Name':['Harry','John','Holly','John','John','John','Holly','Holly','Molly','Molly','Holly','Harry','Harry','Harry'], 'Spend': [76,43,23,43,234,54,34,12,43,54,65,23,12,32],
'Site': ['Amazon','Ikea','Apple','Amazon', 'Apple', 'Ikea', 'Apple', 'Apple', 'Amazon', 'Amazon', 'Ikea', 'Amazon', 'Amazon', 'Ikea']})
print (df)目前,我的数据文件如下所示:
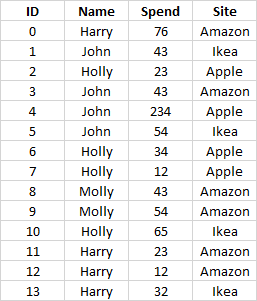
我想让它看起来像这样
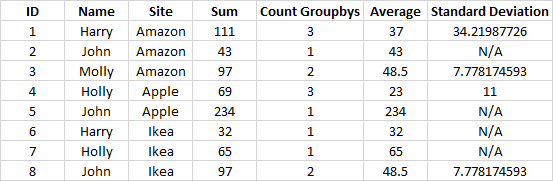
我该怎么做呢?
提前感谢
编辑10/11/18:
代码:
import pandas as pd
df=pd.DataFrame({'Name':['Harry','John','Holly','John','John','John','Holly','Holly','Molly','Molly','Holly','Harry','Harry','Harry'], 'Spend': [76,43,23,43,234,54,34,12,43,54,65,23,12,32],
'Site': ['Amazon','Ikea','Apple','Amazon', 'Apple', 'Ikea', 'Apple', 'Apple', 'Amazon', 'Amazon', 'Ikea', 'Amazon', 'Amazon', 'Ikea'], 'Spend2': [176,143,123,143,1234,154,134,112,143,254,365,423,512,632]})
print (df)在此之前:
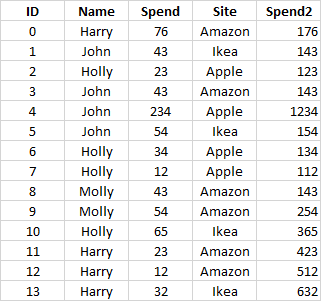
之后:
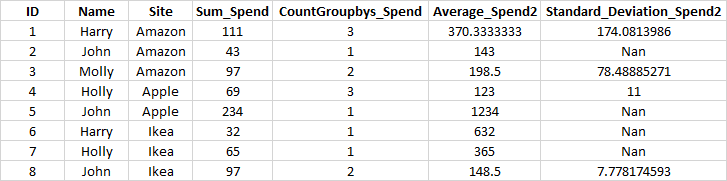
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-11-09 23:09:52
df_summary = df.groupby(['Name', 'Site']).agg([np.sum, pd.Series.count, np.mean, np.std])
df_summary.columns = ['Sum', 'Count Groupbys', 'Average', 'Standard Deviation']
df_summary = df_summary.reset_index().sort_values(['Site', 'Name'])
>>> df_summary
Name Site Sum Count Groupbys Average Standard Deviation
0 Harry Amazon 111 3 37.0 34.219877
4 John Amazon 43 1 43.0 NaN
7 Molly Amazon 97 2 48.5 7.778175
2 Holly Apple 69 3 23.0 11.000000
5 John Apple 234 1 234.0 NaN
1 Harry Ikea 32 1 32.0 NaN
3 Holly Ikea 65 1 65.0 NaN
6 John Ikea 97 2 48.5 7.778175在编辑过程中,您可以通过传递列上键的字典来使用agg,其值是要应用于这些列的函数:
df_summary = df.groupby(['Name', 'Site']).agg(
{'Spend': [np.sum, pd.Series.count],
'Spend2': [np.mean, np.std]}
)
df_summary.columns = ['Sum_Spend', 'CountGroupbys_Spend', 'Average_Spend2', 'Standard_Deviation_Spend2']
df_summary = df_summary.reset_index().sort_values(['Site', 'Name'])
>>> df_summary
Name Site Sum_Spend CountGroupbys_Spend Average_Spend2 Standard_Deviation_Spend2
0 Harry Amazon 111 3 370.333333 174.081399
4 John Amazon 43 1 143.000000 NaN
7 Molly Amazon 97 2 198.500000 78.488853
2 Holly Apple 69 3 123.000000 11.000000
5 John Apple 234 1 1234.000000 NaN
1 Harry Ikea 32 1 632.000000 NaN
3 Holly Ikea 65 1 365.000000 NaN
6 John Ikea 97 2 148.500000 7.778175页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53234359
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号