
在matplotlib中分配散点图中的值
在matplotlib中分配散点图中的值
提问于 2018-11-09 12:49:24
我试图为特定值指定颜色,同时将不同的聚类技术与n个集群进行比较,在本例中为3:
print(data2D)
x y k_label h_label
10 5 0 1
8 5 1 1
...
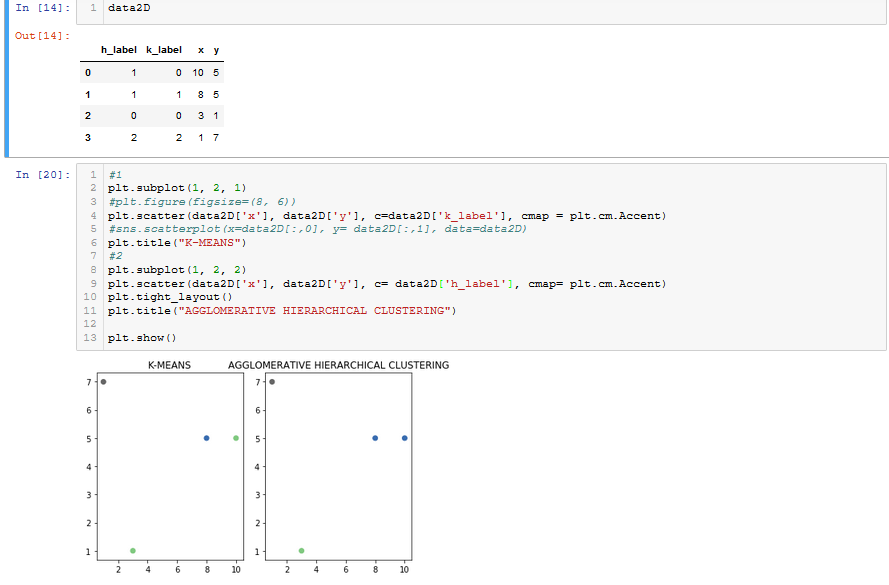
#1
plt.subplot(1, 2, 1)
#plt.figure(figsize=(8, 6))
plt.scatter(data2D[:,0], data2D[:,1], c=kmeans.labels_.astype(float))
#sns.scatterplot(x=data2D[:,0], y= data2D[:,1], data=data2D)
plt.title("K-MEANS")
#2
plt.subplot(1, 2, 2)
plt.scatter(data2D[:,0], data2D[:,1], c= agg_h.labels_.astype(float))
plt.tight_layout()
plt.title("AGGLOMERATIVE HIERARCHICAL CLUSTERING")
plt.show()我试过:
temp = pd.DataFrame(data= {'h_label': np.unique(df.k_label), 'k_label': np.unique(df.k_label), "color": ["red", "blue", "yellow"] })
df = df.merge(temp, on = ["h_label"])
df["k_label"] = kmeans.predict(X)但是它似乎很有意义,我不知道如何在Matplotlib中实现它。
简单地说,我想并排画两个数字(k_label & h_label) =1等于红色,=2蓝色.最后一种颜色等
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-11-09 13:41:02
你在找这个:两个情节的颜色图相同吗?
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53226021
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号