
如何根据其他现有列的条件添加具有值的新列?
如何根据其他现有列的条件添加具有值的新列?
提问于 2018-11-05 22:56:12
这是当前的df_treatments。
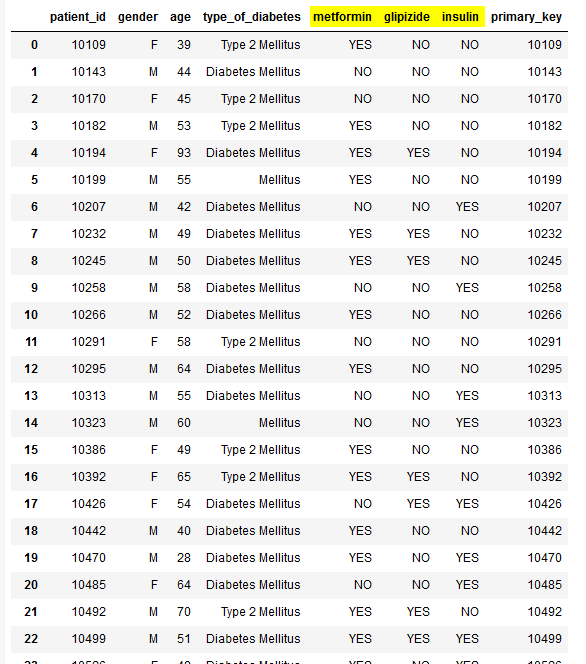
我想添加一个新的字段"treatment_type“,它的值应该基于列中的值(二甲双胍、格列吡嗪、胰岛素):
(“treatment_type值”:二甲双胍值、格列吡嗪值、胰岛素值)
"No Treatment" (NO, NO, NO)
"Metformin" (YES, NO, NO)
"Glipizide" (NO, YES, NO)
"Insulin" (NO, NO, YES)
"Metformin-Glipizide" (YES, YES, NO)
"Metformin-Insulin" (YES, NO, YES)
"Glipizide-Insulin" (NO, YES, YES)
"Metformin-Glipizide-Insulin" (YES, YES, YES)我该怎么做?
谢谢,
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-11-05 23:04:33
有几种方法。一种是使用字典存储治疗方法和条件:
d = {"No Treatment": ('NO', 'NO', 'NO'),
"Metformin": ('YES', 'NO', 'NO')
"Glipizide": ('NO', 'YES', 'NO'),
...}然后迭代您的字典并更新您的系列:
arr = df[['metformin', 'glipizide', 'insulin']].values
for treatment, flags in d.items():
df.loc[(arr == flags).all(1), 'treatment_type'] = treatment我建议的唯一改进是将所有'NO' / 'YES'值转换为布尔False / True。这将大大提高效率,因为布尔级数支持矢量化操作。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53163479
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号