
熊猫条形图聚在一起
熊猫条形图聚在一起
提问于 2018-10-26 21:41:38
我有一个相当大的csv文件,从一组基准,并希望一起绘制的结果组在3s。F.ex:
%matplotlib inline
from matplotlib import pyplot as plt
import pandas as pd
import numpy as np
from io import StringIO
TESTDATA = StringIO("""benchmark,smt,speedup
b1, smt1, 100
b1, smt2, 111
b1, smt4, 118
b2, smt1, 100
b2, smt2, 108
b2, smt4, 109
""")
df = pd.read_csv(TESTDATA, sep=",")
df.plot(kind="bar")这给了我一个条形图,每个酒吧的间隔都是均匀的。但是,我怎样才能在没有任何间隔的情况下将b1组合在一起,然后在b2分组之前有一个空间呢?
我明白了:
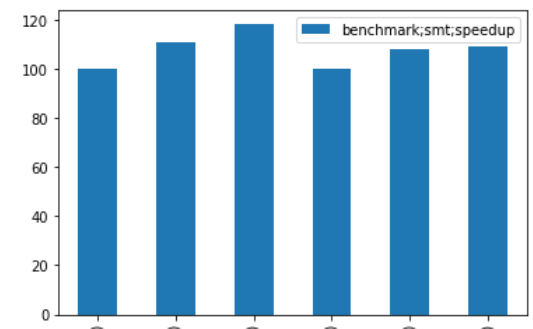
但却想要这样的东西:
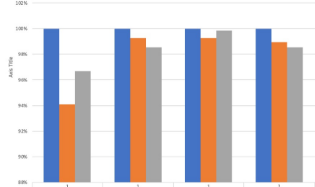
使用evert 3条表示每个给定基准的smt1、smt2和smt4的加速比。
回答 2
Stack Overflow用户
回答已采纳
发布于 2018-10-26 22:02:00
你有一些不一致的分隔符,但你可以像我一样克服它。
%matplotlib inline
from matplotlib import pyplot as plt
import pandas as pd
import numpy as np
from io import StringIO
TESTDATA = StringIO("""benchmark;smt;speedup
b1, smt1, 100
b1, smt2, 111
b1, smt4, 118
b2, smt1, 100
b2, smt2, 108
b2, smt4, 109
""")
df = pd.read_csv(TESTDATA, sep=",", skiprows=1, names=['benchmark', 'smt', 'speedup'])
df.pivot(index='benchmark', columns='smt').plot(kind='bar')
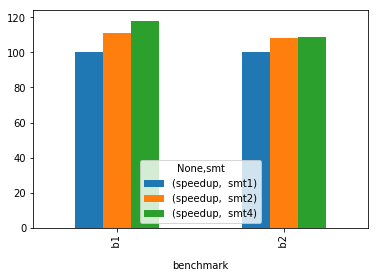
Stack Overflow用户
发布于 2018-10-26 21:52:22
第一,更改您的九月列名称它应该是,,而不是;
TESTDATA = StringIO("""benchmark,smt,speedup
b1, smt1, 100
b1, smt2, 111
b1, smt4, 118
b2, smt1, 100
b2, smt2, 108
b2, smt4, 109
""")
df = pd.read_csv(TESTDATA, sep=",")然后我们做pivot和plot
df.pivot(*df.columns)
Out[446]:
smt smt1 smt2 smt4
benchmark
b1 100 111 118
b2 100 108 109
df.pivot(*df.columns).plot(kind='bar')
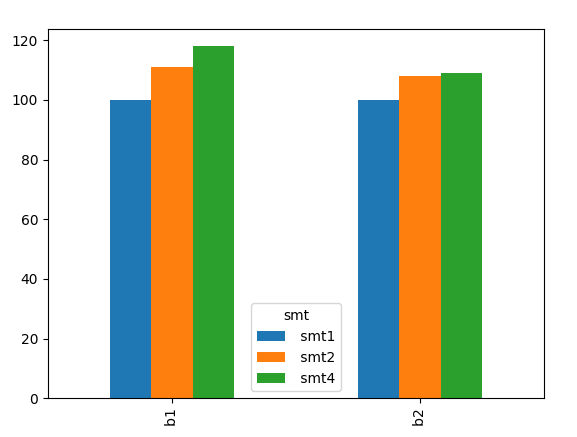
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53016623
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号