
CYK算法的实现
CYK算法的实现
提问于 2018-10-22 02:21:54
我正在尝试实现维基百科提供的CYK伪代码。我输入的例句应该是输出True,但是它输出的是false。考虑到提供的示例从1开始,我想我在索引方面遇到了问题。
代码:
def is_in_language(self, tokens):
n = len(tokens)
rules = self.grammar.lhs_to_rules
table = defaultdict(lambda: defaultdict(dict))
#Initialize dictionary table[row][column][nonterminal r] = boolean
for row in range(n+1):
for col in range(n+1):
for r in rules:
table[row][col][r] = False
for i in range(n):
nonTerminalList = self.grammar.rhs_to_rules[(tokens[i],)]
print(nonTerminalList)
for nonTerminal in nonTerminalList:
(r,right,prob) = nonTerminal
table[0][i][r] = True
for l in range(2,n+1):
for s in range(n-l+1):
for p in range(l-1+1):
for B in rules:
for C in rules:
AList = self.grammar.rhs_to_rules[B,C]
if(len(AList) > 0):
for A in AList:
(leftA, rightBC, prob) = A
try:
if(table[p][s][B] and table[l-p][s+p][C]):
table[l][s][leftA] = True
except:
pass
print(table[n][0][self.grammar.startsymbol])
return table回答 1
Stack Overflow用户
发布于 2021-12-09 21:51:23
python中的以下代码实现了CYK动态规划算法(描述这里),该算法可用于求解CFG的隶属度问题,即给定输入字符串w和CFG语法G为chomosky范式(CNF),可以在O(n^3\w)时间内判断w是否为L(G)。
import numpy as np
import pandas as pd
def is_in_cartesian_prod(x, y, r):
return r in [i+j for i in x.split(',') for j in y.split(',')]
def accept_CYK(w, G, S):
if w == 'ε':
return 'ε' in G[S]
n = len(w)
DP_table = [['']*n for _ in range(n)]
for i in range(n):
for lhs in G.keys():
for rhs in G[lhs]:
if w[i] == rhs: # rules of the form A -> a
DP_table[i][i] = lhs if not DP_table[i][i] else DP_table[i][i] + ',' + lhs
for l in range(2, n+1): # span
for i in range(n-l+1): # start
j = i+l-1 # right
for k in range(i, j): # partition
for lhs in G.keys():
for rhs in G[lhs]:
if len(rhs) == 2: #rules of form A -> BC
if is_in_cartesian_prod(DP_table[i][k], DP_table[k+1][j], rhs):
if not lhs in DP_table[i][j]:
DP_table[i][j] = lhs if not DP_table[i][j] else DP_table[i][j] + ',' + lhs
return S in DP_table[0][n-1] 现在,让我们使用上述算法实现以下简单的CFG G(已经在CNF中):
S -> AB \ BC _A -> BA _A B_ -> CC _c_b C_C -> AB _a
和输入字符串w= baaba来测试w在L(G)中的成员资格。
# let's define the grammar productions and symbols first
NTs = ['S', 'A', 'B', 'C', 'D']
Ts = ['a', 'b']
rules = ['S -> AB | BC', 'A -> BA | a', 'B -> CC | b', 'C -> AB | a'] #, 'D -> ϵ']
G = get_grammar(rules)
print(G)
# {'S': ['AB', 'BC'], 'A': ['BA', 'a'], 'B': ['CC', 'b'], 'C': ['AB', 'a']}
# now check if the string w is a member of G
accept_CYK('baaba', G, 'S')
# True
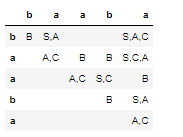
下面的动画演示如何构造DP表:

这种带有反向指针的DP算法的概率版本可用于PCFGs在NLP中构造自然语言句子的解析树。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/52921637
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号