
Tensorflow中的归一化互信息
这有可能在Tensorflow中实现规范化的相互信息吗?我想知道我是否能做到这一点,我是否能够区分它。假设我在两个不同的张量中预测了P和标号Y。是否有一种简单的方式来使用标准化的相互信息?
我想做一些类似的事情:
回答 1
Stack Overflow用户
发布于 2018-10-15 03:15:30
假设您的聚类方法给出了概率预测/隶属函数p(c|x),例如,p(c=1|x)是第一个集群中x的概率。假设y是x的基本真理类标签。
归一化互信息是
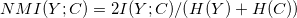
。
熵H(Y)可以用以下方式来估计:https://stats.stackexchange.com/questions/338719/calculating-clusters-entropy-python
根据定义,熵H(C)是
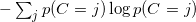
,其中
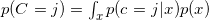
。
条件互信息
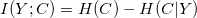
哪里
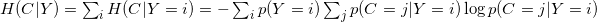
,以及
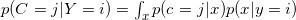
。
所有涉及积分的项都可以用抽样来估计,即训练样本的平均值。整体NMI是可微的。
我没有误解你的问题。我假设你使用了一个神经网络模型,它输出逻辑,因为你没有提供任何信息。然后,您需要对逻辑进行规范化,以获得p(c|x)。
估计NMI可能还有其他方法,但如果您对所使用的任何模型的输出进行离散化,则无法区分它们。
TensorFlow代码
假设我们有标签矩阵p_y_on_x和聚类预测p_c_on_x。它们中的每一行对应于一个观察x;每一列对应于每个类和集群中x的概率(因此每一行的总和最多为1)。进一步假定p(x)和p(x|y)的一致概率。
然后,可以按以下方式估算NMI:
p_y = tf.reduce_sum(p_y_on_x, axis=0, keepdim=True) / num_x # 1-by-num_y
h_y = -tf.reduce_sum(p_y * tf.math.log(p_y))
p_c = tf.reduce_sum(p_c_on_x, axis=0) / num_x # 1-by-num_c
h_c = -tf.reduce_sum(p_c * tf.math.log(p_c))
p_x_on_y = p_y_on_x / num_x / p_y # num_x-by-num_y
p_c_on_y = tf.matmul(p_c_on_x, p_x_on_y, transpose_a=True) # num_c-by-num_y
h_c_on_y = -tf.reduce_sum(tf.reduce_sum(p_c_on_y * tf.math.log(p_c_on_y), axis=0) * p_y)
i_y_c = h_c - h_c_on_y
nmi = 2 * i_y_c / (h_y + h_c)在实践中,请对概率非常小心,因为它们应该是正的,以避免tf.math.log中的数字溢出。
如果你发现任何错误,请评论。
https://stackoverflow.com/questions/52767807
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号