
文本文档在法律领域的分类
我一直在做一个关于在法律领域对文本文档进行分类的项目,(法律判断预测类问题)。
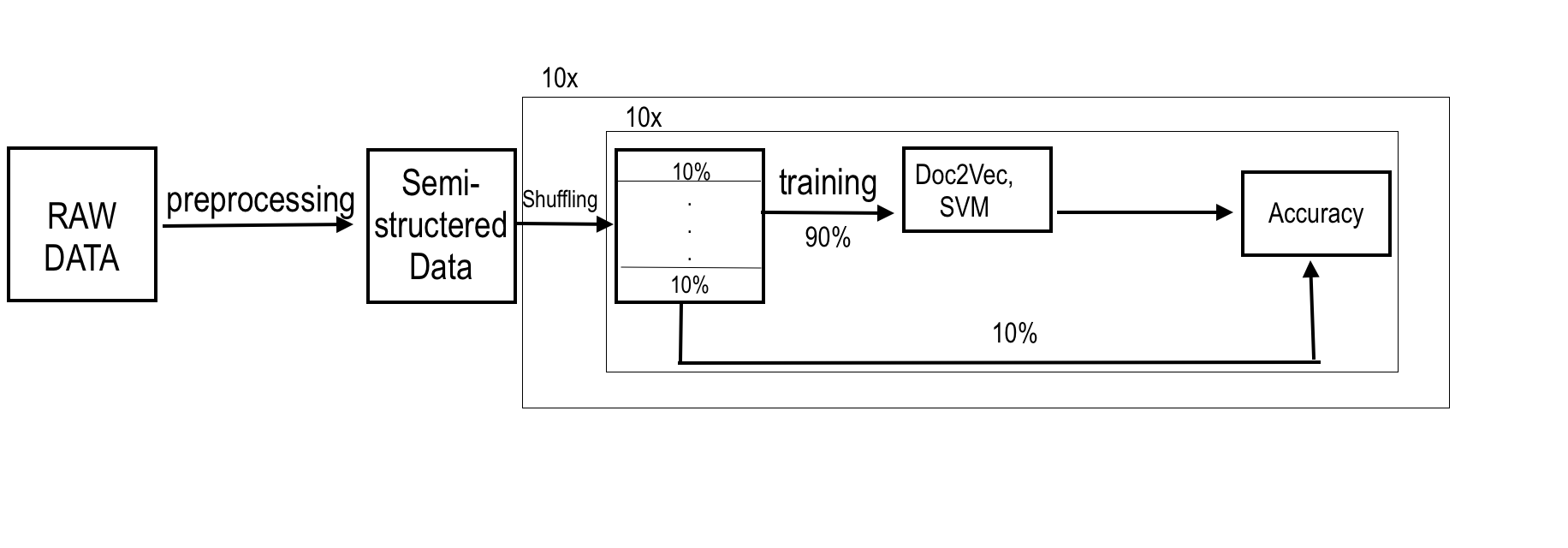
给定的数据集包括700份法律文件(在两个类别中很好地平衡)。经过预处理,包括应用所有的最佳实践(如删除停止词等),每个文档有3段,我可以一起或单独考虑。平均而言,文本文档的大小为2285字。
我的目标是使用与经典的n-gram模型不同的东西(该模型不考虑任何单词、顺序或语义):
- 使用神经网络(Doc2Vec)将每个文档的文本转换为连续域中的向量,以创建具有向量的数据集,表示文档和相应的标签(正如我所说的,有两个可能的标签:0或1);
- 训练一个支持向量机分类样本,我已经使用了10倍交叉验证。
我想知道是否有人在这个特定的领域有一些经验,谁可以建议我其他方式或如何改进模型,因为我没有得到特别好的结果: 74%的准确性。
使用Doc2Vec将文本转换为向量并使用它们来输入分类器正确吗?
我的模型说明:
回答 1
Stack Overflow用户
发布于 2018-10-05 18:35:13
Doc2Vec是将可变长度的文本转换为摘要向量的合理方法,这些向量通常用于分类--特别是主题或情感分类(原始“段落向量”中突出显示的两个应用程序)。
然而,700个文档作为一个培训集是非常小的。发表的著作倾向于使用数以万计到数百万份文件的身体。
另外,你的具体分类目标--预测一项法律判决--对我的打击要比主题或情感分类难得多。要知道一个案件将如何判决,取决于大量的外部法律/先例(这不是在培训中)和逻辑推导,有时取决于个别情况下的细微之处。这些是单一文本向量的模糊摘要不太可能捕捉到的东西。
相反,你报告的74%的准确率听起来简直令人印象深刻。(只要有这些摘要,外行也会这么做吗?)我不知道摘要中是否有明确的“告诉”--摘要中的词语选择强烈地暗示或完全揭示了实际的判断。如果这是文本中最强烈的信号(除非有实际的领域知识和逻辑推理),那么通过一个更简单的n克/包字表示和分类器,您可能会得到同样好的结果。
元优化你的训练参数可能会逐步提高结果,但我认为你需要更多的数据,也许更先进的学习技术,才能真正接近你所期望的那种具有法律能力的人类水平的预测。
https://stackoverflow.com/questions/52591572
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号