
在Python中为聚合数据文件格式化头
在Python中为聚合数据文件格式化头
提问于 2018-09-25 10:32:00
我有如下数据:-
,issue_name,doc_id,doc_type,doc_title
0,The App keeps crashing / restarting / hanging,5b519e219b989aaf3db06917,GUIDE,Restart the device
1,The App keeps crashing / restarting / hanging,5b519e219b989aaf3db06917,GUIDE,Restart the device
2,The App keeps crashing / restarting / hanging,5b51a24d9b989aaf3db0691a,GUIDE,Fix the App
3,The App keeps crashing / restarting / hanging,5b51a24d9b989aaf3db0691a,GUIDE,Fix the App
4,The App keeps crashing / restarting / hanging,5b519e219b989aaf3db06917,GUIDE,Restart the device
5,The App keeps crashing / restarting / hanging,5b519e219b989aaf3db06917,GUIDE,Restart the device当我用以下代码汇总相同的计数时:-
dfreturns = pd.DataFrame(Guidedocdetails, columns=['issue_name','doc_id','doc_type','doc_title'])
dfreturns.to_csv('ReturnGuideDocDetails.csv')
dfreturnguidecount = dfreturns.groupby(['issue_name','doc_type','doc_title']).agg(['count'])
dfreturnguidecount.to_csv('Return_guideid_counts.csv') 我得到的输出如下:
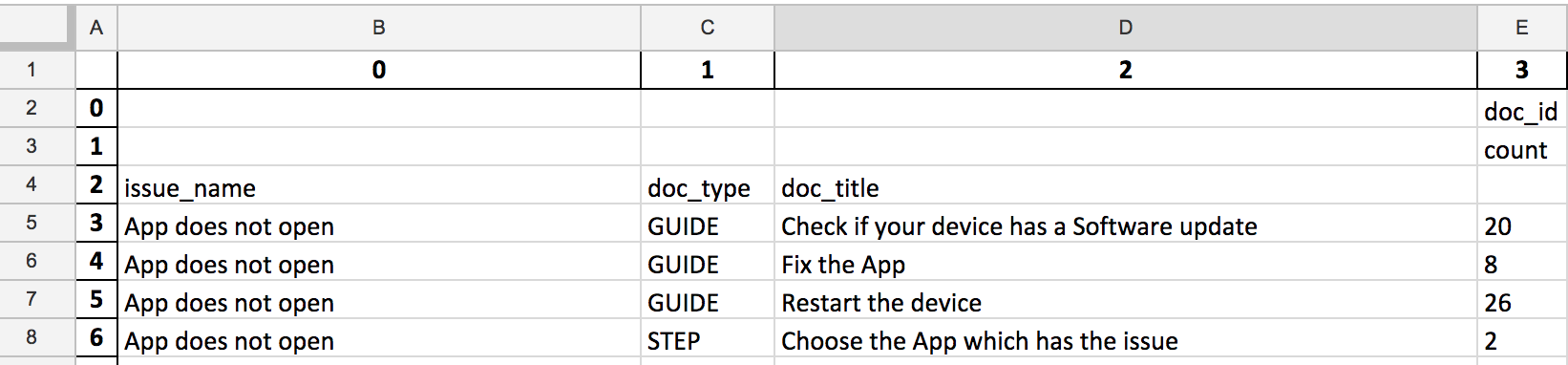
如何删除doc_id和顶部的额外行。我希望产出如下:
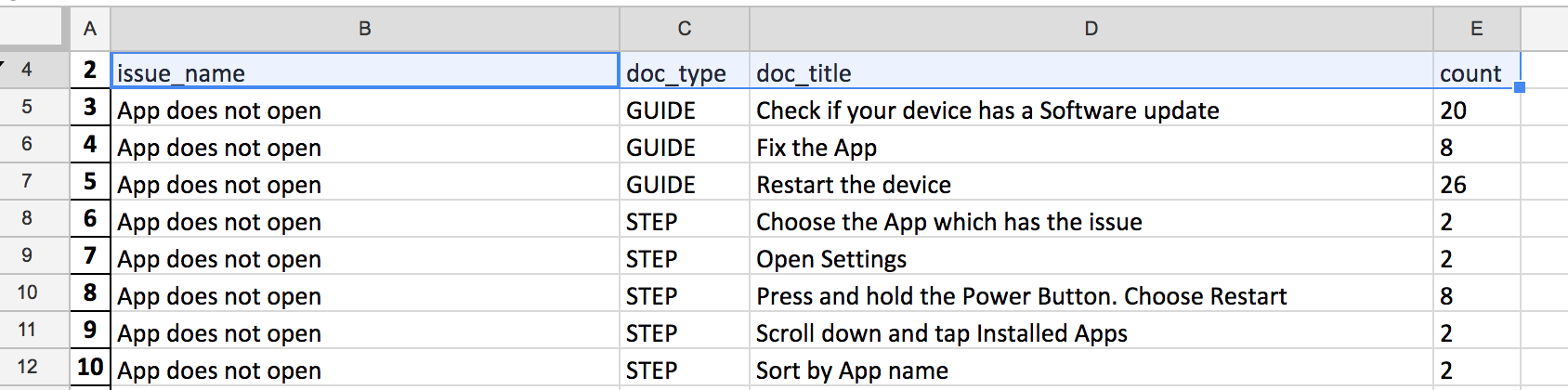
请帮助我理解如何实现同样的目标。
在应用以下代码后:
dfnonreturnguidecount = (dfnonreturns.groupby(['issue_name','doc_type','doc_title'])['issue_name'].count().reset_index(name='count'))
dfnonreturnguidecount.to_csv('NonReturn_guideid_counts.csv')产出:-
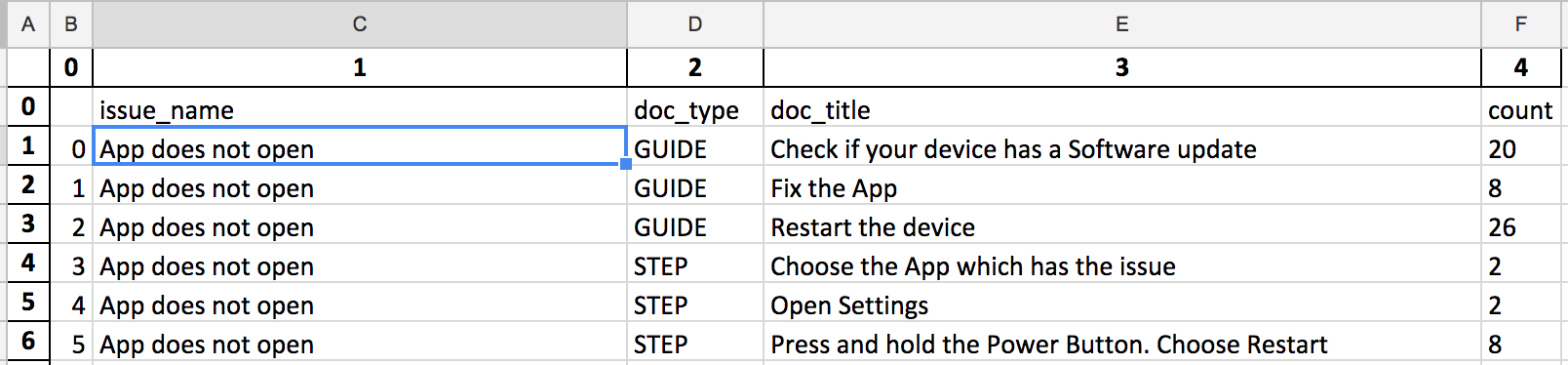
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-09-25 10:33:25
我认为需要在列中删除MultiIndex,使用GroupBy.size或GroupBy.count
returnguidecount = (dfreturns.groupby(['issue_name','doc_type','doc_title'])
.size()
.reset_index(name='count'))returnguidecount = (dfreturns.groupby(['issue_name','doc_type','doc_title'])['issue_name']
.count()
.reset_index(name='count'))print (returnguidecount)
issue_name doc_type doc_title \
0 The App keeps crashing / restarting / hanging GUIDE Fix the App
1 The App keeps crashing / restarting / hanging GUIDE Restart the device
count
0 2
1 4 不同之处是count在列groupby之后排除NaNs值。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/52496060
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号