
优化collect()的使用
我有工作代码,但我的本地计算机可以在1分钟内完成一项任务,需要10分钟。因此,我认为我的代码需要优化,而且我认为我没有正确地使用Spark,特别是SQL limit()和collect()方法。
我想/需要将我的问题转移到Spark (火星雨),因为我们的旧工具和计算机无法明智地处理生成的大量文件(而且它们显然没有资源来处理我们生成的一些最大的文件)。
我正在查看CSV文件,对于每个文件,即实验,我需要知道哪个传感器是第一个/最后一个触发的,以及这些事件何时发生。
减少到火花相关代码我做
tgl = dataframe.filter("<this line is relevant>") \
.select(\
substring_index(col("Name"),"Sensor <Model> <Revision> ", -1)\
.alias("Sensors"),\
col("Timestamp").astype('bigint'))\
.groupBy("Sensors").agg(min("Timestamp"),max("Timestamp"))
point_in_time = tgl.orderBy("min(Timestamp)", ascending=True).limit(2).collect()
[...]
point_in_time = tgl.orderBy("min(Timestamp)", ascending=False).limit(1).collect()
[...]
point_in_time = tgl.orderBy("max(Timetamp)", ascending=True).limit(1).collect()
[...]
point_in_time = tgl.orderBy("max(Timestamp)", ascending=False).limit(2).collect()
[...]我这样做是因为我在某个地方读到,使用.limit()通常是更明智的选择b/c,因此并不是所有的数据都会集中收集,这会花费相当多的时间、内存和网络容量。
我用一个文件测试我的代码,文件的大小为2.5GB,长度约为3E7行。当我查看处理的时间线时,我得到以下信息:
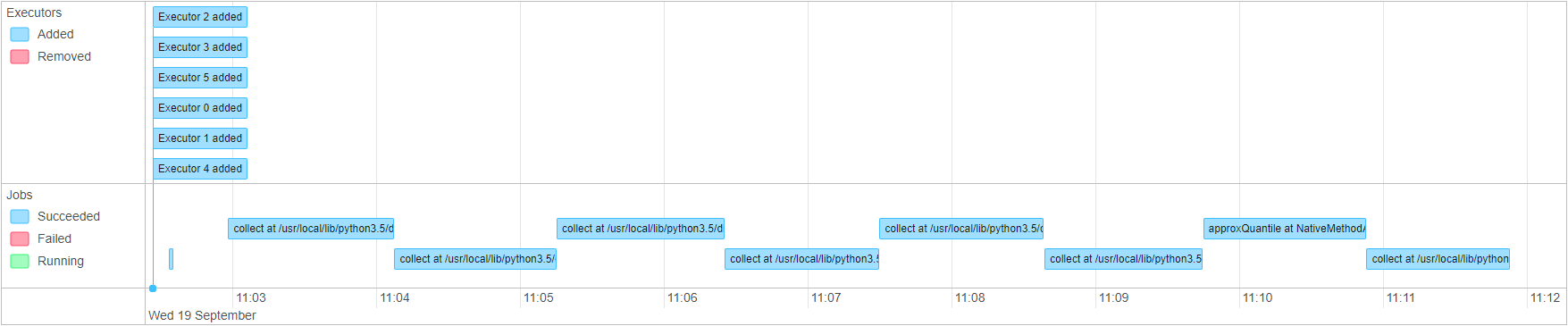
要注意的第一件有趣的事情是,每个星火任务都需要1.1分钟。上面所示的代码负责对collect()的前4次图解调用。
由于所有四个调用都共享来自filter().select().group().agg()的相同数据格式,所以我认为后三个调用比第一个调用要快得多。显然,火花不认识到这一点,并开始从原来的数据,每次。如何对此进行优化,以便以后三个对collect()的调用受益于第一次调用collect()的中间结果
回答 1
Stack Overflow用户
发布于 2018-09-19 21:54:28
您对火花每次重新执行DAG的观察是正确的,它源于一个非常简单的事实,即火花是懒惰的,火花有两种类型的操作:
- 转换: select、filter、groupBy、orderBy、withColumn等,它们描述了如何转换数据基/数据集并对数据集做出贡献。
- 操作:导致DAG执行的写入、收集、计数等
Dataframes不保存数据,它们是一种描述输入数据转换的虚拟视图。一种避免对每个集合重新执行DAG的方法是缓存tgl。
tgl = dataframe.filter("<this line is relevant>") \
.select(\
substring_index(col("Name"),"Sensor <Model> <Revision> ", -1)\
.alias("Sensors"),\
col("Timestamp").astype('bigint'))\
.groupBy("Sensors").agg(min("Timestamp"),max("Timestamp"))
tgl.persist()
point_in_time = tgl.orderBy("min(Timestamp)", ascending=True).limit(2).collect()
[...]
point_in_time = tgl.orderBy("min(Timestamp)", ascending=False).limit(1).collect()
[...]
point_in_time = tgl.orderBy("max(Timetamp)", ascending=True).limit(1).collect()
[...]
point_in_time = tgl.orderBy("max(Timestamp)", ascending=False).limit(2).collect()
[...]它将防止DAG的重新执行,但是将tgl缓存到RAM会有代价,并且可能会抵消限制操作的好处。影响有多大,只有实验才能显示出来。
或者,如果您定义了您希望由您的程序回答什么样的问题,我可以尝试帮助您编写特定的查询或程序来一次回答。
https://stackoverflow.com/questions/52406998
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号