
OpenCL一维跨距卷积性能
OpenCL一维跨距卷积性能
提问于 2018-09-17 13:10:43
对于信号的下采样,我使用FIR滤波器+抽取级(这是一个实际的步长卷积)。滤波和抽取相结合的最大优点是减少了计算量(通过抽取因子)。
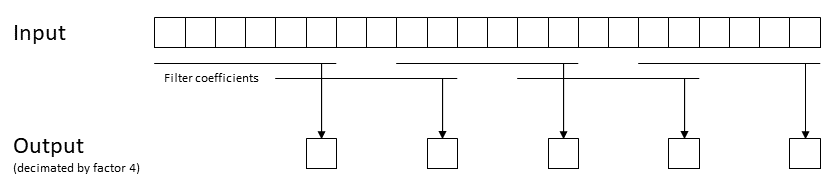
使用一个直接的OpenCL实现,我无法从抽取中获益。恰恰相反:抽取因子为4的卷积比完全卷积慢25%。
内核代码:
__kernel void decimation(__constant float *input,
__global float *output,
__constant float *coefs,
const int taps,
const int decimationFactor) {
int posOutput = get_global_id(0);
float result = 0;
for (int tap=0; tap<taps; tap++) {
int posInput = (posOutput * decimationFactor) - tap;
result += input[posInput] * coefs[tap];
}
output[posOutput] = result;
}我想这是由于未合并的内存访问。虽然我想不出解决办法来解决这个问题。有什么想法吗?
编辑:我尝试了Dithermaster的解决方案,将问题分解为合并读到共享的本地内存和从本地内存中卷积:
__kernel void decimation(__constant float *input,
__global float *output,
__constant float *coefs,
const int taps,
const int decimationFactor,
const int bufferSize,
__local float *localInput) {
const int posOutput = get_global_id(0);
const int localSize = get_local_size(0);
const int localId = get_local_id(0);
const int groupId = get_group_id(0);
const int localInputOffset = taps-1;
const int localInputOverlap = taps-decimationFactor;
const int localInputSize = localInputOffset + localSize * decimationFactor;
// 1. transfer global input data to local memory
// read global input to local input (only overlap)
if (localId < localInputOverlap) {
int posInputStart = ((groupId*localSize) * decimationFactor) - (taps-1);
int posInput = posInputStart + localId;
int posLocalInput = localId;
localInput[posLocalInput] = 0.0f;
if (posInput >= 0)
localInput[posLocalInput] = input[posInput];
}
// read remaining global input to local input
// 1. alternative: strided read
// for (int i=0; i<decimationFactor; i++) {
// int posInputStart = (groupId*localSize) * decimationFactor;
// int posInput = posInputStart + localId * decimationFactor - i;
// int posLocalInput = localInputOffset + localId * decimationFactor - i;
// localInput[posLocalInput] = 0.0f;
// if ((posInput >= 0) && (posInput < bufferSize*decimationFactor))
// localInput[posLocalInput] = input[posInput];
// }
// 2. alternative: coalesced read (in blocks of localSize)
for (int i=0; i<decimationFactor; i++) {
int posInputStart = (groupId*localSize) * decimationFactor;
int posInput = posInputStart - (decimationFactor-1) + i*localSize + localId;
int posLocalInput = localInputOffset - (decimationFactor-1) + i*localSize + localId;
localInput[posLocalInput] = 0.0f;
if ((posInput >= 0) && (posInput < bufferSize*decimationFactor))
localInput[posLocalInput] = input[posInput];
}
// 2. wait until every thread completed
barrier(CLK_LOCAL_MEM_FENCE);
// 3. convolution
if (posOutput < bufferSize) {
float result = 0.0f;
for (int tap=0; tap<taps; tap++) {
int posLocalInput = localInputOffset + (localId * decimationFactor) - tap;
result += localInput[posLocalInput] * coefs[tap];
}
output[posOutput] = result;
}
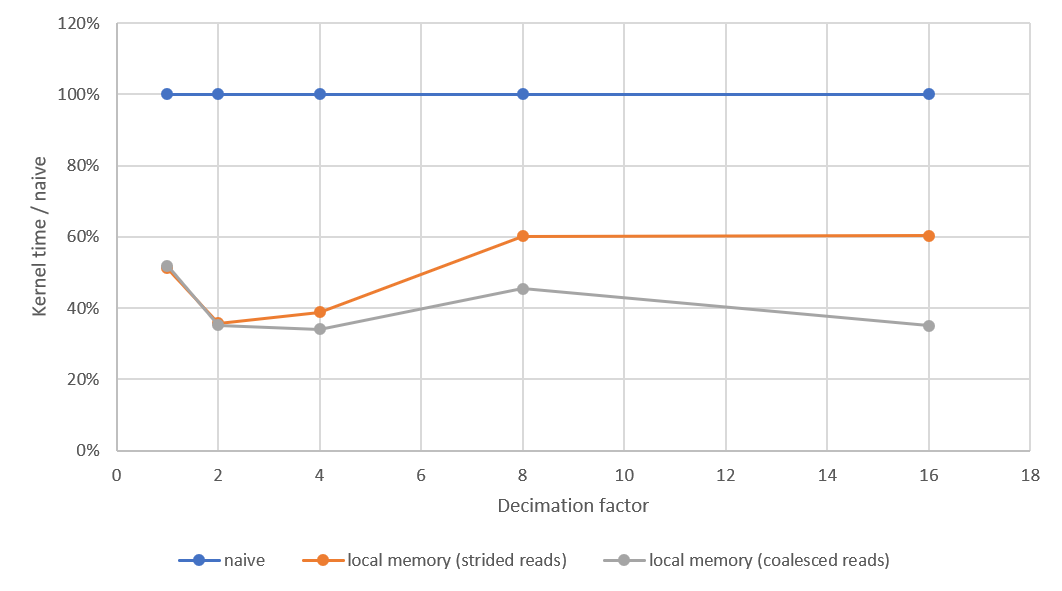
}很大的进步!但是,执行情况与总体行动(与抽取系数不成比例)并不相关:
- 与第一种方法相比,全卷积的加速比:~12 %
- 与完全卷积相比,抽取的计算时间:
- 抽取因子2: 61 %
- 抽取因子4: 46 %
- 抽取因子8: 53 %
- 抽取因子16: 68 %
性能的最佳抽取因子为4。为什么呢?有进一步改进的想法吗?
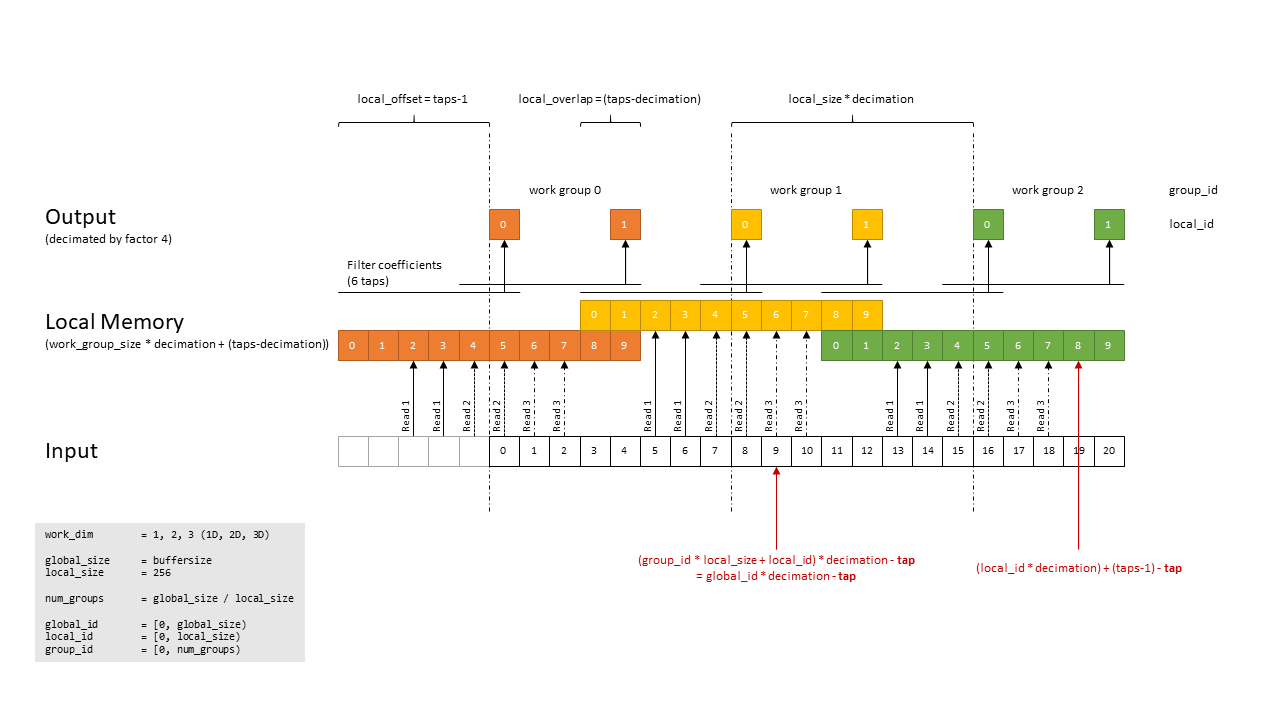
编辑2:具有共享本地内存的图:
编辑3:三种不同实现性能的比较
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-09-17 14:18:48
由于数据重叠的数量(66%),在工作组中共享工作项之间从内存中读取的数据可能会对此有所裨益。您可以消除冗余读取,也可以进行合并读取。将内核分成两部分:第一部分合并了对工作组中需要的所有数据的读取,并将其合并到共享的本地内存中。然后是一个内存屏障来同步。然后,在第二部分使用从共享本地内存读取的卷积。
谢谢你的图表,它帮助我更快地理解了你的目标,而不是试图阅读代码。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/52368579
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号