
为什么浏览器数组操作之间有这么大的性能差异?
我正在调优我的库好核,并设置一些性能测试来与本机数组函数进行比较。然后我在笔记本电脑上与Edge、FF、Chrome和Node 10.9进行了比较。当然,我的lib结果好坏参半,但更有趣的是,浏览器之间的差异有时是最佳浏览器和最差浏览器的30倍,而且在不同的操作之间似乎并不完全不同。
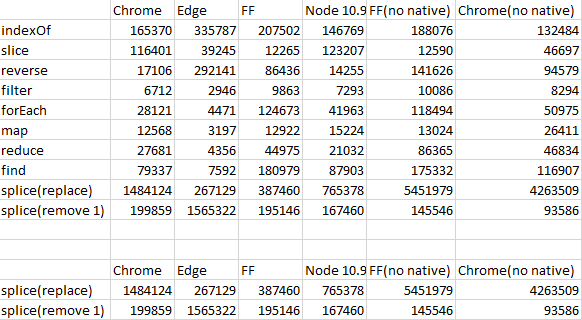
所使用的数组长为10000,随机ints在0到100000之间。
编辑版本:
- 铬: 68.0.3440.106
- FF: 62.0
- 边缘: 41.16299.371.0
- 节点: 10.9
以下是我的结果(仅用于本机操作):
编辑:现在具有正确的值和自定义算法(非本机)
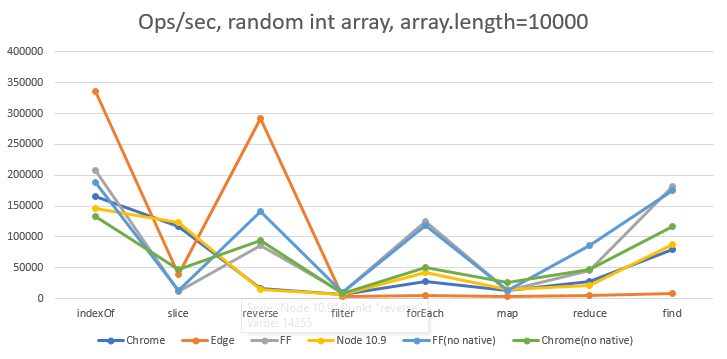
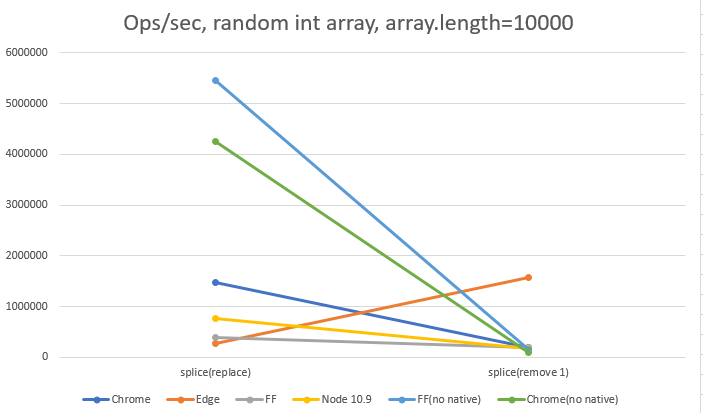
数据显示Benchmark.js中的ops/秒。
这是由于数据结构的实现还是微观优化?
回答 1
Stack Overflow用户
发布于 2018-09-11 18:48:32
这是由于数据结构的实现还是微观优化?
是。
较长的答案:可能两者兼而有之,但唯一能确定答案的方法是详细查看每个浏览器的实现。
您所测量到的更大的差异看上去可能是由于完全不同的数据结构选择造成的;然而,即使使用相同的基本数据结构,其他实现的效率也会产生巨大的差异(我见过10x-100x)。
另外,IMHO您的结果有点可疑: Chrome和Node使用相同的V8引擎,应该具有非常相似的性能。像"indexOf“或”剪接(移除1)“这样的结果表明,在基准测试中可能有问题。如果这两个结果不能被信任,那么为什么您会对Edge/Firefox结果有更多的信心呢?
说到基准质量:只使用一种类型的数组(只有一种大小、一种类型的内容,总是密集的)是您的结果可能不能反映整个故事的另一个原因;因此,请小心从中得出任何结论。
为什么有这么大的性能差异?
因为快速实现Array内置方法是一项巨大的工程工作。每个浏览器的工程团队都在尽最大努力把时间花在他们认为最重要的功能上。其结果是,您将在各种实现中看到不同程度的优化。
如果选择的数据结构有差异(我不知道),那么这些通常是权衡的:一种选择在X下可能更快,但在Y时比另一种选择更慢;或者一种选择可能更快,但消耗更多内存;等等。
https://stackoverflow.com/questions/52271899
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号