
阵列中求峰值元素的优化算法
到目前为止,我还没有找到解决此任务的任何算法:“元素被视为峰值的当且仅当(A[i]>A[i+1])&&(A[i]>A[i-1])、而不是考虑到数组(1D)的边缘。”
我知道,解决这个问题的常用方法是使用“除法和征服”,但这是在考虑边缘作为“峰”的情况下使用的。
O(..)这个练习需要获得的复杂性是O(log(n))。
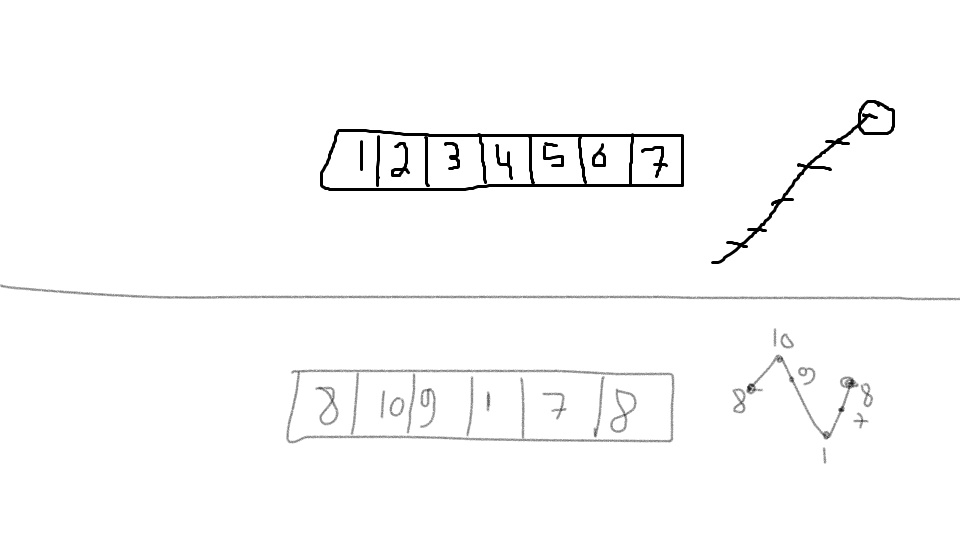
通过上面的图像,我可以清楚地知道为什么是O(log(n)),但是没有边复杂度就会改变为O(n),因为在较低的图片中,我在中间元素的每一侧运行递归函数,这使得它在O(n)中运行(最坏的情况是元素在边缘附近)。在这种情况下,为什么不使用这样简单的二进制搜索:
public static int GetPeak(int[]A)
{
if(A.length<=2)//doesn't apply for peak definition
{
return -1;
}
else {
int Element=Integer.MAX_VALUE;//The element which is determined as peak
// First and Second elements can't be hills
for(int i=1;i<A.length-1;i++)
{
if(A[i]>A[i+1]&&A[i]>A[i-1])
{
Element=A[i];
break;
}
else
{
Element=-1;
}
}
return Element;
}常见的算法写在这里:http://courses.csail.mit.edu/6.006/spring11/lectures/lec02.pdf,但正如我之前说过的,它不适用于本练习的条款。
只返回一个峰值,否则返回-1。
另外,如果由于语言障碍(我不是以英语为母语的人),文章的措辞不正确,我很抱歉。
回答 2
Stack Overflow用户
发布于 2018-08-29 19:16:17
我认为你想要的是一种动态规划方法,利用分而治之的方法。从本质上说,您的峰值有一个默认值,当您找到一个峰值时,它会被覆盖。如果您可以在方法开始时进行检查,并且只有在没有找到峰值的情况下才能运行操作,那么O()表示法将类似于O(pn),其中p是数组中任何给定元素都是峰值的概率,这是一个可变的术语,因为它与数据的结构方式有关(或不相关)。例如,如果您的数组只有1到5之间的值,并且它们的分布是相等的,那么概率将等于0.24,因此您将期望算法在O(0.24n)中运行。请注意,这似乎仍然等同于O(n)。但是,如果您要求数据值在数组中是唯一的,则您的概率等于:
p = 2 * sum( [ choose(x - 1, 2) for x in 3:n ] ) / choose(n, 3)
p = 2 * sum( [ ((x - 1)! / (2 * (x - 3)!)) for x in 3:n ] ) / (n! / (n - 3)!)
p = sum( [ (x - 1) * (x - 2) for x in 3:n ] ) / (n * (n - 1) * (n - 2))
p = ((n * (n + 1) * (2 * n + 1)) / 6 - (n * (n + 1)) + 2 * n - 8) / (n * (n - 1) * (n - 2))
p = ((1 / 3) * n^3 - 5.5 * n^2 + 6.5 * n - 8) / (n * (n - 1) * (n - 2))因此,这似乎是很多,但是如果我们在n接近无穷大的时候取这个极限,那么我们最终得到了一个接近1/3的p值。
所以,如果我们有33%的机会在数组上的任何元素上找到一个峰值,那么在递归的底层,当你找到一个峰值的概率为1/3时。因此,这个值的期望值大约是在你找到一个之前的三个比较,这意味着一个恒定的时间。但是,在进行比较之前,仍然需要到达递归的底层,这需要O(log(n))时间。因此,分而治之的方法在平均情况下应该在O(log(n))时间内运行,在最坏的情况下应该运行O(n log(n))。
Stack Overflow用户
发布于 2018-08-30 08:29:46
如果您不能对数据进行任何假设(数字序列的单调性、峰值数),而且如果边缘不能算作峰值,那么您就不能期望获得比O(n)更好的平均性能。您的数据是随机分布的,任何值都可以是峰值。你必须一个一个地检查它们,并且这些值之间没有相关性。
接受边缘作为峰的潜在候选者会改变一切:你知道总是至少有一个峰值,一个足够好的策略是总是沿着增值的方向搜索,直到你开始下降或者到达边缘(这是你提供的文档之一)。这个策略是O(nlog(n)),因为您使用二进制搜索来查找局部最大值。
https://stackoverflow.com/questions/52080461
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号