
火花缓存功能:缓存作业和缓存阶段
火花缓存功能:缓存作业和缓存阶段
提问于 2018-08-20 22:19:10
我是新来的火花,可以在这里使用一些指导。我们有一些基本代码可以在csv中读取,缓存它,并输出到拼板上:
1. val df=sparkSession.read.options(options).schema(schema).csv(path)
2. val dfCached = df.withColumn()....orderBy(some Col).cache()
3. dfCached.write.partitionBy(partitioning).parquet(outputPath)AFAIK,一旦我们调用了parquet调用(一个操作),就应该执行缓存命令,在应用此操作之前保存DF的状态。
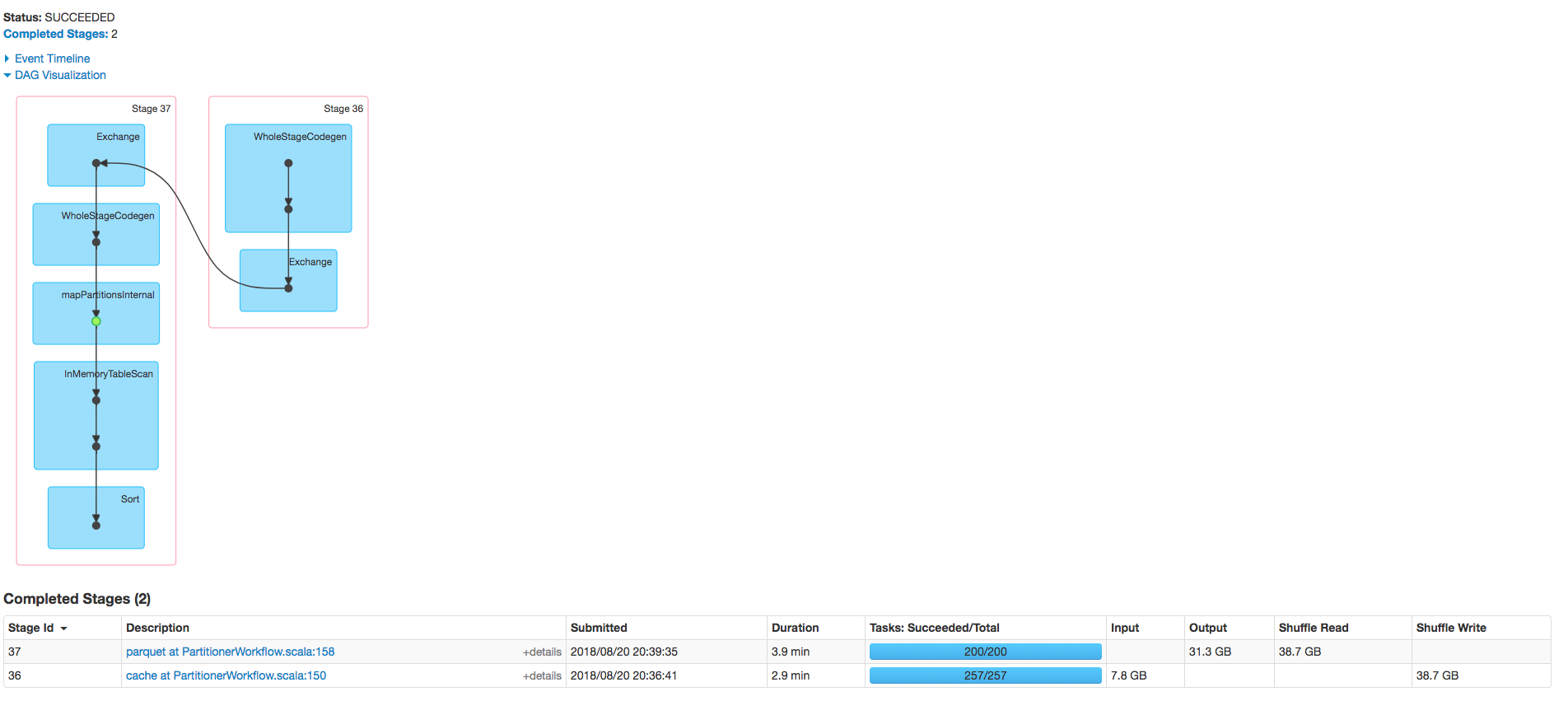
在星星之火UI中我看到:
- 执行上面#2中的
cache调用的单个分阶段作业 - 然后是执行
parquet调用的作业。这个工作有两个阶段:一个是重复缓存步骤,第二个是执行转换到拼板。(见下图)
为什么我同时有一个缓存作业和一个缓存阶段?我希望只有一个或者另一个,但是看起来我们在这里缓存了两次。

回答 1
Stack Overflow用户
发布于 2018-08-21 17:50:54
我不是百分之百肯定,但似乎正在发生以下情况:
- 当加载csv数据时,它在工作节点之间被拆分。我们调用cache(),每个节点将接收到的数据存储在内存中。这是第一个缓存作业。
- 当我们调用
partitionBy(...)时,需要根据传递给函数的args在不同的执行器之间重新组合数据。由于我们正在缓存数据,而且数据已经从一个执行器转移到另一个执行器,所以我们需要重新缓存被洗牌的数据。这是肯定的,因为第二个缓存阶段显示了一些洗牌写入数据。此外,与初始缓存任务相比,缓存阶段显示的任务更少;可能是因为只需要重新读取被洗牌的数据,而不是整个数据帧。 - 地板阶段被调用。我们可以看到一些洗牌读取数据,其中显示执行者读取新洗牌的数据。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51939221
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号