
Kafka流的最佳实践
Kafka流的最佳实践
提问于 2018-08-20 03:03:37
我们有一个用python编写的预测服务来提供机器学习服务,您可以发送它一组数据,它会给出异常检测或预测等等。
我想使用Kafka流来处理实时数据。
有两种选择方法:
- 卡夫卡流作业只完成
ETL函数:加载数据,并进行简单的转换和保存数据到弹性搜索。然后启动定时器,周期性地从ES加载数据,并调用预测服务来计算结果并将结果保存回ES。 - 卡夫卡流作业除了
ETL之外,所有的事情都是由卡夫卡流作业完成ETL,然后发送数据预测服务,并将计算结果保存给卡夫卡,消费者将结果从卡夫卡转发到ES。
我认为第二种方法是更实时的,但我不知道在流作业中做这么多的预测任务是个好主意。
对于这种应用,是否有任何共同的模式或建议?
回答 1
Stack Overflow用户
发布于 2018-08-20 09:56:08
是的,我也会选择第二种选择。
您可以做的是使用Kafka作为您的ML培训模块和您的预测模块之间的数据管道。这些模块可以在Kafka流中很好地实现。
请看下面的图表:
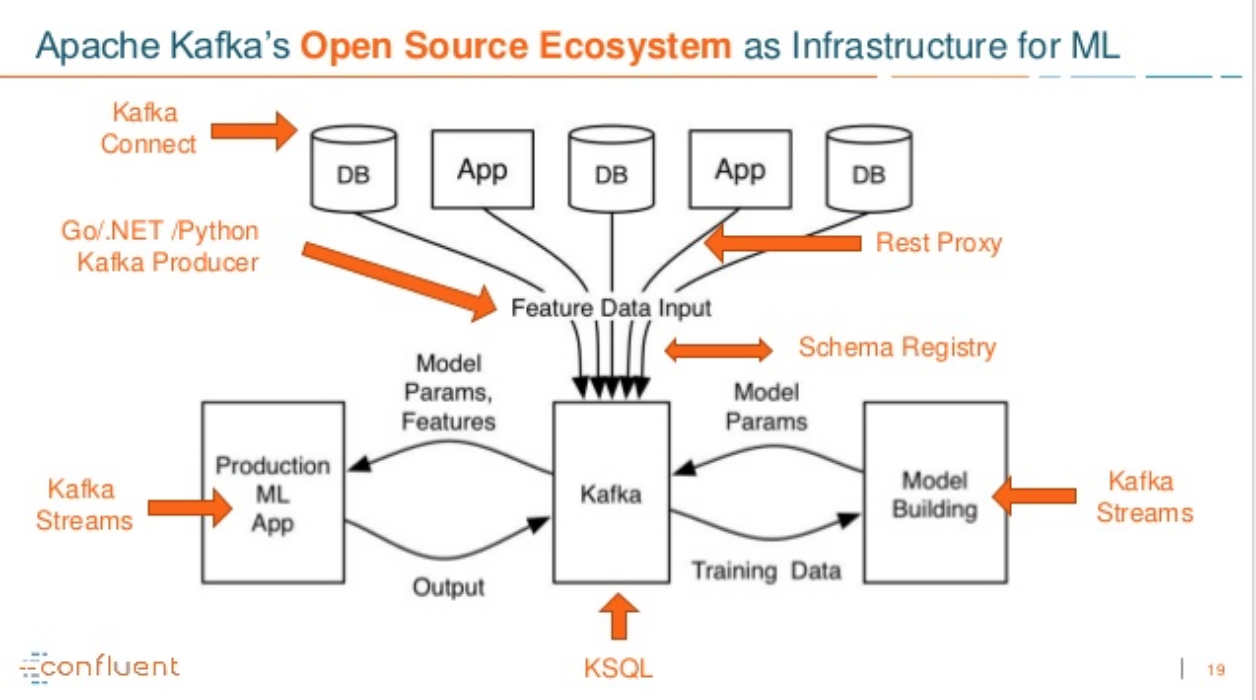
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51923672
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号