
Regex -在行开始后或在特定字符之后进行匹配的最有效表达式
我试图找到最有效的方式匹配字符后,行或后面的另一个字符。
匹配准则
ad([sxv])?[0-9]*[-_.] -需要在^之后或[-_.]之后立即找到匹配项。
注意:我不能100%确定处理器使用哪种正则表达式,但它似乎不支持非捕获组。
场景:
用户尝试访问一个域,然后根据几个regex表达式(包括本例)检查该域。如果没有找到匹配项,则允许访问。
示例用户输入(将被阻止):
ad.dailymail.co.uk
asdsa.adasdsa.dasdasd.asdasdasd.dasdasdsa.ad.test.comRegex测试:
ad.dailymail.co.uk
(^|[-_.])ad([sxv])?[0-9]*[-_.]- 13步^(.*[-_.])?ad([sxv])?[0-9]*[-_.]- 36步^([a-z0-9]([a-z0-9-]*[a-z0-9])?[-_.])*ad([sxv])?[0-9]*[-_.]- 69步
asdsa.adasdsa.dasdasd.asdasdasd.dasdasdsa.ad.test.com
(^|[-_.])ad([sxv])?[0-9]*[-_.]-151个步骤^(.*[-_.])?ad([sxv])?[0-9]*[-_.]- 28步^([a-z0-9]([a-z0-9-]*[a-z0-9])?[-_.])*ad([sxv])?[0-9]*[-_.]- 86步
到目前为止,看起来^(.*[-_.])?ad([sxv])?[0-9]*[-_.]似乎是最有效的,但是还有其他方法可以更快地检查吗?
另外,有人能告诉我为什么(^|[-_.])比其他表达式消耗这么多步骤吗?
回答 1
Stack Overflow用户
发布于 2018-08-16 09:38:25
您可以修改第二个正则表达式,以便为第一个组使用??修饰符。所以如果你已经找到“广告.”,它会懒洋洋地停在0次。刚开始的时候。
它的步骤甚至比第一个regexp (它是最快的)更少(9比10步)
缺点是,对于任何“非广告”urls,可能会变得更糟(0-2额外步骤)。它还将取决于它是否匹配。如果不匹配,则两个正则表达式具有相同的步骤。如果他们匹配,它可能有1-2个额外的步骤。
你可以做你的数学,计算这类类型的网址数目,并根据概率来决定。
最后,我制作了一个包含所有结果的表:
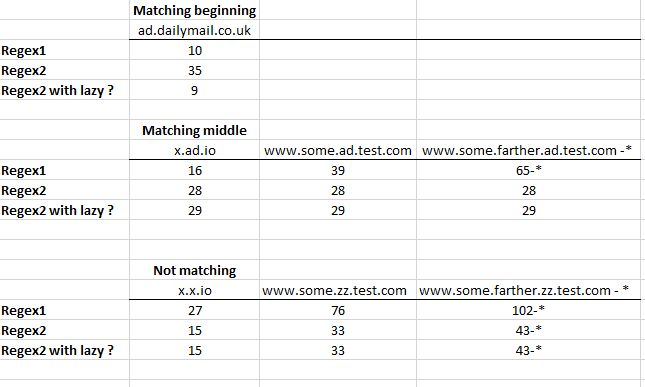
https://stackoverflow.com/questions/51873306
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号