
群明智概率分布
我有一个gps点的数据分布图。我把地理区域划分为网格。每个网格单元格都由数据文件中的两列(行,行)表示。全球定位系统各点都贴上其运输方式的标签。我想通过计算每个网格单元的传输方式来计算其概率分布。(有五种交通工具,即步行、自行车、汽车、火车、地铁)。
Row Col P(Walk) P(Bike) P(Car) P(Train) P(Subway)
8 8 Freq(walk)/n Freq(bike)/n Freq(car)/n Freq(train)/n Freq(subway)/n
8 9 Freq(walk)/n Freq(bike)/n Freq(car)/n Freq(train)/n Freq(subway)/n
8 10 Freq(walk)/n Freq(bike)/n Freq(car)/n Freq(train)/n Freq(subway)/n例如,第8行的网格单元,col 8包含638个gps点。598个步行点和40个地铁点,然后这个特定网格单元的每种运输模式的概率就变成了。
Row Col P(Walk) P(Bike) P(Car) P(Train) P(Subway)
8 8 598/638 0/638 0/638 0/638 40/638
8 9 ... ... ... ... ...
8 10 ... ... ... ... ...
... ... ... ... ... ... ...“”“
grp = df.groupby(['row','col','Transportation_Mode'])一种方法是逐个迭代每一组,使用for循环来获得每种传输模式的频率。但我认为,它们应该是更简单、更流行的方式,或库只需几行就可以解决这一问题。
为了更好地理解将每个地理区域划分为由行和cols表示的网格单元,附加了地理区域的图像。每个网格单元包含多个gps点,标记上它们的传输方式。
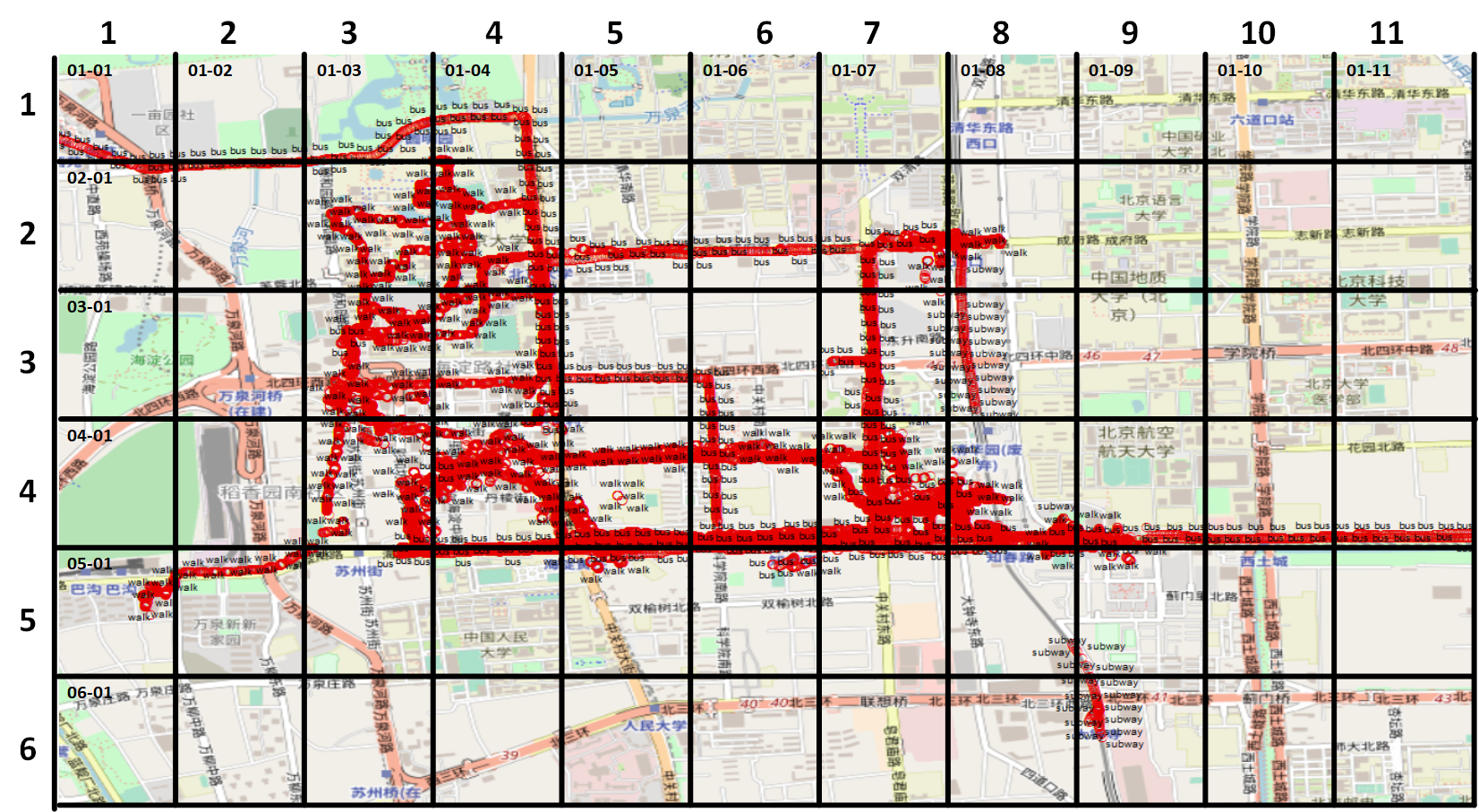
数据的csv文件可以在给定的链接中获得,以获得更清晰的数据。DLO-6yrovYJp5zEYLwlMPi 9
回答 1
Stack Overflow用户
发布于 2018-08-13 15:31:40
如果我没有弄错的话,你是在寻找一种更优雅的方法来循环每个组对象,并为每个组对象生成一个二维概率分布?
听起来您应该看看这是熊猫的文件 (更具体地说,是apply函数)。
您可以简单地将可视化应用于每个组,比如这个SNS KDE可视化,然后将各个图重新加入到网格中,就像您提供的网格一样。使用一点ax魔术,您可以为每种传输类型构建一个网格。我认为这是手边最好的工具。我会把逻辑留给你。
https://stackoverflow.com/questions/51824495
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号