
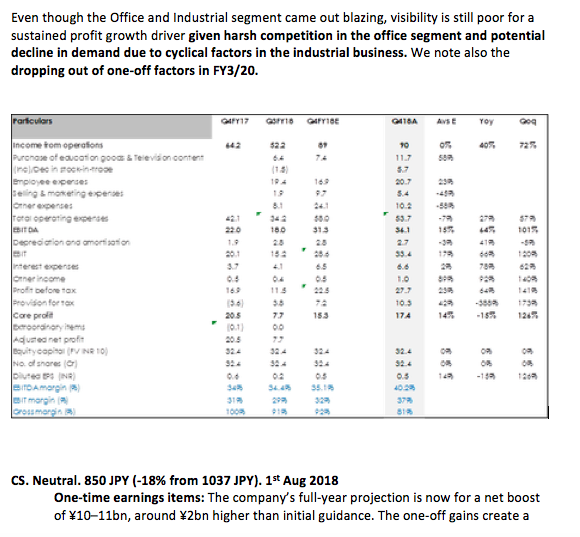
复制.docx和保存图像
我试图将文档的元素从一个文档文件复制到另一个文档文件。文字部分很简单,图像是它变得棘手的地方。附加一个图像来解释文档的结构:只是一些文本和1个图像。
from docx import Document
import io
doc = Document('/Users/neha/Desktop/testing.docx')
new_doc = Document()
for elem in doc.element.body:
new_doc.element.body.append(elem)
new_doc.save('/Users/neha/Desktop/out.docx')这让我了解了new_doc中文档的整个结构,但是图像仍然是空白的。图片如下:

好的是,我的空白图像位于正确的位置,所以我考虑从前面的图像中获取字节级数据,并将其插入到新的文档中。下面是我如何扩展上面的代码:
from docx import Document
import io
doc = Document('/Users/neha/Desktop/testing.docx')
new_doc = Document()
for elem in doc.element.body:
new_doc.element.body.append(elem)
im = doc.inline_shapes[0]
blip = im._inline.graphic.graphicData.pic.blipFill.blip
rId = blip.embed
doc_part = doc.part
image_part = doc_part.related_parts[rId]
bytes = image_part._blob #Here I get the byte level data for the image
im2 = new_doc.inline_shapes[0]
blip2 = im2._inline.graphic.graphicData.pic.blipFill.blip
rId2 = blip2.embed
document_part2 = new_doc.part
document_part2.related_parts[rId2]._blob = bytes
new_doc.save('/Users/neha/Desktop/out.docx')但是图像在new_doc中仍然是空的。从这里我该怎么办?
回答 3
Stack Overflow用户
发布于 2018-08-11 19:02:25
几天前我想出了一个解决办法。但是,使用这种方式,文本会丢失格式,但是图像的位置是正确的。
因此,对于para在paras中的source文档,如果有文本,我将其写到dest文档中。如果存在内联映像,则在dest文档中的那个位置添加一个唯一标识符(请参阅这里查看这些标识符如何工作,以及docxtpl中的上下文)。这些标识符和docxtpl在这里特别有用。然后使用这些唯一标识符,我创建了一个“context”(如下面所示),它基本上是映射唯一标识符到其特定InlineImage的映射,最后我创建了这个上下文。
下面是我的代码(对不必要的缩进表示歉意,我直接从文本编辑器复制它,shift+tab在这里不工作:P)
from docxtpl import DocxTemplate, InlineImage
import Document
import io
import xml.etree.ElementTree as ET
dest = DocxTemplate()
source = Document(source_path)
context = {}
ims = [im for im in source.inline_shapes]
im_addresses = []
im_streams = []
count = 0
for im in ims:
blip = im._inline.graphic.graphicData.pic.blipFill.blip
rId = blip.embed
doc_part = source.part
image_part = doc_part.related_parts[rId]
byte_data = image_part._blob
image_stream = io.BytesIO(byte_data)
im_streams.append(image_stream)
image_name = self.img_path+"img_"+"_"+str(count)+".jpeg"
with open(image_name, "wb") as fh:
fh.write(byte_data)
fh.close()
im_addresses.append(image_name)
count += 1
paras = source.paragraphs
im_idx = 0
for para in paras:
p = dest.add_paragraph()
r = p.add_run()
if(para.text):
r.add_text(para.text)
root = ET.fromstring(para._p.xml)
namespace = {'wp':"http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing"}
inlines = root.findall('.//wp:inline',namespace)
if(len(inlines) > 0):
uid = "img_"+str(im_idx)
r.add_text("{{ " + uid + " }}")
context[uid] = InlineImage(dest,im_addresses[im_idx])
im_idx += 1
try:
dest.render(context)
except Exception as e:
print(e)
dest.save(dest_path)PS:如果一个段落有两个图像,那么这段代码就会被证明是次优的。我们必须在以下几个方面作出一些改变:
if(len(inlines) > 0):
uid = "img_"+str(im_idx)
r.add_text("{{ " + uid + " }}")
context[uid] = InlineImage(dest,im_addresses[im_idx])
im_idx += 1还必须在for语句中添加一个if循环。因为我不需要,因为通常我的图像足够大,所以它们总是以不同的段落出现。给任何可能需要它的人做个附带说明。
干杯!
Stack Overflow用户
发布于 2018-08-08 18:22:39
你可以试试:
- 通过解压缩.docx文件(每个如何在word 2007 .docx文件中搜索单词?)从第一个文档中提取图像
- 将这些图像保存到文件系统中(例如,作为
foo.png) - 用Python生成新的.docx文件,并使用
document.add_picture('foo.png')添加.png文件。
Stack Overflow用户
发布于 2022-08-18 07:03:34
这个问题是通过这个包https://docxtpl.readthedocs.io/en/latest/解决的。
https://stackoverflow.com/questions/51687223
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号