
全局ItemLoader -乘法器之间的共享
全局ItemLoader -乘法器之间的共享
提问于 2018-08-03 21:10:51
我对Scrapy/Python相当陌生。
我想抓取几个网站,但我将只从每个网站获得三个条目“日期”、"cota“和”名称“,它们每天都更新,并且始终具有相同的xpath。
在抓取所有这些之后,我希望导出到csv文件,但是使用我的代码我得到了以下格式
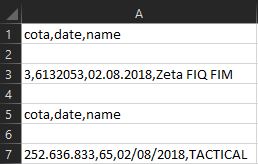
但我想要这样的东西
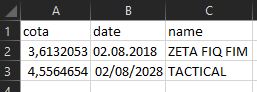
我专门问了关于在多个蜘蛛之间共享同一个ItemLoader的问题,因为这就是我所想到的,但我对其他选择持开放态度。
这是我到目前为止为两个网站编写的脚本,稍后我将添加更多的蜘蛛:
顺便问一下,有了这样的代码,考虑到scrapy是异步的,是否有可能混淆这些值?
# -*- coding: utf-8 -*-
import scrapy
from scrapy.crawler import CrawlerProcess
from scrapy.loader import ItemLoader
class fundo(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
cota = scrapy.Field()
date = scrapy.Field()
class ModalSpider(scrapy.Spider):
name = 'modal'
allowed_domains = ['modalasset.com.br']
start_urls = ['http://modalasset.com.br/cotas-diarias/']
def parse(self, response):
l = ItemLoader(item=fundo(),response=response)
name = response.xpath("//tr[@class='row-6 even']/td/a/text()").extract_first()
date = response.xpath("//tr[@class='row-6 even']/td/text()")[0].extract()
cota = response.xpath("//tr[@class='row-6 even']/td/text()")[1].extract()
l.add_value('name', name)
l.add_value('date', date)
l.add_value('cota', cota)
return l.load_item()
class KapitaloSpider(scrapy.Spider):
name = 'kapitalo'
allowed_domains = ['kapitalo.com.br/relatorios.']
start_urls = ['http://kapitalo.com.br/relatorios.html']
def parse(self, response):
l = ItemLoader(item=fundo(),response=response)
name = response.xpath("//tr[@class='odd']")[1].xpath("td//text()")[0].extract()
date = response.xpath("//*[@class='event layout_full block bygone']/h2/text()")[0].extract()
date = date.replace(' Cotas do Dia: ','')
cota = response.xpath("//tr[@class='odd']")[1].xpath("td//text()")[1].extract()
l.add_value('name', name)
l.add_value('date', date)
l.add_value('cota', cota)
return l.load_item()
process = CrawlerProcess({
'FEED_FORMAT': 'csv',
'FEED_URI': 'result.csv'
})
process.crawl(ModalSpider)
process.crawl(KapitaloSpider)
process.start() # the script will block here until all crawling jobs are finished我尝试的另一种方法是使用下面的代码,但是add_value正在替换ItemLoader中的旧值,但却找不出原因。所以它只返回上一个网站的值。我宁愿使用第一段代码,因为它允许我使用不同类型的蜘蛛,而对于其中一个网站,我可能需要使用Selenium。
# -*- coding: utf-8 -*-
import scrapy
from scrapy.loader import ItemLoader
from scrapy.http import Request
class FundoItem(scrapy.Item):
name = scrapy.Field()
date = scrapy.Field()
cota = scrapy.Field()
class RankingSpider(scrapy.Spider):
name = 'Ranking'
allowed_domains = ['modalasset.com.br',
'kapitalo.com.br'
]
start_urls = ['http://modalasset.com.br/cotas-diarias/']
def parse(self, response):
l = ItemLoader(item=FundoItem(),response=response)
name = response.xpath("//tr[@class='row-6 even']/td/a/text()").extract_first()
date = response.xpath("//tr[@class='row-6 even']/td/text()")[0].extract()
cota = response.xpath("//tr[@class='row-6 even']/td/text()")[1].extract()
#item['name'] = name
#item['date'] = date
#item['cota'] = cota
l.add_value('name', name)
l.add_value('date', date)
l.add_value('cota', cota)
yield Request(url = "http://kapitalo.com.br/relatorios.html",
callback = self.parse_2,
meta={'item':l.load_item()})
def parse_2 (self,response):
name = response.xpath("//tr[@class='odd']")[1].xpath("td//text()")[0].extract()
date = response.xpath("//*[@class='event layout_full block bygone']/h2/text()")[0].extract()
date = date.replace(' Cotas do Dia: ','')
cota = response.xpath("//tr[@class='odd']")[1].xpath("td//text()")[1].extract()
l = ItemLoader(item=response.meta['item'])
l.add_value('name', name)
l.add_value('date', date)
l.add_value('cota', cota)
return l.load_item()回答 1
Stack Overflow用户
回答已采纳
发布于 2018-08-07 20:19:41
看起来这是一个问题,因为windows是如何解释csv文件中的换行符的。我使用以下代码来解决问题,而不是使用FEED_EXPORT:
import csv
with open('test.csv',mode='a',newline='\n') as csv_file:
writer = csv.writer(csv_file)
writer.writerow([name,date,cota,url])newline = '\n'解决了这些问题。
最终代码是:
#Scrapy framework
#CrawlerProcess to run multiple spiders
#csv to export
#sys,inspect to find all the classes(spiders) in this script
import scrapy
from scrapy.crawler import CrawlerProcess
import csv
import sys, inspect
import datetime
#SPIDER DEFINITIONS
class ModalSpider(scrapy.Spider):
name = 'modal'
allowed_domains = ['modalasset.com.br']
start_urls = ['http://modalasset.com.br/cotas-diarias/']
def parse(self, response):
name = response.xpath("//tr[@class='row-6 even']/td/a/text()").extract_first()
date = response.xpath("//tr[@class='row-6 even']/td/text()")[0].extract()
cota = response.xpath("//tr[@class='row-6 even']/td/text()")[2].extract()
write(name,date,cota,response.request.url)
class KapitaloSpider(scrapy.Spider):
name = 'kapitalo'
allowed_domains = ['kapitalo.com.br/relatorios.']
start_urls = ['http://kapitalo.com.br/relatorios.html']
def parse(self, response):
#Zeta FIQ FIM
name = response.xpath("//tr[@class='odd']")[1].xpath("td//text()")[0].extract()
date = response.xpath("//*[@class='event layout_full block bygone']/h2/text()")[0].extract()
date = date.replace(' Cotas do Dia: ','')
date = date.replace('.','/')
cota = response.xpath("//tr[@class='odd']")[1].xpath("td//text()")[1].extract()
write(name,date,cota,response.request.url)
#Kappa FIN FIQ FIM
name = response.xpath("//tr[@class='odd']")[0].xpath("td//text()")[0].extract()
cota = response.xpath("//tr[@class='odd']")[0].xpath("td//text()")[1].extract()
write(name,date,cota,response.request.url)
#write to csv file
#newline='\n' so it won't jump any lines between the entries
def write(name,date,cota,url):
with open('test.csv',mode='a',newline='\n') as csv_file:
writer = csv.writer(csv_file)
writer.writerow([name,date,cota,url])
def crawl():
#create the columns in the csv file
with open('test.csv',mode="w",newline='\n') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(['Nome do Fundo','Data','Cota do dia','URL'])
#get all the members from the script
#if it's a class and it's inside the main (it's a spider)
#then it crawls
process = CrawlerProcess()
for name, obj in inspect.getmembers(sys.modules[__name__]):
if inspect.isclass(obj):
if obj.__module__ == '__main__':
process.crawl(obj)
process.start()
crawl()页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51680112
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号