
抓取器刮不出页面。
我正在使用Rcrawler提取维基百科页面的信息框。我有一个音乐家的名单,我想提取他们的名字,道布,死亡日期,乐器,标签等。然后我想创建一个所有艺术家的数据作为行和数据存储为列/向量。
下面的代码没有抛出错误,但我也没有得到任何结果。当我单独使用rvest时,代码中使用的xpath是有效的。
我的密码怎么了?
library(Rcrawler)
jazzlist<-c("Art Pepper","Horace Silver","Art Blakey","Philly Joe Jones")
Rcrawler(Website = "http://en.wikipedia.org/wiki/Special:Search/", no_cores = 4, no_conn = 4,
KeywordsFilter = jazzlist,
ExtractXpathPat = c("//th","//tr[(((count(preceding-sibling::*) + 1) = 5) and parent::*)]//td",
"//tr[(((count(preceding-sibling::*) + 1) = 6) and parent::*)]//td"),
PatternsNames = c("artist", "dob", "dod"),
ManyPerPattern = TRUE, MaxDepth=1 )回答 2
Stack Overflow用户
发布于 2018-07-31 13:45:25
我可能错了,但我怀疑你认为Rcrawler包的工作方式与它所做的不同。你可能把抓取和爬行搞混了。
Rcrawler简单地从给定的页面开始,并从该页面中抓取任何链接。您可以使用URL筛选器或关键字筛选器缩小路径,但仍然需要通过爬行过程到达这些页面。它不需要搜索。
您从维基百科搜索页面开始的事实表明,您可能希望它按照您在jazzlist中指定的条件运行搜索,但它不会这样做。它只需跟踪维基百科搜索页面中的所有链接。“主页面”、“内容”、“特色内容”从左边的侧边栏,它可能会或不可能最终击中您使用过的术语之一,在这种情况下,它将根据您的xpath参数刮取数据。
您所指定的术语将非常罕见,因此,虽然它可能最终会通过文章交叉链接,比如“特色页面”找到它们,但这将需要非常长的时间。
--我认为你想要的是--根本不使用rvest,而是从搜索词的循环中调用rvest函数。只需将这些术语附加到您提到的搜索URL,并将空格替换为下划线:
library(rvest)
target_pages = paste0('https://en.wikipedia.org/wiki/Special:Search/', gsub(" ", "_", jazzlist))
for (url in target_pages){
webpage = read_html(url)
# do whatever else you want here with rvest functions
}编辑:根据他的评论,在下面添加了OP针对他的具体情况的确切代码的解决方案
library(rvest)
target_pages = paste0('https://en.wikipedia.org/wiki/Special:Search/', gsub(" ", "_", jazzlist))
for (url in target_pages){
webpage = read_html(url)
info<-webpage %>% html_nodes(xpath='//*[contains(concat( " ", @class, " " ), concat( " ", "plainlist", " " ))]') %>% html_text() temp<-data.frame(info, stringsAsFactors = FALSE) data = rbind(data,temp)
}Stack Overflow用户
发布于 2018-11-15 21:19:46
从维基百科URL的特定列表中刮取数据
如果希望使用常见模式刮取特定URL列表,请使用ContentScraper函数:
library(Rcrawler)
jazzlist<-c("Art Pepper","Horace Silver","Art Blakey","Philly Joe Jones")
target_pages = paste0('https://en.wikipedia.org/wiki/Special:Search/', gsub(" ", "_", jazzlist))
DATA<-ContentScraper(Url = target_pages ,
XpathPatterns = c("//th","//tr[(((count(preceding-sibling::*) + 1) = 5) and parent::*)]//td","//tr[(((count(preceding-sibling::*) + 1) = 6) and parent::*)]//td"),
PatternsName = c("artist", "dob", "dod"),
asDataFrame = TRUE)
View(DATA)

从维基百科链接列表中抓取和刮取数据
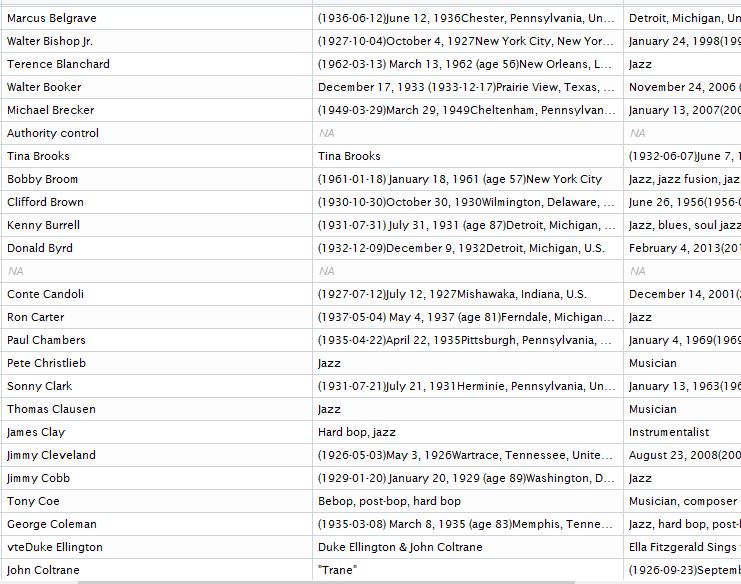
经过一点努力,我在维基百科上找到了一个很难的bop音乐家列表,我想你会对抓取所有这些艺术家的数据感兴趣。在这个例子中,我们将使用Rcrawler函数自动收集和解析所有这些页面。
Rcrawler(Website = "https://en.wikipedia.org/wiki/List_of_hard_bop_musicians" ,
no_cores = 4, no_conn = 4, MaxDepth = 1,
ExtractXpathPat = c("//th","//tr[(((count(preceding-sibling::*) + 1) = 5) and parent::*)]//td","//tr[(((count(preceding-sibling::*) + 1) = 6) and parent::*)]//td"),
PatternsNames = c("artist", "dob", "dod"),
crawlZoneXPath = "//*[@class='mw-parser-output']")
#transform data into dataframe
df<-data.frame(do.call("rbind", DATA))- MaxDepth =1:只抓取起始页面中的链接
- crawlZoneXPath :只抓取页面正文中的链接(艺术家列表)
- ExtractXpathPat :要提取的数据的XPath模式
爬行器创建者
https://stackoverflow.com/questions/51613652
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号