
基于Python和BeautifulSoup的房地产市场掠夺性研究
我需要一些概念,如何使用Python解析房地产市场。我搜索了一些关于解析网站的信息,甚至在VBA中也这样做了,但是我想在python中这样做。
这是一个将被解析的站点(它只是现在的一个报价,但它将处理所有的房地产报价,来自kontrakt.szczecin.pl的多个站点):http://www.kontrakt.szczecin.pl/mieszkanie-sprzedaz-100m2-335000pln-grudziadzka-pomorzany-szczecin-zachodniopomorskie,351149
首先,程序将使用3条信息:
1/ 提供信息的表格(主要参数): Numer oferty 351149、Liczba pokoi 3、Cena 335 000 PLN、Cena za m2 3 350 PLN (报价、房间号、价格、按平方米计价等)。然而,信息的数量取决于物业报价:有时是14,有时是12,有时是16等等。
2/ 在段落中对财产的描述(它是程序的另一部分,现在可以跳过):有时在表(1/)中有关于车库或阳台的信息。但是在第一段中,有句话说车库是为了额外的价格(对我来说,这意味着物业没有车库)或者阳台是法国式的(对我来说不是阳台)。我管理这个程序应该在段落中找到正确的单词(例如车库),并从段落中复制文本,并在左边和右边附加文本(例如:两边都有20个字母,但是如果这个单词位于第一位呢?)
3/ 附加参数-并不是每个报价都有,但就像这个(http://www.kontrakt.szczecin.pl/mieszkanie-sprzedaz-6664m2-339600pln-potulicka-nowe-miasto-szczecin-zachodniopomorskie,351165)一样,有关于酒店阳台数量的信息。有时也有关于地下室的信息。它应该是类似于1/问题的代码。
因此,我尝试了这样的方法,使用一些互联网资源(它仍然不完整):
from urllib.request import urlopen as uReq
from bs4 import BeautifulSoup as soup
my_url = "http://www.kontrakt.szczecin.pl/mieszkanie-sprzedaz-6664m2-339600pln-potulicka-nowe-miasto-szczecin-zachodniopomorskie,351165"
#PL: otwiera połączenie z wybraną stroną, pobieranie zawartości strony (urllib)
#EN: Opens a connection and grabs url
uClient = uReq(my_url)
page_html = uClient.read()
uClient.close()
#html parsing (BeautifulSoup)
page_soup = soup(page_html, "html.parser") #html.parser -> zapisujemy do html, nie np. do xml
#PL: zbiera tabelkę z numerami ofert, kuchnią i innymi danymi o nieruchomości z tabelki
#EN: grabs the data about real estate like kitchen, offer no, etc.
containers = page_soup.findAll("section",{"class":"clearfix"},{"id":"quick-summary"})
# print(len(containers)) - len(containers) sprawdza ile takich obiektów istnieje na stronie
#PL: Co prawda na stronie jest tylko jedna taka tabelka, ale dla dobra nauki zrobię tak jak gdyby tabelek było wiele.
#EN: There is only one table, but for the sake of knowledge I do the container variable
container = containers[0]
find_dt = container.findAll("dt")
find_dd = container.findAll("dd")
print(find_dt[0].text + " " + find_dd[0])这是可行的,但仍然不完整。我现在不想继续了,因为有很大的缺陷。正如您看到的最后一次打印,它需要索引,但并不是每个属性都有相同的顺序(因为正如我所提到的,有时有10条信息,有时更多,有时更少)。这将是一个巨大的混乱在CSV。
我的VBA程序就是这样工作的:
- 将表格复制到Excel (表格1)
- 在表2中有程序正在寻找的参数(例如价格)。
- 快捷方式中的机制:从第2页复制参数(价格),转到第1页(其中被解析的信息),查找价格字符串(粘贴来自工作表2的信息:“价格”),在下面行,复制价格值,转到第2页,找到价格,然后粘贴价格值。诸若此类。
寻找帮助的概念和编码也。
编辑:第1部分和第2部分已经准备好了。但是,我对第3部分有很大的问题。
from urllib import request as uReq
import requests
#dzięki temu program jest zamykany odrazu, i nie kontynuuje wykonywania reszty kodu. Po imporcie wystarczy exit(0)
from sys import exit
from urllib.request import urlopen as uReq2
from bs4 import BeautifulSoup as soup
import csv
import re
import itertools
filename = 'test.txt'
#licznik, potrzebny do obliczenia ilości numerów ofert w pliku .txt
num_lines = 0
# tworzymy listę danych i listę URLi. Wyniki będą dodawane do list, dlatego potrzeba jest ich utworzenia (jako puste)
list_of_lines = ['351238', '351237', '111111', '351353']
list_of_lines2 = []
list_of_URLs = []
list_of_redictered_URLs = []
KONTRAKT = 'http://www.kontrakt.szczecin.pl'
with open(filename, 'r') as file:
for line in file:
#dodajemy linię (ofertę) do listy
list_of_lines.append(line.strip())
#num_lines jest licznikiem, wskazuje ile wierszy zawiera lista, zmienna jest istotna w zakresię tworzenia pętli z adresami URL
num_lines += 1
#tworzymy URLe z Numerów Ofert zawartych w filename
for i in range(num_lines):
nr_oferty = list_of_lines[i]
my_url = "http://www.kontrakt.szczecin.pl/lista-ofert/?f_listingId=" + nr_oferty + "&f=&submit=Szukaj"
list_of_URLs.append(my_url)
print(list_of_URLs)
#Cześć druga: konwertowanie listy linków na listę linków przekierowanych
#Program wchodzi na stronę, która powinna być przekierowana, jednak ze względu na użyscie Java Scriptu,
#zadanie zostało utrudnione. Dlatego, też celem programu jest symulowanie przeglądarki, pobranie
#zawartości strony, a następnie 'wyłuskanie' odpowiedniego linku do przekierowania
i = 0
for i in range(num_lines):
url_redirect = list_of_URLs[i]
my_url = url_redirect
BROWSER = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
response = requests.get(my_url, headers=BROWSER)
script1 = '<script>'
script2 = '</script>'
content_URL = str(response.content)
find_script1 = (content_URL.find(script1))
find_script2 = (content_URL.find(script2))
url_ready = content_URL[find_script1:find_script2]
print(i+1,'z', num_lines, '-', 'oferta nr:', str(my_url[57:57+6]))
list_of_redictered_URLs.append(url_ready)
#usuwanie zbędnych tagów i znaków, w celu uzyskania czystego przekierowanego linku
list_of_redictered_URLs = [w.replace('<script>window.location=\\\'','') for w in list_of_redictered_URLs]
list_of_redictered_URLs = [w.replace('\\\';','') for w in list_of_redictered_URLs]
#print(list_of_redictered_URLs)
#usuwanie pustych wierszy z listy (oferty, które są nieakutalne na liste "wchodzą jako puste" !!! item: jest to zmienna, można zamienić np. na janusz.
filtered_list = list(filter(lambda item: item.strip(), list_of_redictered_URLs))
filtered_list = [KONTRAKT + item for item in filtered_list]
#zmiana na tuple, ze względu iż mutowalność (dodawanie kolejnych linków) nie będzie potrzebne
filtered_list = tuple(filtered_list)
#print(str(filtered_list))
print('Lista linków:\n',filtered_list)
# Kolejną częścią programu jest pobieranie istotnych informacji (parametrów podstawowych)
# ze strony kontrakt.szczecin.pl, a następnie ich zapisanie w pliku csv.
# Nagłówki w csv oraz nazwy parametrów na stronie (muszą być identyczne jak na stronie, aby mogły
# zostać odpowiednio przyporządkowane w .csv)
HEADERS = ['Numer oferty',
'Liczba pokoi',
'Cena',
'Cena za m2',
'Powierzchnia',
'Piętro',
'Liczba pięter',
'Typ kuchni',
'Balkon',
'Czynsz administracyjny',
'Rodzaj ogrzewania',
'Umeblowanie',
'Wyposażona kuchnia',
'Gorąca woda',
'Rodzaj budynku',
'Materiał',
'Rok budowy',
'Stan nieruchomości',
'Rynek',
'Dach:',
'Liczba balkonów:',
'Liczba tarasów:',
'Piwnica:',
'Ogród:',
'Ochrona:',
'Garaż:',
'Winda:',
'Kształt działki:',
'Szerokość działki (mb.):',
'Długość działki (mb.):',
'Droga dojazdowa:',
'Gaz:',
'Prąd:',
'Siła:','piwnica',
'komórk',
'strych',
'gospodarcze',
'postojow',
'parking',
'przynależn',
'garaż',
'ogród',
'ogrod',
'działka',
'ocieplony',
'moderniz',
'restaur',
'odnow',
'ociepl',
'remon',
'elew',
'dozór',
'dozor',
'monitoring',
'monit',
'ochron',
'alarm',
'strzeż',
'portier',
'wspólnot',
'spółdziel',
'kuchni',
'aneks',
'widna',
'ciemna',
'prześwit',
'oficyn',
'linia',
'zabudow',
'opłat',
'bezczynsz',
'poziom',
'wind',
'francuski',
'ul.',
'w cenie',
'dodatkową']
LINKI = ["Link"]
#HEADERS2 = ['Liczba balkonów:',
# 'Liczba tarasów:',
# 'Piwnica:',
# 'Ogród:',
# 'Ochrona:',
# 'Garaż:',
# 'Winda:']
HEADERS3 = ['piwnica',
'komórk',
'strych',
'gospodarcze',
'postojow',
'parking',
'przynależn',
'garaż',
'ogród',
'ogrod',
'działka',
'ocieplony',
'moderniz',
'restaur',
'odnow',
'ociepl',
'remon',
'elew',
'dozór',
'dozor',
'monitoring',
'monit',
'ochron',
'alarm',
'strzeż',
'portier',
'wspólnot',
'spółdziel',
'kuchni',
'aneks',
'widna',
'ciemna',
'prześwit',
'oficyn',
'linia',
'zabudow',
'opłat',
'bezczynsz',
'poziom',
'wind',
'francuski',
'ul.',
'w cenie',
'dodatkową',]
csv_name = 'data.csv'
print('Dane zostaną zapisane do pliku:',csv_name + '.csv')
print('\n>>>>Program rozpoczyna pobieranie danych')
#Pobieranie linków
i = 0
#Tworzy plik csv o nazwie csv
#writerow może mieć tylko jeden argument, dlatego jest nim suma poszczególnych list. Lista
#linki ma jędną pozycję, ponieważ można sumować dane jednego typu. Nie można sumować listy ze stringami.
with open(csv_name + '.csv', 'w', newline='') as csvfile:
csvwriter = csv.writer(csvfile, delimiter=',', quotechar='"')
HEADERS_ALL = HEADERS+HEADERS3+LINKI
csvwriter.writerow(HEADERS_ALL)
for i in range(len(filtered_list)):
my_url = filtered_list[i]
with uReq2(my_url) as uClient:
page_soup = soup(uClient.read(), 'lxml')
print('\t\t-----------',i+1,'-----------\n',my_url)
#<dt> - nazwa parametru np. Kuchnia
#<dd> - wartość parametru np. widna
row = ['-'] * len(HEADERS) + ['-'] * len(HEADERS3) + ['-'] * len(LINKI)
# Parametry podstawowe (kontrakt.szczecin.pl)
for dt, dd in zip(page_soup.select('section#quick-summary dt'), page_soup.select('section#quick-summary dd')):
if dt.text.strip() not in HEADERS:
print("\n 1(dt,dd):UWAGA!, kolumna [{}] nie istnieje w nagłówkach! (stała: HEADERS)\n".format(dt.text.strip()))
continue
row[HEADERS.index(dt.text.strip())] = dd.text.strip()
# Parametry dodatkowe
for span, li in zip(page_soup.select('section#property-features span'), page_soup.select('section#property-features li')):
if span.text.strip() not in HEADERS:
print("\n 2:UWAGA(span,li), kolumna [{}] nie istnieje w nagłówkach (stała HEADERS)!\n".format(span.text.strip()))
continue
row[HEADERS.index(span.text.strip())] = li.text.strip()
#csvwriter.writerow(row)
print(row)
#No to zaczynamy zabawę...................................
# zmienna j odnosi się do indeksu HEADERS3, jest to j nie i, ponieważ i jest w dalszym użyciu
# w pętli powyżej
for p in page_soup.select('section#description'):
p = str(p)
p = p.lower()
for j in range(len(HEADERS3)):
#print('j:',j)
# find_p znajduje wszystkie słowa kluczowe z HEADERS3 w paragrafie na stronie kontraktu.
find_p = re.findall(HEADERS3[j],p)
# listy, które wyświetlają pozycję startową poszczególnych słów muszą zaczynać się od '-' lub 0?,
# ponieważ, gdy dane słowo nie zostanie odnalezione to listy będą puste w pierwszej iteracji pętli
# co w konsekewncji doprowadzi do błędu out of range
m_start = []
m_end = []
lista_j = []
for m in re.finditer(HEADERS3[j], p):
#print((m.start(),m.end()), m.group())
m_start.append(m.start())
m_end.append(m.end())
#print(h)
for k in range(len(m_start)):
#właściwe teraz nie wiem po co to jest..
try:
x = m_start[k]
y = m_end[k]
except IndexError:
x = m_start[0]
y = m_end[0]
#print('xy:',x,y)
#print(find_p)
#print(HEADERS3[j])
z = (HEADERS3[j]+':',p[-60+x:y+60]+' ++-NNN-++')
lista_j.append(z)
print (lista_j)
print(str(lista_j))
row[HEADERS.index(span.text.strip())] = str(lista_j)
csvwriter.writerow(row)
#print(row)回答 1
Stack Overflow用户
发布于 2018-07-30 12:38:49
此代码段将解析属性url的快速汇总表并将其保存在csv文件中:
from urllib.request import urlopen as uReq
from bs4 import BeautifulSoup as soup
import csv
# my_url = 'http://www.kontrakt.szczecin.pl/mieszkanie-sprzedaz-6664m2-339600pln-potulicka-nowe-miasto-szczecin-zachodniopomorskie,351165'
my_url = 'http://www.kontrakt.szczecin.pl/mieszkanie-sprzedaz-100m2-335000pln-grudziadzka-pomorzany-szczecin-zachodniopomorskie,351149'
with uReq(my_url) as uClient:
page_soup = soup(uClient.read(), 'lxml')
with open('data.csv', 'w', newline='') as csvfile:
csvwriter = csv.writer(csvfile, delimiter=',', quotechar='"')
for dt, dd in zip(page_soup.select('section#quick-summary dt'), page_soup.select('section#quick-summary dd')):
csvwriter.writerow([dt.text.strip(), dd.text.strip()])结果是在data.csv中,截图从我的LibreOffice:
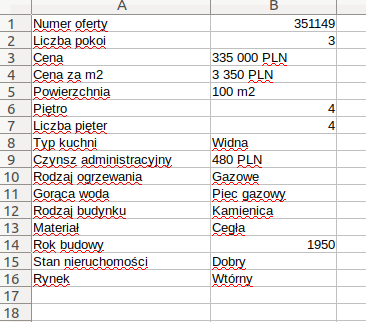
对于转换表,可以使用以下代码:
from urllib.request import urlopen as uReq
from bs4 import BeautifulSoup as soup
import csv
# my_url = 'http://www.kontrakt.szczecin.pl/mieszkanie-sprzedaz-6664m2-339600pln-potulicka-nowe-miasto-szczecin-zachodniopomorskie,351165'
my_url = 'http://www.kontrakt.szczecin.pl/mieszkanie-sprzedaz-100m2-335000pln-grudziadzka-pomorzany-szczecin-zachodniopomorskie,351149'
with uReq(my_url) as uClient:
page_soup = soup(uClient.read(), 'lxml')
headers = ['Numer oferty',
'Liczba pokoi',
'Cena',
'Cena za m2',
'Powierzchnia',
'Piętro',
'Liczba pięter',
'Typ kuchni',
'Balkon',
'Czynsz administracyjny',
'Rodzaj ogrzewania',
'Gorąca woda',
'Rodzaj budynku',
'Materiał',
'Rok budowy',
'Stan nieruchomości',
'Rynek',
'Dach:',
'Liczba balkonów:',
'Piwnica:',
'Kształt działki:',
'Szerokość działki (mb.):',
'Długość działki (mb.):',
'Droga dojazdowa:',
'Gaz:',
'Prąd:',
'Siła:']
with open('data.csv', 'w', newline='') as csvfile:
csvwriter = csv.writer(csvfile, delimiter=',', quotechar='"')
csvwriter.writerow(headers)
row = ['-'] * len(headers)
for dt, dd in zip(page_soup.select('section#quick-summary dt'), page_soup.select('section#quick-summary dd')):
if dt.text.strip() not in headers:
print("Warning, column [{}] doesn't exist in headers!".format(dt.text.strip()))
continue
row[headers.index(dt.text.strip())] = dd.text.strip()
csvwriter.writerow(row)结果将出现在这样的csv文件中(不存在的值将被‘-’替换):

https://stackoverflow.com/questions/51592631
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号