
在熊猫多索引上添加自动增量列
在熊猫多索引上添加自动增量列
提问于 2018-07-27 16:31:40
下面我有一只多索引熊猫。我试图创造:
- 从"project_rank“派生的自动增量计数器
- "lob“中项目的最大计数
然而,我不知道如何才能做到这一点。任何指点都能帮上忙
Raw df_matrix之前:
print(df_matrix.head(10))
lob project_rank duration_in_status
0 Commodities CM LOB 2.0
1 Commodities Index Book Migration 25.0
2 Cross Platform CM LOB 0.0
3 Cross Platform CSAVA 16.0
4 Cross Platform Calypso Migration 0.0
5 Cross Platform EMD / Delta One 0.0
6 Cross Platform FRTB 68.0
7 Cross Platform Index Book Migration 1.0
8 Cross Platform Instruments 3.0
9 Cross Platform KOJAK 0.0多索引之前:
duration_in_status
lob project_rank
Commodities CM LOB 2.0
Index Book Migration 25.0
Cross Platform CM LOB 0.0
CSAVA 16.0
Calypso Migration 0.0
EMD / Delta One 0.0
FRTB 68.0
Index Book Migration 1.0
Instruments 3.0
KOJAK 0.0
LOB BOW 324.0
Non-Trading 0.0
Notes Workflow 23.0
PROD 0.0
Result Service 53.0
Tech Debt 96.0
Interest Rates LOB BOW 0.0
Other Notes Workflow 0.0
Treasury 2B2 1.0验收标准结果:
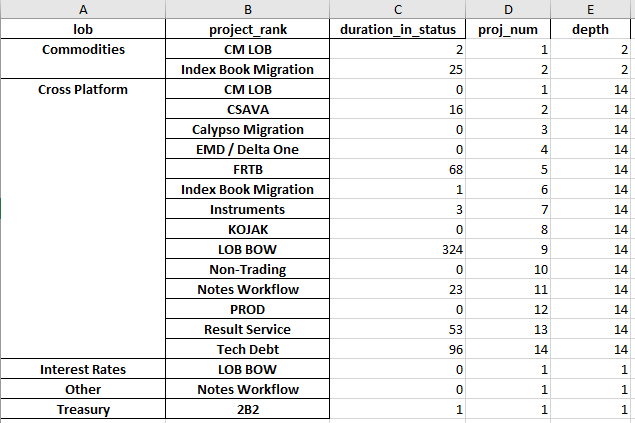
回答 2
Stack Overflow用户
回答已采纳
发布于 2018-07-27 18:16:20
好像你想
df['proj_num'] = df.groupby('lob').project_rank.cumcount() + 1
df['depth'] = df.groupby('lob').project_rank.transform(len)在应用多个索引之前:)
lob project_rank duration_in_status proj_num depth
0 Commodities CMLOB 2.0 1 2
1 Commodities IndexBookMigration 25.0 2 2
2 Cross_Platform CMLOB 0.0 1 8
3 Cross_Platform CSAVA 16.0 2 8
4 Cross_Platform CalypsoMigration 0.0 3 8
5 Cross_Platform EMD/DeltaOne 0.0 4 8
6 Cross_Platform FRTB 68.0 5 8
7 Cross_Platform IndexBookMigration 1.0 6 8
8 Cross_Platform Instruments 3.0 7 8
9 Cross_Platform KOJAK 0.0 8 8Stack Overflow用户
发布于 2018-07-27 16:44:50
我只想用groupby来申请。
# assuming "df" is the variable containing the data as you showed in the question...
import numpy as np
def group_function(sub_dataframe):
sub_dataframe["proj_num"] = np.arange(df.shape[0]) + 1
sub_dataframe["depth"] = df.shape[0]
return sub_dataframe
df = df.reset_index().groupby("lob").apply(group_function)
df = df.set_index(["lob","project_rank"])如果您正在创建以前创建的multiindex,您可以在此之前完成此操作。这样,您就不需要reset_index,只能创建一次。
# in that case, something like this should work.
df = df.groupby("lob").apply(group_function). df.set_index(["lob","project_rank"])页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51562104
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号