
pandas.unique()的奇怪内存消耗
在分析算法的内存消耗时,我感到惊讶的是,有时为了更小的输入,需要更多的内存。
这一切归结为pandas.unique()的下列用法
import numpy as np
import pandas as pd
import sys
N=int(sys.argv[1])
a=np.arange(N, dtype=np.int64)
b=pd.unique(a)对于N=6*10^7,它需要3.7GB峰值内存,但是使用N=8*10^7“只”使用3GB。
扫描不同的输入大小会得到以下图形:
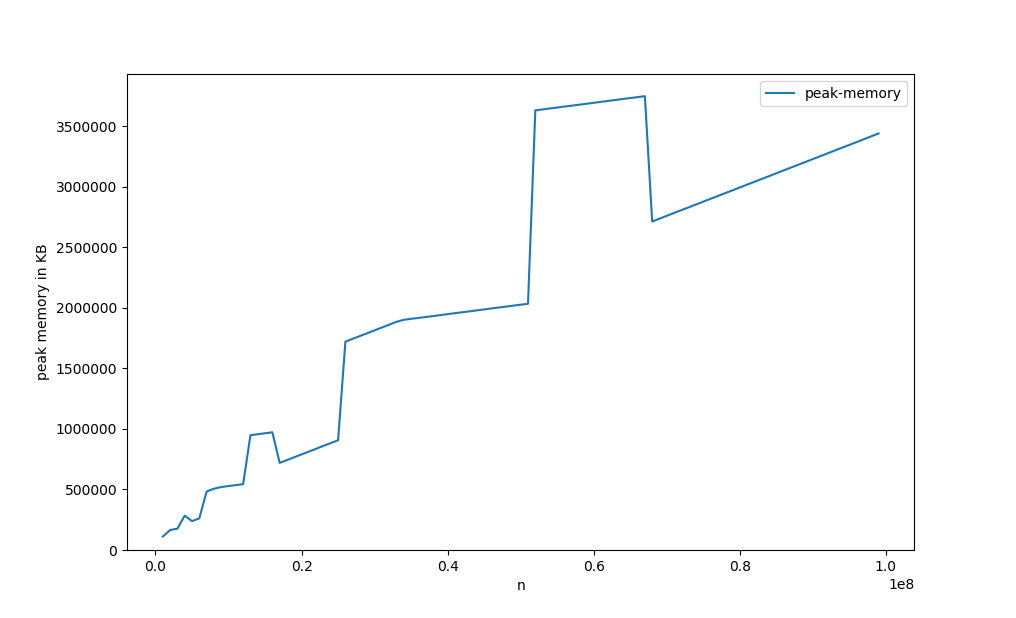
出于好奇和自我教育:如何解释N=5*10^7、N=1.3*10^7周围的反直觉行为(例如,对于较小输入大小的,可以解释更多的内存)?
下面是在Linux上生成内存消耗图的脚本:
pandas_unique_test.py
import numpy as np
import pandas as pd
import sys
N=int(sys.argv[1])
a=np.arange(N, dtype=np.int64)
b=pd.unique(a)show_memory.py
import sys
import matplotlib.pyplot as plt
ns=[]
mems=[]
for line in sys.stdin.readlines():
n,mem = map(int, line.strip().split(" "))
ns.append(n)
mems.append(mem)
plt.plot(ns, mems, label='peak-memory')
plt.xlabel('n')
plt.ylabel('peak memory in KB')
ymin, ymax = plt.ylim()
plt.ylim(0,ymax)
plt.legend()
plt.show()run_perf_test.sh
WRAPPER="/usr/bin/time -f%M" #peak memory in Kb
N=1000000
while [ $N -lt 100000000 ]
do
printf "$N "
$WRAPPER python pandas_unique_test.py $N
N=`expr $N + 1000000`
done 现在:
sh run_perf_tests.sh 2>&1 | python show_memory.py回答 1
Stack Overflow用户
发布于 2020-02-20 21:56:45
@AKX的答案解释了为什么内存消耗在跳跃中增加,但并没有解释为什么会随着更多的元素而减少--这个答案填补了空白。
pandas使用khash-map来查找唯一的元素。创建散列映射时,数组被用作提示。中的元素数。
def unique(values):
...
table = htable(len(values))
...但是,暗示的意义是“映射中将有n个值”:
cdef class {{name}}HashTable(HashTable):
def __cinit__(self, int64_t size_hint=1):
self.table = kh_init_{{dtype}}()
if size_hint is not None:
size_hint = min(size_hint, _SIZE_HINT_LIMIT)
kh_resize_{{dtype}}(self.table, size_hint)然而,khash将其理解为水桶 (而不是我们需要一个n元素的位置):
SCOPE void kh_resize_##name(kh_##name##_t *h, khint_t new_n_buckets)
...这是两个有关khash-map中桶数的重要实现细节:
后果是什么?让我们来看看一个包含1023个元素的数组:
- 哈希映射在开始时将有1024个桶(比元素数大两个的最小功率),但足够容纳大约800个元素(即从1024到77% )。
- 在添加约800个元素后,大小将调整为2048个元素(下一个功率为2),这意味着峰值消耗将是3072 (同时需要旧的和新的数组)。
有1025个元素的数组会发生什么情况?
- 哈希映射在开始时将有2048个桶(比元素数大两个的最小幂),并且足够容纳大约1600个元素(即从2048年起的77% )。
- 这将不会重新散列,峰值消耗将停留在2048,因此需要更少的内存。
这种内存消耗模式将在阵列大小每增加一倍时发生.这就是我们所观察到的。
对较小影响的解释:
- 内存消耗的每一秒跳转都不会伴随着减少:唯一的元素存储在四倍大的向量中(这样,每秒钟就可以看到一倍的大小)。必须复制元素,这样内存就会被复制一次,从而隐藏哈希映射的更小的用途。
- 随着元素被添加到唯一的向量中,越来越多的内存页被提交:使用的
np.resize零附加内存(至少在Linux上)。
这里有一个小实验表明,np.zeros(...)不提交内存,而是只保留内存:
import numpy as np
import psutil
process = psutil.Process()
old = process.memory_info().rss
a=np.zeros(10**8)
print("commited: ", process.memory_info().rss-old)
# commited: 0, i.e. nothign
a[0:100000] = 1.0
print("commited: ", process.memory_info().rss-old)
# commited: 2347008, more but not all
a[:] = 1.0
print("commited: ", process.memory_info().rss-old)
# commited: 799866880, i.e. all注:a=np.full(10**8, 0.0)将直接提交内存。
https://stackoverflow.com/questions/51485816
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号