
Regex捕获2行以上的regex匹配
Regex捕获2行以上的regex匹配
提问于 2018-07-22 11:53:46
需要帮助得到上述单词(颧骨,佐马,ZYGMA)后,匹配名词男性。我试过不同的旗帜,如多行和多特,但仍然没有运气得到以上的主要词。如有任何帮助,将不胜感激。
import re
def main():
mytext = open("m.txt")
mypattern = re.compile('n. (m.|f.)')
for line in mytext:
match = re.search(mypattern, line)
if match:
print(match.group())
if __name__ == "__main__":
main()我作为示例使用的文本是:
颧骨 解剖学硕士。拉焦厄人。 佐马 解剖学硕士。拉焦厄人。 ZYGMA 解剖学硕士。拉焦厄人。
我将解析的主文件是什么样子的:
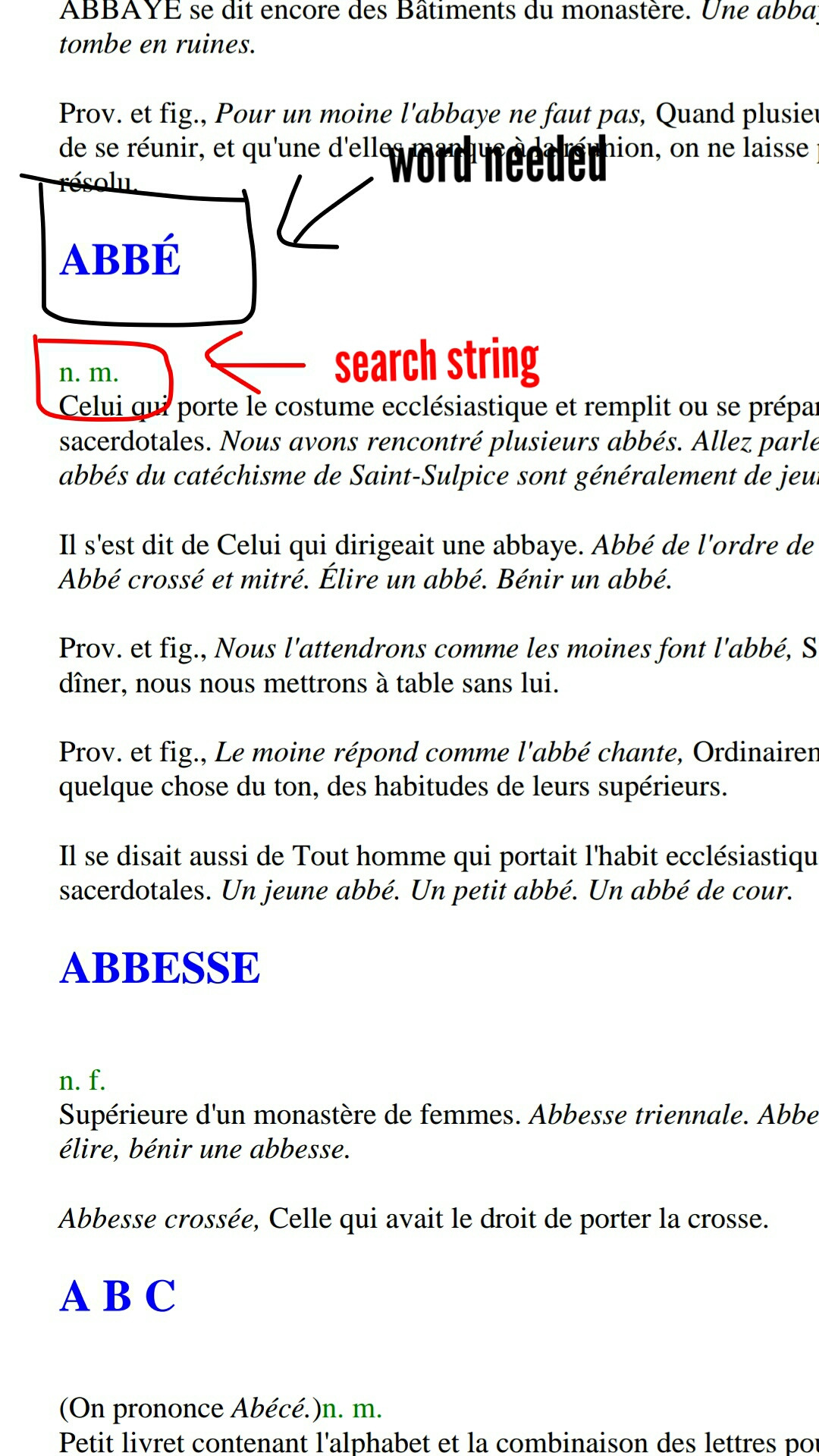
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-07-22 12:07:21
意味着搜索的单词是大写的:
import re
text = """
ZYGOMA
n. m. T. d'Anatomie . Os de la pommette de la joue.
ZOMA
n. m. T. d'Anatomie . Os de la pommette de la joue.
ZYGMA
n. m. T. d'Anatomie . Os de la pommette de la joue.
A B C
n. m. T. d'Anatomie . Os de la pommette de la joue.
"""
g = re.findall(r'([A-Z][A-Z ]*)\s+(?=n\. m|f)', text)
print(g)将印刷:
['ZYGOMA', 'ZOMA', 'ZYGMA', 'A B C']对于Unicode大写单词,解决方案如下:Python regex for unicode capitalized words
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51464839
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号