
如何从聚类分析结果中求取意义/值
我目前正在做我的MasterThesis,为了我的MasterThesis,我想要创建一个模拟老年人走路行为的模拟模型。然而,为了使我的模拟模型更容易,我想要基于聚类分析形成组,这样如果老年人属于某个组,就可以很容易地将特定的步行行为分配给它(因此,如果您属于第一组,您的步行时间(例如,以分钟为单位)大约为20分钟)。
然而,我对聚类分析并不那么熟悉。我有一个大数据集,其中包含关于老年人特征的许多数据(**离散和连续性质的变量**),但是,目前在文献基础上使用了以下特征:
年龄、性别、健康分数、教育程度、收入类别、职业、社交网络、在一个舒适的社区生活的是/否、在附近感到安全的是/否、到绿色的距离、养一只狗、步行时间、几分钟内步行。
在使用daisy函数并使用剪影方法定义集群/组的理想数量之后,我得到了集群。然而,现在我想知道应该如何从集群中派生,即。我发现很难使用统计函数,如平均值,因为我处理的是类别。因此,我能做些什么来从每个集群中得出有用的meaning/statistical结论,比如,如果你属于集群group1,你的收入水平应该在第10组左右,年龄应该在70岁左右,步行时间在20分钟左右。理想情况下,我也希望在每个集群组中有每个变量的标准差。因此,我可以很容易地在我的模拟模型中使用这些值来将特定的行走行为分配给老年人。
回答 1
Stack Overflow用户
发布于 2018-07-22 06:45:43
@Joy,你应该先确定相关的变量。这也将有助于降维。由于您没有给出要处理的示例数据集,所以我正在创建自己的数据集。此外,在进行聚类分析之前,您必须注意,获得属于pure的集群非常重要。对于纯度而言,我的意思是集群必须包含only those variables that account for maximum variance in the data。显示出很少到可忽略的方差的变量最好被删除,因为它们不是集群模型的贡献者。一旦有了这些(statistically)重要变量,聚类分析就有意义了。
理论概念
聚类是一种预处理算法。必须从统计上有意义的变量中提取pure clusters。分类任务中这些significant variables的派生称为特征选择,而在聚类任务中则称为主组件(PC)。从历史上看,PC机只对连续变量工作。从范畴变量导出PC机,有一种方法称为对应分析(CA),对于名义范畴变量,可以采用多重对应分析(MCA)方法。
实用实现
让我们创建一个包含混合变量(即分类变量和连续变量)的数据框架,例如,
R> digits = 0:9
# set seed for reproducibility
R> set.seed(17)
# function to create random string
R> createRandString <- function(n = 5000) {
a <- do.call(paste0, replicate(5, sample(LETTERS, n, TRUE), FALSE))
paste0(a, sprintf("%04d", sample(9999, n, TRUE)), sample(LETTERS, n, TRUE))
}
R> df <- data.frame(ID=c(1:10), name=sample(letters[1:10]),
studLoc=sample(createRandString(10)),
finalmark=sample(c(0:100),10),
subj1mark=sample(c(0:100),10),subj2mark=sample(c(0:100),10)
)
R> str(df)
'data.frame': 10 obs. of 6 variables:
$ ID : int 1 2 3 4 5 6 7 8 9 10
$ name : Factor w/ 10 levels "a","b","c","d",..: 2 9 4 6 3 7 1 8 10 5
$ studLoc : Factor w/ 10 levels "APBQD6181U","GOSWE3283C",..: 5 3 7 9 2 1 8 10 4 6
$ finalmark: int 53 73 95 39 97 58 67 64 15 81
$ subj1mark: int 63 18 98 83 68 80 46 32 99 19
$ subj2mark: int 90 40 8 14 35 82 79 69 91 2我将在数据中注入随机缺失的值,以便它更类似于真实世界的数据集。
# add random NA values
R> df<-as.data.frame(lapply(df, function(cc) cc[ sample(c(TRUE, NA), prob = c(0.85, 0.15), size = length(cc), replace = TRUE) ]))
R> colSums(is.na(df))
ID name studLoc finalmark subj1mark subj2mark
0 0 0 2 2 0如您所见,缺少的值位于连续变量finalmark和subj1mark中。我选择做中位估算而不是平均,因为中位数比平均值更健壮。
# Create a function to impute the missing values
R> ImputeMissing<- function(data=df){
# check if data frame
if(!(is.data.frame(df))){
df<- as.data.frame(df)
}
# Loop through the columns of the dataframe
for(i in seq_along(df))
{
if(class(df[,i]) %in% c("numeric","integer")){
# missing continuous data to be replaced by median
df[is.na(df[,i]),i] <- median(df[,i],na.rm = TRUE)
} # end inner-if
} # end for
return(df)
} # end function
# Remove the missing values
R> df.complete<- ImputeMissing(df)
# check missing values
R> colSums(is.na(df.complete))
ID name studLoc finalmark subj1mark subj2mark
0 0 0 0 0 0 现在,我们可以将FAMD()方法从FactoMineR包应用到cleaned数据集。您可以在R控制台中键入、??FactoMineR::FAMD以查看此方法的小片段。FAMD是一种主成分方法,用于研究连续变量和范畴变量的数据。它大致可以看作是PCA和MCA之间的混合。更准确地说,连续变量被缩放成单位方差,分类变量被转换成一个分离数据表(清晰编码),然后使用MCA的特定尺度进行缩放。这确保了在分析中平衡连续变量和绝对变量的影响。这意味着这两个变量在确定可变性的维度时是站在一个同等的位置上的。
R> df.princomp <- FactoMineR::FAMD(df.complete, graph = FALSE)此后,我们可以使用screeplot显示在fig1上的个人电脑,
R> factoextra::fviz_screeplot(df.princomp, addlabels = TRUE,
barfill = "gray", barcolor = "black",
ylim = c(0, 50), xlab = "Principal Component",
ylab = "Percentage of explained variance",
main = "Principal Component (PC) for mixed variables")
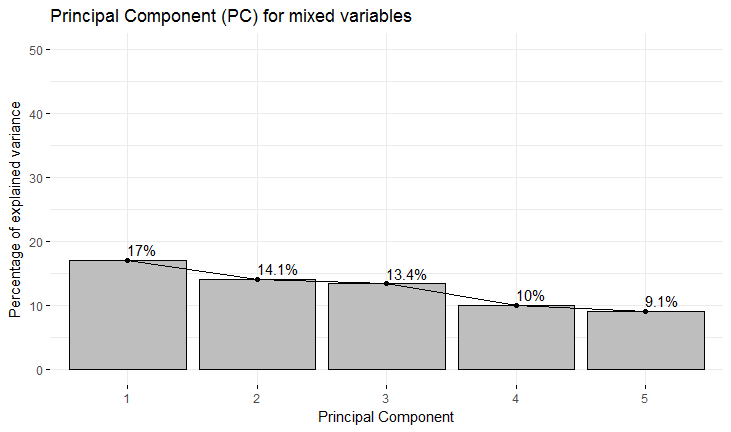
Scree图(如fig1中所示)是一个简单的线段图,它显示由每个主成分(PC)解释或表示的数据中总方差的分数。因此,我们可以看到,前三个个人电脑共同承担了44.5%的总方差。现在自然出现的问题是:“这些变量是什么?”
为了提取变量的贡献,我使用了类似于fviz_contrib()的fig2,
R> factoextra::fviz_contrib(df.princomp, choice = "var",
axes = 1, top = 10, sort.val = c("desc"))
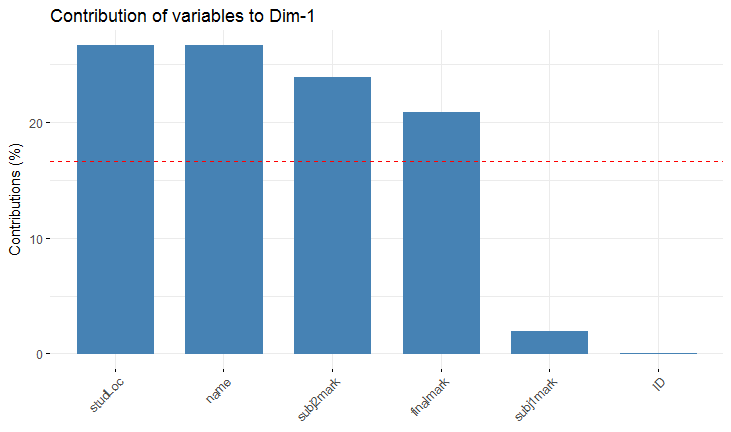
上面的fig2可视化了主成分分析(PCA)结果中行/列的贡献。从这里我可以看到变量,studLoc,name,subj2mark和finalMark是最重要的变量,可以用于进一步的分析。
现在,您可以继续进行聚类分析。
# extract the important variables and store in a new dataframe
R> df.princomp.impvars<- df.complete[,c(2:3,6,4)]
# make the distance matrix
R> gower_dist <- cluster::daisy(df.princomp.impvars,
metric = "gower",
type = list(logratio = 3))
R> gower_mat <- as.matrix(gower_dist)
#make a hierarchical cluster model
R> model<-hclust(gower_dist)
#plotting the hierarchy
R> plot(model)
#cutting the tree at your decided level
R> clustmember<-cutree(model,3)
#adding the cluster member as a column to your data
R> df.clusters<-data.frame(df.princomp.impvars,cluster=clustmember)
R> df.clusters
name studLoc subj2mark finalmark cluster
1 b POTYQ0002N 90 53 1
2 i LWMTW1195I 40 73 1
3 d VTUGO1685F 8 95 2
4 f YCGGS5755N 14 70 1
5 c GOSWE3283C 35 97 2
6 g APBQD6181U 82 58 1
7 a VUJOG1460V 79 67 1
8 h YXOGP1897F 69 64 1
9 j NFUOB6042V 91 70 1
10 e QYTHG0783G 2 81 3https://stackoverflow.com/questions/51456153
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号