
更改xticks matplotlib
我有一个散点图,上面有x-axis的时间
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import ticker
d = ({
'A' : ['08:00:00','08:10:00','08:12:00','08:26:00','08:29:00','08:31:00','10:10:00','10:25:00','10:29:00','10:31:00'],
'B' : ['1','1','1','2','2','2','7','7','7','7'],
'C' : ['X','Y','Z','X','Y','Z','A','X','Y','Z'],
})
df = pd.DataFrame(data=d)
fig,ax = plt.subplots()
x = df['A']
y = df['B']
x_numbers = (pd.to_timedelta(df['A']).dt.total_seconds())
plt.scatter(x_numbers, y)
plt.show()产出1:
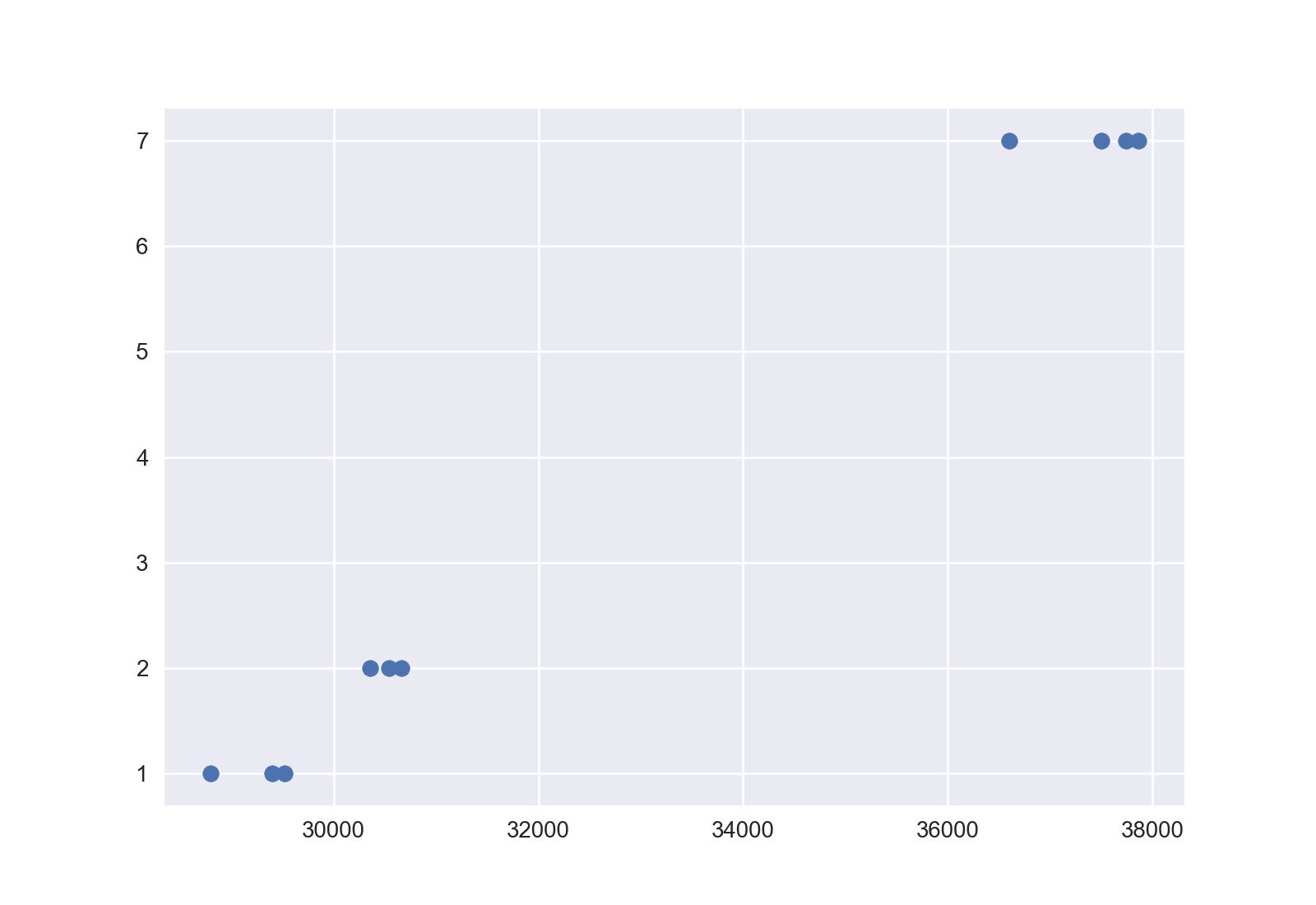
我想用总秒来交换实际的时间戳,所以我包括:
plt.xticks(x_numbers, x)这导致x-滴答相互重叠。
如果我用:
plt.locator_params(axis='x', nbins=10) 结果与上述相同。如果我把nbins改为更小的东西,滴答就不会重叠,但它们不会对齐它们各自的散点点。与散点点一样,不要用正确的时间戳对齐。
如果我用:
M = 10
xticks = ticker.MaxNLocator(M)
ax.xaxis.set_major_locator(xticks) ticks不重叠,但不对齐它们各自的散点点。
是否可以选择使用的x-ticks数量,但仍与相应的数据点对齐。
例如,用于下面的figure。我能不能只使用n号码的ticks而不是所有的?
产出2:
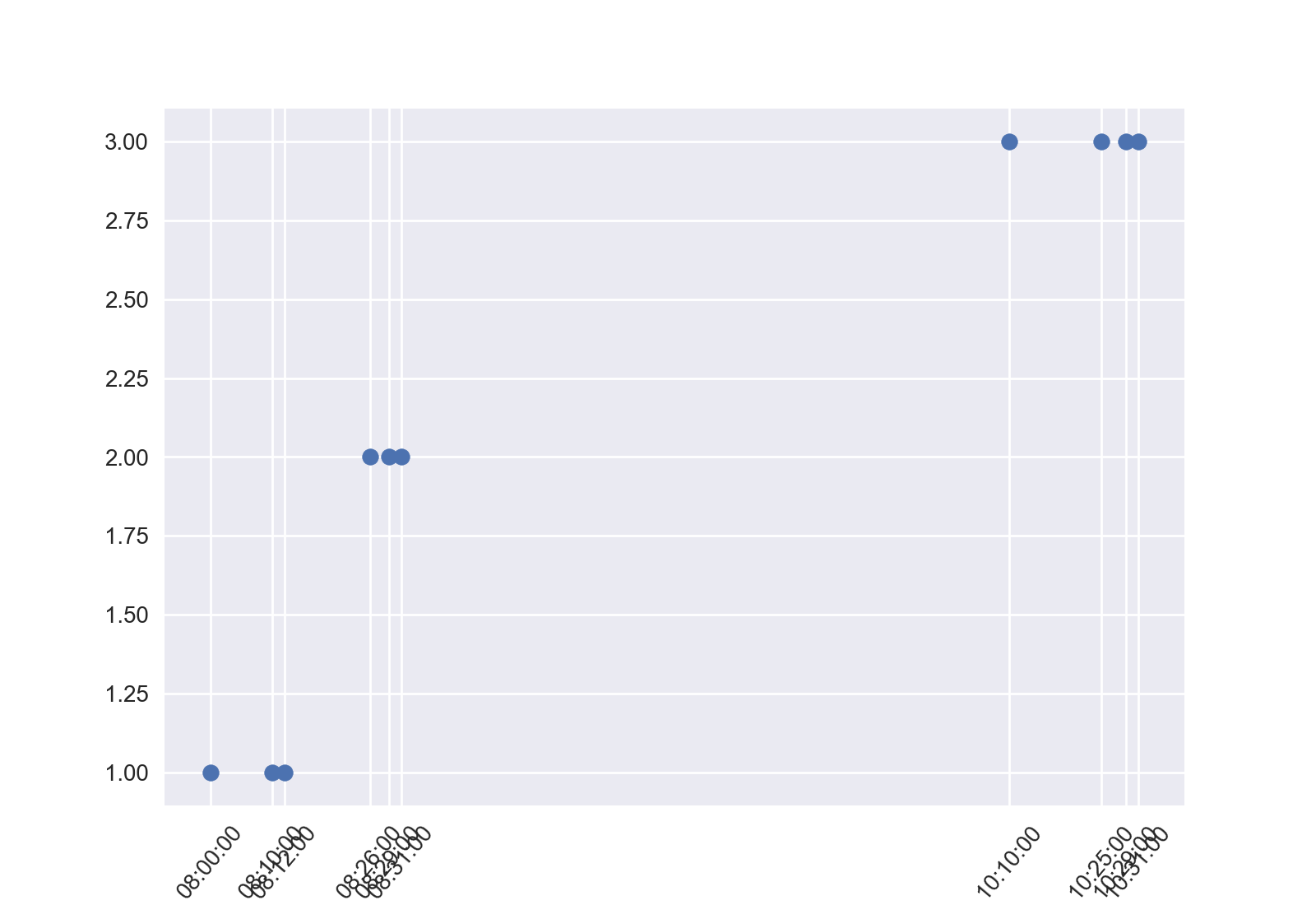
回答 2
Stack Overflow用户
发布于 2018-07-03 01:10:05
让我们使用一些xticklabel操作:
d = ({
'A' : ['08:00:00','08:10:00','08:12:00','08:26:00','08:29:00','08:31:00','10:10:00','10:25:00','10:29:00','10:31:00'],
'B' : ['1','1','1','2','2','2','7','7','7','7'],
'C' : ['X','Y','Z','X','Y','Z','A','X','Y','Z'],
})
df = pd.DataFrame(data=d)
fig,ax = plt.subplots()
x = df['A']
y = df['B']
x_numbers = (pd.to_timedelta(df['A']).dt.total_seconds())
plt.scatter(x_numbers, y)
loc, labels = plt.xticks()
newlabels = [str(pd.Timedelta(str(i)+ ' seconds')).split()[2] for i in loc]
plt.xticks(loc, newlabels)
plt.show()输出:
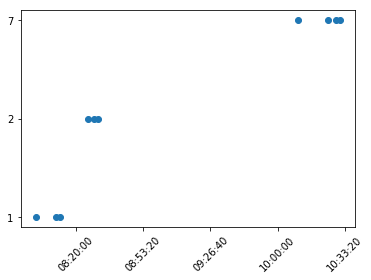
Stack Overflow用户
发布于 2018-06-28 01:05:46
首先,时间间隔不一致。其次,这是一个高频系列.
在一般情况下,不需要匹配每个条目对应的xticks。而且,在这些场景中,您可以利用类似于plt.plot_date(x, y)的东西--包括滴答locators和formatters like、DayLocator()和DateFormatter('%Y-%m-%d')。
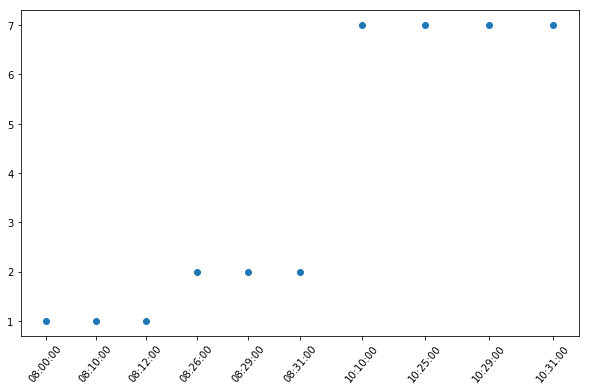
尽管在这个非常特殊的情况下,数据处于极小的水平,而且很少点是非常接近的,但黑客可能会尝试使用您为x轴,x_numbers使用的数字系列。为了扩大两点之间的差距,我尝试了cumsum()并在一定程度上消除了重叠,给了xticks一些rotation。
fig, ax = plt.subplots(figsize=(10,6))
x = df['A']
y = df['B']
x_numbers = (pd.to_timedelta(df['A']).dt.total_seconds()).cumsum()
plt.scatter(x_numbers, y)
plt.xticks(x_numbers, x, rotation=50)
plt.show()
https://stackoverflow.com/questions/51073053
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号