
如何检测和过滤时间序列数据的峰值?
如何检测和过滤时间序列数据的峰值?
提问于 2018-06-25 15:50:53
我有一个熊猫的用户登录数据,如下所示:
id datetime_login
646 2017-03-15 15:30:25
611 2017-04-14 11:38:30
611 2017-05-15 08:49:01
651 2017-03-15 15:30:25
611 2017-03-15 15:30:25
652 2017-03-08 14:03:56
652 2017-03-08 14:03:56
652 2017-03-15 15:30:25
654 2017-03-15 15:30:25
649 2017-03-15 15:30:25
902 2017-09-09 15:00:00
902 2017-02-13 16:39:53
902 2017-11-15 12:00:00
902 2017-11-15 12:00:00
902 2017-09-09 15:00:00
902 2017-05-15 08:48:47
902 2017-11-15 12:00:00在策划登录后:
df.datetime_login = df.datetime_login.apply(lambda x: str(x)[:10])
df.datetime_login = df.datetime_login.apply(lambda x: date(int(x[:4]), int(x[5:7]), int(x[8:10])))
fig, ax = subplots()
df.datetime_login.value_counts().sort_index().plot(figsize=(25,10), colormap='jet',fontsize=20)- 如何在我的绘图中检测出时间序列数据中的峰值?
- 如何将时间序列数据中的峰值过滤到数组中?
我试着:
import peakutils
indices = peakutils.indexes(df, thres=0.4, min_dist=1000)
print(indices) 然而,我得到了:
TypeError: unsupported operand type(s) for -: 'datetime.date' and 'int'然而,我得到了:
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-06-25 20:48:36
其中df.datetime_login.value_counts().sort_index().plot(figsize=(25,10), colormap='jet',fontsize=20)情节:
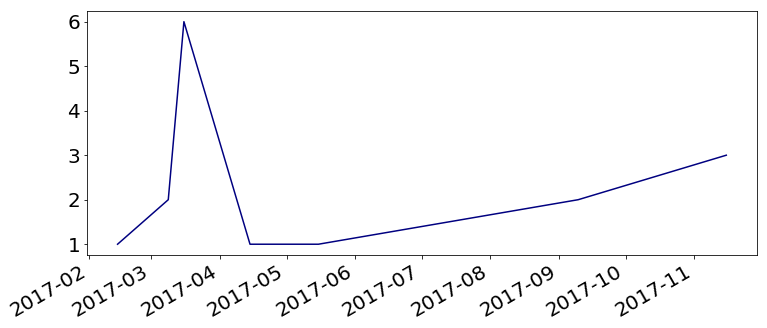
让我们尝试下面的方法,您需要使用value_counts返回的系列,而不是原始的df,peakutils.indexes
df_counts = df.datetime_login.value_counts().sort_index()
df_counts[peakutils.indexes(df_counts, thres=0.4, min_dist=1000)]输出:
2017-03-15 15:30:25 6
Name: datetime_login, dtype: int64页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51027435
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号