
图数据库中的层次属性
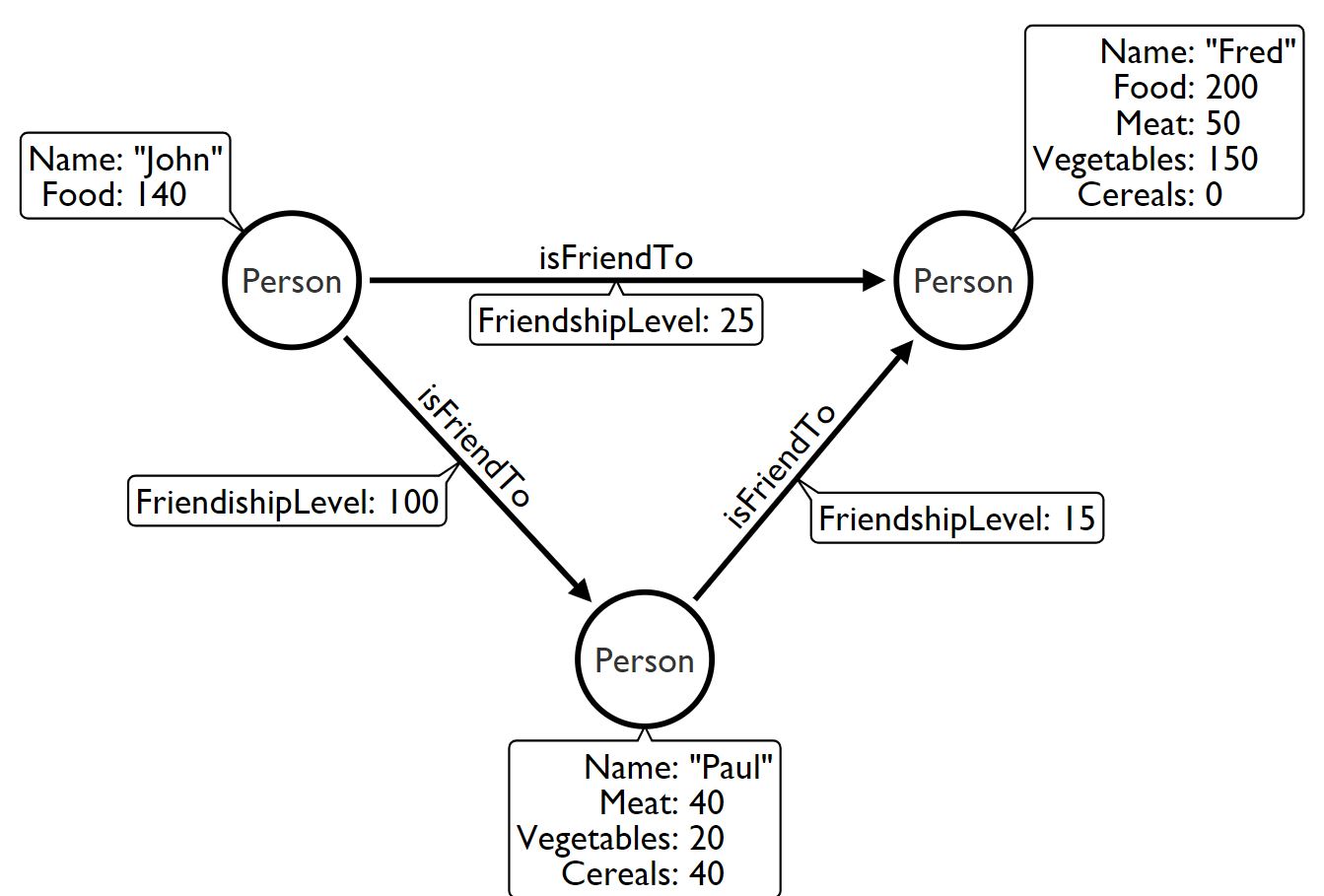
我开始使用neo4j了。在我的图形数据库中,我有节点Person (请看下面的"John“),标签是:Name (字符串),Food (正整数)。每个Person通过关系isFriendTo与其他Person连接,关系isFriendTo有一个值。我只使用图DB来寻找两个人之间最短的加权路径。
而且,每天我检查图中的每个节点,如果食物低于100,我会采取一些行动。
现在,经过一些改进之后,属性Food对于我的项目来说已经不够了。因此,我必须将它除以另外三个更具体的属性(正整数):Vegetables、Meat和Cereals。如果两者之和都小于100,我必须采取与以前相同的行动。我以前的处境是“约翰”,我唯一能做出的选择就是“弗雷德”或“保罗”?
我能用哪种方式设计这个?除了neo4j之外,我还应该使用类似于MongoDB的东西来表示层次结构吗?
删除财产食品和添加三个新的属性似乎是一个不好的做法,对我。我得把这3的意思说成是“食物”.如果将来我会添加其他类型的食物,那又会怎样呢?我把要检查的值100必须来自Meat、Vegetables和Cereals之和的知识存储在哪里?有这样的东西,可以解决我的疑问,因为我可以把food中的所有项目加在一起
{
"name": "Lucas",
"food": {
"meat": 40,
"vegetables": 30,
"cereals": 0
}
}(我不需要遍历从Food和Vegetables到Person的连接。只需要检查一下肉的总和,维格。而谷类则小于或大于100。
回答 2
Stack Overflow用户
发布于 2018-06-25 22:01:45
根据您的图表,Person似乎是所有节点共享的标签,而Name/Food//Meat/Vegetables/Cererals似乎是节点属性的名称。
如果我的理解是正确的,那么有许多方法来处理多种食物类型的数量,并得到一个人的总数。下面是几个例子。
- 这里有一种方法。您可以为
Food食品类型节点引入独一无二标签: (:食品{类型:‘肉’}),(食品{类型:‘蔬菜’})等等。 并且每个Person节点可以与每个相关的Food节点(而不是在内部存储食物类型属性)有一个HAS_FOOD关系(具有amount属性): (john:Person {Name:'John'})-:HAS_FOOD {->:140}->(肉类:食品{type:‘肉类’}) 使用此数据模型,可以找到所有含有100多个单元食物的Person: 匹配(p:Person)-r:HAS_FOOD->()与p,SUM(r.amount)为总计> 100返回p; - 这是另一种方法(可能会导致更快的搜索)。由于neo4j属性不能具有映射值(与问题底部的JSON中显示的相反),因此每个
Person节点都可以有amount和food数组,如下所示: (姓名:弗雷德,数量: 50,100,食物:“肉”,“蔬菜”}) 使用此数据模型,可以找到所有含有100多个单元食物的Person: 匹配(p:Person),其中减(s= 0,a IN p.amount x s+ a) > 100返回p; 更新 然而,使用第二种方法进行食品加工(这里是很好的双关语)可能会更麻烦,效率更低。例如,这是获取Fred肉类数量的一种方法: MATCH (p:Person {Name:'Fred'})返回I IN范围(0,大小(p.food)-1),其中p.food[i] = 'Meat‘{ p.amount[i]作为meatAmt; 并且,将Fred的肉类数量设置为123: MATCH (p:Person {Name:'Fred'})设置p.amount = [i IN RANGE(0,SIZE(p.food)-1) = p.foodi = 'Meat‘然后123 p.amounti]; - 所以,这是第三种方法,它解决了你的问题,对食品加工来说要好得多。每个人节点都可以将食物量直接存储为属性,如下所示:
(姓名:'Fred',肉类: 50,蔬菜: 100,foodNames:‘肉类’,‘蔬菜’})
使用此数据模型,
foodNames数组允许您按名称迭代食物属性。因此,要找到所有拥有100多个食物单位的人: 匹配(p:Person),其中减(s= 0,n IN p.foodNames \s+ pn) > 100返回p; 另外,要获得Fred的肉类数量: MATCH (p:Person {Name:'Fred'})返回p.Meat作为meatAmt; 要将Fred的肉类数量设置为123,请执行以下操作: MATCH (p:Person {Name:'Fred'})设置p.Meat = 123;
Stack Overflow用户
发布于 2018-06-25 13:52:11
在Neo4j上,标签就像标签,没有技术层次,一个节点可以有很多标签。
但是,如果您想从业务角度说Food是Vegetables、Meat和Cereals的父级,那么就没有问题了。您将有一个业务/语义层次结构。
因此,在我的POV中,我只在节点上添加带有Food标签的新标签。
https://stackoverflow.com/questions/51023869
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号